
協(xié)方差矩陣的計算是信號處理領(lǐng)域的典型運算,是實現(xiàn)多級嵌套維納濾波器、空間譜估計、相干源個數(shù)估計以及仿射不變量模式識別的關(guān)鍵部分,廣泛應用于雷達、聲吶、數(shù)字圖像處理等領(lǐng)域。采用FPGA(Field Programmable Gate Array)可以提高該類數(shù)字信號處理運算的實時性,是算法工程化的重要環(huán)節(jié)。但是FPGA不適宜對浮點數(shù)的處理,對復雜的不規(guī)則計算開發(fā)起來也比較困難。故目前國內(nèi)外協(xié)方差運算的FPGA實現(xiàn)都是采用定點運算方式。
在所有運算都是定點運算的情況下,每次乘法之后數(shù)據(jù)位寬都要擴大一倍。若相乘后的數(shù)據(jù)繼續(xù)做加減運算,為了保證數(shù)據(jù)不溢出,還必須將數(shù)據(jù)位寬擴展一位,而協(xié)方差矩陣的運算核心就是乘累加單元,隨著采樣點數(shù)的增加,位寬擴展呈線性增加。最終導致FPGA器件資源枯竭,無法實現(xiàn)設(shè)計。為了保證算法的實現(xiàn),必須對中間運算數(shù)據(jù)進行截斷,將每次累加的結(jié)果除2(可以通過移位運算來實現(xiàn)),以避免溢出。
此外,在應用MUSIC算法時,各種計算都是復數(shù)運算。為達到減少算法的計算量,提高MUSIC算法處理速度的目的,許多文獻致力于研究陣列的結(jié)構(gòu)特點,在保證測角精度的前提下,尋找一種簡單而有效的數(shù)據(jù)預處理方法,將復數(shù)矩陣轉(zhuǎn)化為實數(shù)矩陣,把復矢量用一個實矢量來代替,從而將復數(shù)運算轉(zhuǎn)化為實數(shù)運算。
接收陣元模型可分為任意離散陣、均勻圓弧陣、均勻圓陣和均勻線陣。在實際應用中,比較常見的是均勻線陣和均勻圓陣。每種陣列模型都有各自的特點,加之陣元數(shù)目的取值不同,也會導致陣列流型的對稱性變化。針對不同的陣元模型和陣元數(shù),數(shù)據(jù)預處理的方法也會有所不同。
對于數(shù)據(jù)預處理的研究,目前已經(jīng)有了一些比較成熟的算法。對于一個偶數(shù)陣元的對稱陣列(包括均勻線陣和均勻圓陣),相關(guān)研究表明,可利用其對稱性,分成兩個完全對稱的子陣,選擇合適的參考點,構(gòu)造互為共軛對稱的方向矩陣,進而構(gòu)造一個線性變換矩陣,即可達到將復數(shù)矩陣轉(zhuǎn)化為實數(shù)矩陣的目的。
對于奇數(shù)陣元的均勻線陣,也有相關(guān)研究成果表明,通過構(gòu)造一個酉矩陣,也可以達到數(shù)據(jù)預處理的目的。
由于均勻圓陣的陣列流型矩陣不是Vandermonde矩陣,即不具備旋轉(zhuǎn)不變性,因此適用于奇數(shù)陣元的均勻線陣的預處理理論不能直接用于奇數(shù)陣元的均勻圓陣,需要將圓陣先轉(zhuǎn)換到模式空間——虛擬線陣,而轉(zhuǎn)換需要第一類Bessel函數(shù),不適宜用硬件實現(xiàn)。
以上研究表明,目前除了奇數(shù)陣元的均勻圓陣外,其他常用陣列模型都可以通過預處理的方法將復數(shù)運算轉(zhuǎn)換為實數(shù)運算。若在某些特定的情況下,必須采用奇數(shù)陣元的均勻圓陣。此時,基于復數(shù)運算的協(xié)方差矩陣的實現(xiàn)就成為一種必然。
因此,在充分應用FPGA并行處理能力的同時,為了擴展數(shù)據(jù)處理的動態(tài)范圍,減少數(shù)據(jù)溢出機率,避免數(shù)據(jù)截斷所產(chǎn)生的誤差,提高協(xié)方差矩陣的運算精度以及擴展該運算的通用性。本文以空間譜估計作為研究背景,研究了復數(shù)據(jù)運算和浮點運算的特點,提出了一種適用于任何陣列流型、任意陣元的基于復數(shù)浮點運算的協(xié)方差矩陣的FPGA實現(xiàn)方案。
關(guān)鍵字:FPGA 協(xié)方差矩陣 復數(shù)浮點 FIFO 信號處理
1 求解復數(shù)浮點協(xié)方差矩陣
以11陣元的均勻圓陣為例,其協(xié)方差矩陣的求解方案原理框圖如圖1所示。
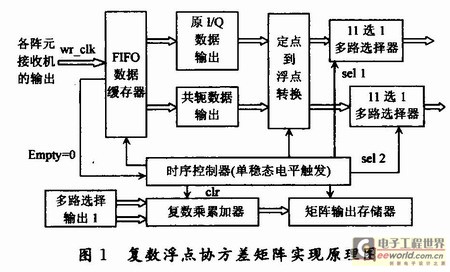
1.1 FIFO數(shù)據(jù)緩存器
在該設(shè)計方案中選擇FIFO作為數(shù)據(jù)存儲器,這是因為一旦多路接收機有數(shù)據(jù)輸出,就會啟動FIFO進行存儲,進而FIFO的不空信號有效(empty=O),觸發(fā)后續(xù)的矩陣運算;否則,運算停止,一切狀態(tài)清零,F(xiàn)PGA恢復idle(空閑)狀態(tài),等待新的快拍采樣數(shù)據(jù)的到來。
這樣可以很方便地控制運算的開始和結(jié)束。矩陣運算所需要的同步時鐘需要設(shè)計一個類似于單穩(wěn)態(tài)觸發(fā)器的模塊。當檢測到empty=‘0’時,就觸發(fā)一個含有121個clk(對于串行方案而言)時鐘信號周期長度的高電平。該高電平與主時鐘相與便可以得到運算的同步時鐘。
1.2 數(shù)據(jù)共軛轉(zhuǎn)換
由于測向陣列的輸出矢量X(t)是一個復矢量,對其求協(xié)方差矩陣需用陣列輸出列矢量X(t)與其共軛轉(zhuǎn)置矢量XH(n)對應相乘。如式(1)所示:
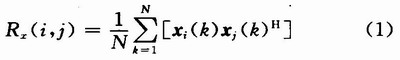
1.3 定點數(shù)到浮點數(shù)的轉(zhuǎn)換
定點計算在硬件上實現(xiàn)簡單,計算速度比浮點計算要快,但是表示操作數(shù)的動態(tài)范圍受到限制,浮點數(shù)計算硬件實現(xiàn)比較困難;一次計算花費的時間也遠大于定點計算的花費,但是其表示的操作數(shù)動態(tài)范圍大,精度高。在本設(shè)計中,考慮到系統(tǒng)的數(shù)據(jù)動態(tài)范圍和運算精度,選擇浮點計算。由于運算數(shù)據(jù)是直接從接收機I,Q兩路通道的A/D變換器的輸出獲得,為定點數(shù),因此必須要有一個將A/D采樣的定點數(shù)據(jù)轉(zhuǎn)換為浮點數(shù)的過程。設(shè)計中將16位定點數(shù)轉(zhuǎn)換為IEEE 754標準的單精度格式。32位單精度格式如圖2所示,最高位為符號位,其后8位為指數(shù)e(用移碼表示,基數(shù)f=2,偏移量為127),余下的23位為尾數(shù)m。
關(guān)鍵字:FPGA 協(xié)方差矩陣 復數(shù)浮點 FIFO 信號處理
1.4 浮點復數(shù)乘累加器
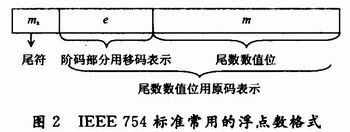
1.4.1 復數(shù)乘法器
假設(shè)有兩個復數(shù)分別為a+jb和c+jd,這兩個數(shù)的乘積為:
![]()
復數(shù)乘法器的工作原理如圖3所示,其中所用到的加法、減法和乘法器都是基于浮點的運算。值得一提的是,在實現(xiàn)浮點加減法的時候,可以將尾數(shù)連同符號位轉(zhuǎn)化為變形補碼形式后再進行加減運算。這樣做的目的是方便判斷數(shù)據(jù)是否溢出(變形補碼判斷溢出的規(guī)則是:當兩位符號位不同時表示溢出,否則無溢出。無論數(shù)據(jù)是否溢出,第一位符號位永遠代表真正的符號),若溢出,則將尾數(shù)右歸,指數(shù)部分加1,若沒有溢出,則將尾數(shù)左歸(規(guī)格化)。浮點乘法相對較簡單,對應階碼相加,尾數(shù)相乘可以采用定點小數(shù)的任何一種乘法運算來完成,只是在限定只取一倍字長時,乘積的若干低位將會丟失,引入誤差。
1.4.2 浮點復數(shù)乘累加器
以11個陣元的圓陣為例,實現(xiàn)串行處理方案的浮點復數(shù)乘累加器的原理如圖4所示,實部和虛部(雙通道)的乘累加器模塊工作原理一樣。
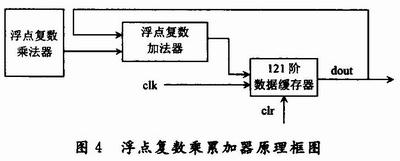
121階數(shù)據(jù)緩存器實際上就是121個數(shù)據(jù)鎖存器級聯(lián)形成的一個移位寄存器,初始狀態(tài)為零。當浮點復數(shù)乘法器有輸出的時候,啟動數(shù)據(jù)緩存器與之進行加法操作,121個時鐘周期以后可以實現(xiàn)一次快拍采樣的矩陣累加。累加清零信號由時序控制器給出,當所有的快拍采樣點運算都結(jié)束之后,數(shù)據(jù)緩存器輸出累加結(jié)果(即協(xié)方差矩陣的運算結(jié)果),同時控制器送出一個清零信號,清零121階數(shù)據(jù)緩存器。
關(guān)鍵字:FPGA 協(xié)方差矩陣 復數(shù)浮點 FIFO 信號處理
2 仿真結(jié)果
可編程邏輯設(shè)計有許多內(nèi)在規(guī)律可循,其中一項就是面積和速度的平衡與互換原則。面積和速度是一對對立統(tǒng)一的矛盾體,要求一個設(shè)計同時具備設(shè)計面積最小,運行頻率最高,這是不現(xiàn)實的。于是基于面積優(yōu)先原則和速度優(yōu)先原則,本文分別設(shè)計了協(xié)方差矩陣的串行處理方案和并行處理方案,并用Altera\stratix\EP1S20F780C7進行板上調(diào)試。其調(diào)試結(jié)果表明,串行處理方案占用的資源是并行處理方案的1/4,但其運算速度卻是后者的11倍。
2.1 串行處理方案仿真結(jié)果
如圖5所示,clk為運算的總控制時鐘;reset為復位控制信號,高電平有效;rd為讀使能信號,低電平有效;wr為寫使能信號,低電平有效;wr_clk為寫時鐘信號,上升沿觸發(fā);q_clk為讀時鐘信號,上升沿觸發(fā);ab_re(31:O)和ab_im(31:O)為乘法器輸出的實部和虛部。q_t2為矩陣乘累加模塊的同步時鐘信號;clkll,state(3:O),clkl和state(3:0)是狀態(tài)機的控制信號,控制矩陣運算規(guī)則。
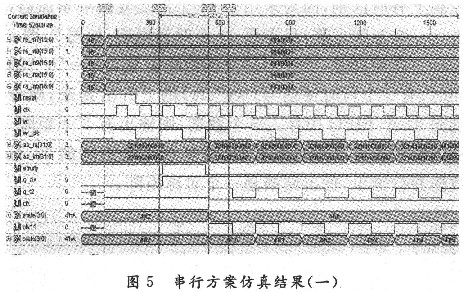
如圖5所示,在100 ns時reset信號有效(即reset=‘1’),所有狀態(tài)清零。從335~635 ns間,寫使能信號有效(wr=‘O’)且有兩個寫時鐘信號的上升沿到來,即向任意一個通道的FIFO中存入兩個快拍采樣數(shù)據(jù),最后輸出結(jié)果應該有兩個矩陣,如圖6所示。當FIFO為空時,運算停止,所有狀態(tài)清零。等待新采樣數(shù)據(jù)的到來。
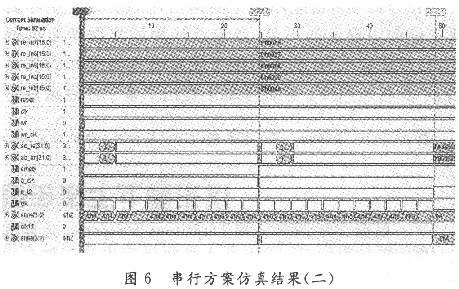
圖5中,在350 ns時,讀使能有效(rd=‘0’)且有一個讀時鐘信號的上升沿到來,所以empty信號存在短暫的不空(empty=‘O’)狀態(tài),捕獲到這個信息,便觸發(fā)單穩(wěn)態(tài)觸發(fā)器模塊,產(chǎn)生具有121個clk時鐘周期長度,占空比為120:1的q_clk信號,進行FIFO的讀操作。
在350~535 ns時間段,因為寫時鐘信號沒有到來,所以FIFO為空(empty=‘1’)。從550 ns~24.75 μs時間段讀時鐘信號沒有上升沿到來,整個設(shè)計處于第一個矩陣的運算過程中,即運算一個矩陣所需要的時間為24.2 μs。與此同時,第二個數(shù)據(jù)寫入FIFO,empty一直處于不空狀態(tài)(empty=‘O’)。
在第一個矩陣運算結(jié)束之后,即24.6μs時,系統(tǒng)檢測到empty=‘0’,開始讀數(shù)據(jù)并觸發(fā)第二個矩陣運算的時鐘控制信號。如圖6所示,在24.6μs時,empty=‘1’。FIFO中的第二個數(shù)據(jù)被讀出,處于空狀態(tài)。從24.85~49.05μs進入第二個矩陣的運算周期。
在仿真時,輸人數(shù)據(jù)為16位的定點數(shù)(1+j1;O+jO;2+j2;3+j3;4+j4;5+j5,6+j6;7+j7;8+j8;9+j9;A+jA),輸出結(jié)果為32位的單精度浮點數(shù)。選擇的主時鐘周期為200 ns。在實際調(diào)試過程中,整個系統(tǒng)可以在50 MHz主時鐘頻率下正常工作。
關(guān)鍵字:FPGA 協(xié)方差矩陣 復數(shù)浮點 FIFO 信號處理
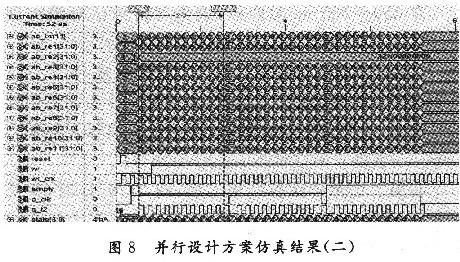
2.2 并行處理方案仿真結(jié)果
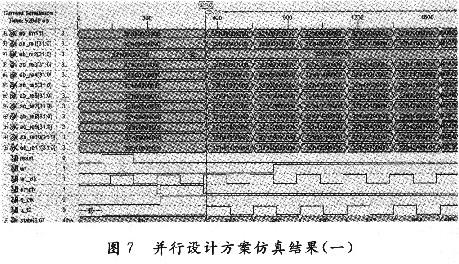
并行方案運算原理與串行方案的一樣,只是在時鐘控制上有所區(qū)別,因為采用了11個浮點復數(shù)乘累加器,進行一次矩陣運算,只需要11個時鐘周期,如圖7,圖8所示。在仿真時,設(shè)置在寫使能信號有效(wr=‘O’)的同時,有3個寫時鐘信號(wr_clk)的上升沿到來,即分別向22個FIF0中存入3個數(shù)據(jù),則輸出有3個矩陣。從圖7中還可以清楚地看出,運算結(jié)果是矩陣的11行數(shù)據(jù)并行輸出,輸出結(jié)果是一個對稱矩陣。
3 結(jié)語
在分析了目前應用于空間譜估計的協(xié)方差矩陣運算在硬件實現(xiàn)上的不足,如定點計算的數(shù)據(jù)動態(tài)范圍小,運算精度不高,且只適用于特定陣列模型和的陣元數(shù),不具備通用性。在此基礎(chǔ)上提出了基于浮點運算的通用型協(xié)方差矩陣的實現(xiàn)方案。仿真結(jié)果表明,本文所提出的實現(xiàn)方案采用的是復數(shù)乘法運算,最終結(jié)果得到的是復共軛對稱矩陣,適合利用任意的陣列模型和陣元數(shù)得到與之相對應的協(xié)方差矩陣。這就拓展了協(xié)方差矩陣運算的應用范圍,且整個運算過程采用的是浮點運算,提高了整個運算的精度。