
摘 要: 目前,基于PC或DSP的系統(tǒng)其處理能力無法滿足海量語音信號高速處理需求的增長。本文分析了VQ(矢量量化)搜索算法的硬件實現(xiàn)復雜度,針對說話人識別過程中運算量最大、耗時最長的判決過程,提出了一種基于標簽的說話人判決模型實現(xiàn)方案。該設計用FPGA實現(xiàn),可對多路電話信道說話人進行實時判決識別。
關(guān)鍵詞: 說話人識別;VQ;標簽;多路;FPGA
說話人識別和指紋識別、虹膜識別一樣,屬于生物識別技術(shù)的一種[1],是通過從語音信號中提取說話人信息來鑒別說話人身份的技術(shù)。與其他生物識別技術(shù)相比,說話人識別具有更為簡便、自然、準確、經(jīng)濟及可擴展性好等眾多優(yōu)勢。與語音識別不同,說話人識別不考慮語音中的字詞意思,強調(diào)說話人的個性。
說話人識別由訓練和識別兩個階段構(gòu)成,圖1為一個典型的說話人識別系統(tǒng)結(jié)構(gòu)框圖。其中特征提取單元從輸入語音中提取出能夠反映說話人特征的參數(shù);在訓練階段,用合適的模型來表征這些特征參數(shù),使得模型能夠代表該說話人的語音特性,這一階段一般離線運行;在識別階段,用已經(jīng)建立的參考模型對測試語音的特征參數(shù)按一定的相似性測度和判決規(guī)則進行模式匹配,把相似性得分最高者作為識別結(jié)果。

基于成本和靈活性方面的考慮,當前大部分說話人識別系統(tǒng)都是基于計算機軟件或DSP來構(gòu)建的。但對于一些大型應用,如企業(yè)的客服中心,為提高服務質(zhì)量和效率,希望自動識別客戶身份;公安部門為調(diào)查取證,需要對多路電話進行實時監(jiān)控或?qū)A夸浺綦娫掃M行高速處理。對于這些基于電信網(wǎng)的大容量、實時性要求比較高的應用,基于PC或DSP的系統(tǒng)其處理能力越來越不能滿足需求的增長。本文針對基于PC或DSP的系統(tǒng)在識別階段實時性較差的問題,提出了一種基于VQ模型的硬件判決實現(xiàn)結(jié)構(gòu),并用FPGA實現(xiàn)。
1 VQ模型原理及算法復雜度分析
1.1 VQ模型原理
基于VQ[2]方法的說話人識別系統(tǒng)在訓練階段把每個人的訓練語音數(shù)據(jù)通過標準的聚類過程生成碼本C,假設有S個目標說話人,則需要建立S個碼本。在選定了失真測度和初始碼本后,通常采用LBG[3]算法生成碼本。識別時將測試輸入語音矢量按此碼本進行編碼,以量化產(chǎn)生的失真作為判決標準。L幀測試語音矢量{xt},t=1,2,…,L的模板匹配得分z為[4]:

其中,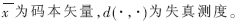 測試是以最小匹配得分作為測試語音和模型相似程度的判定依據(jù)。
測試是以最小匹配得分作為測試語音和模型相似程度的判定依據(jù)。
采用VQ模型識別過程并不需要進行時間對齊,從而大大減少了系統(tǒng)的復雜度。對于文本無關(guān)的說話人識別,其識別率較高,且判斷速度快,對于計算量化失真的搜索過程,目前硬件實現(xiàn)通常采用全搜索算法。
失真測度采用歐式失真,即均方誤差,特點是易于硬件處理,且符合語音主觀感知的條件,與系統(tǒng)所采用的MFCC參數(shù)相匹配(若采用LPC則不適宜用歐式失真)[5]。
1.2 算法適應性修改及運算復雜度分析
1.2.1 算法適應性修改
設碼本為C={c0,c1,c2,…,cN-1},其中每個碼矢為k維矢量,特征參數(shù)x也是k維矢量。在歐氏失真的條件下,特征參數(shù)x對碼矢c的失真計算如下式:
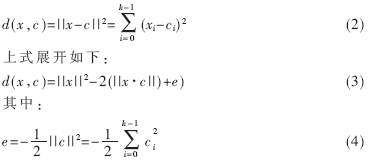
其中e是和碼矢相關(guān)的固定值,在離線生成碼本時計算出來,并作為碼本的一部分。由上面的分析可知,求最小距離相當于最大化||x·c||。因此,一幀測試矢量對一個碼本的最小距離的搜索過程可等價地描述為矩陣-矢量相乘,即下式:

式中:C為N行k列碼本矩陣,x為測試矢量,e為由各碼矢的e值組成的列向量。
對于一個碼本來講,每一幀參數(shù)的量化誤差為:
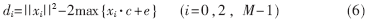
在進行說話人識別時,假設需要M幀測試矢量,則需比較每個碼本對這M幀參數(shù)的得分,即各幀的量化誤差的累加和。對一個說話人來講,M值對每個碼本都是固定的,因此只需計算max{xi·c+e}的累加和即可,識別過程也由搜索最小值轉(zhuǎn)化為搜索最大值。
根據(jù)上面分析可知,測試矢量和碼字矢量之間的距離可以通過計算它們之間的內(nèi)積來實現(xiàn),而不必用先相減再平方的方式。對硬件實現(xiàn)來講,每次求距離的過程將減少k次減法的運算量,可帶來面積和時序上的優(yōu)化。
1.2.2 運算復雜度分析
假設碼本數(shù)為S,碼本容量為N,碼字為k維矢量,下面對運算復雜度進行分析。
由前面的分析可知,一幀測試矢量對一個碼矢的距離計算量為K次乘法,K-1次加法,再加上e,共K次乘加操作,則一幀測試矢量對一個碼本(N個碼矢)完成失真計算的運算量:N×k次乘累加,N-1次比較。
計算M幀測試矢量對一個碼本的距離,共需要:(M×K×k)次乘加,(M×N-1)次比較,另加(M-1)次加操作(完成M個誤差的累加)。
對于有S個說話人(S個碼本)的系統(tǒng),定義其VQ搜索復雜度為f,即完成一次說話人判決所需的主要運算量,這里只取乘加運算,則:
f=S×M×N×k (7)
例如,在本文中,目標說話人S=64,碼本容量N取64,k取24維,完成一次識別的典型M值為1 024,共需要:f=64×1 024×64×24=100 663 296次乘加運算。
VQ識別時其運算復雜度與上面4個參數(shù)成線性關(guān)系,對于碼本來講,其存儲復雜度與S、N、k這3個參數(shù)成線性關(guān)系。
2 硬件實現(xiàn)結(jié)構(gòu)
2.1 功能描述
系統(tǒng)采用24維MFCC參數(shù)(12維MFCC及12維ΔMFCC),數(shù)據(jù)位寬為32位。因為整個系統(tǒng)的典型應用為多路電話信道(如E1信道),可完成多路電話語音的同時處理。為了區(qū)分當前參數(shù)屬于哪一話路,采用的方式是給每一幀參數(shù)前加上一個標簽,也是32位寬,內(nèi)容包括話路號及格式信息,這都由系統(tǒng)前端處理完成。因此VQ判決模塊的實際輸入數(shù)據(jù)可視為25維參數(shù),以FIFO為接口串行輸入。輸入幀格式如圖2。

當某一話路滿足判決條件,即輸入了足夠的參數(shù)(如設定1 024幀)時,判決模塊將進行判決。判決完成后輸出結(jié)果有效信號,持續(xù)若干個時鐘周期,使外部系統(tǒng)讀出判決結(jié)果。輸出的判決結(jié)果為32位,高16位為話路號,低16位為碼本號,以告知外部控制系統(tǒng)當前輸入中哪一路話出現(xiàn)了哪個說話人。
為了進行實時判決,需要在下一幀測試矢量的最后一個數(shù)據(jù)到來之前完成當前幀的量化工作,即計算出當前幀與每個碼本的距離,實現(xiàn)高速的核心是使用并行乘法。這里的“實時”是指從測試數(shù)據(jù)輸入到判決結(jié)果輸出的過程,只有算法上的延遲,無需在前面存儲測試數(shù)據(jù)。
2.2 實現(xiàn)結(jié)構(gòu)及模塊劃分
圖3為VQ判決模塊的內(nèi)部結(jié)構(gòu)框圖,給出了主要的控制信號和數(shù)據(jù)。其中包括兩個接口,一個測試數(shù)據(jù)輸入接口,一個讀碼本接口,測試數(shù)據(jù)通過FIFO輸入,碼本存儲于外部RAM。整個架構(gòu)從功能上可分為接口部分、控制部分和運算部分。下面具體介紹各子模塊功能,同時說明整個模塊的工作流程。
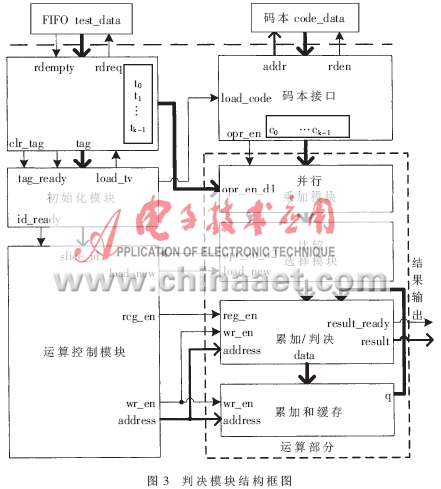
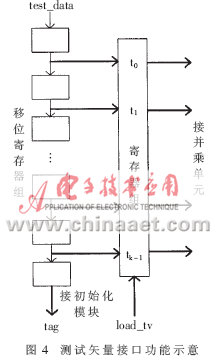
2.2.1 測試矢量接口
根據(jù)FIFO的空標志rdempty,產(chǎn)生讀請求信號rdreq,讀到的數(shù)據(jù)首先進入一個24級移位寄存器,并對讀進行計數(shù)。計數(shù)值滿24后,發(fā)出tag_ready使能,在下一時鐘上升沿輸出tag至初始化模塊。第25個數(shù)讀進來后,clr_tag有效。該模塊接收來自初始化模塊的load_tv使能信號,持續(xù)一個時鐘周期,若load_tv有效,在上升沿時將移位寄存器組的數(shù)據(jù)讀入寄存器組,實現(xiàn)串并轉(zhuǎn)換,將測試矢量送至并行乘單元。功能示意如圖4。
2.2.2 碼本接口
收到初始化模塊的load_code信號后,開始產(chǎn)生地址和讀信號,按順序讀出碼本數(shù)據(jù)。內(nèi)部也有移位寄存器組和數(shù)據(jù)寄存器組,實現(xiàn)串并轉(zhuǎn)換,同圖4所示結(jié)構(gòu)相似。讀滿一幀24個數(shù)之后,產(chǎn)生opr_en使能,在下一時鐘沿把數(shù)據(jù)加載到寄存器組,并行乘法也將在opr_en有效后的第一個時鐘沿開始。opr_en作為基本的使能信號,同時提供給下一級的并行乘加模塊和運算控制模塊。
2.2.3 初始化子模塊
初始化狀態(tài)機如圖5所示,分為空閑、初始化和循環(huán)三個狀態(tài)。根據(jù)讀入的標簽數(shù)據(jù)tag,判斷該幀測試數(shù)據(jù)是否有效,從而決定是否開始運算過程。當接收的clr_tag有效時,表示該幀的最后一個數(shù)據(jù)已經(jīng)進入移位寄存器,此時判斷tag是否有效。若有效,則提取tag中的話路號,輸出至運算控制模塊,同時使load_tv、load_code兩個信號有效。load_tv為加載測試矢量使能,load_code為加載碼本使能。

2.2.4 運算控制模塊
對于時分復用的多路電話信道,控制模塊首先要根據(jù)標簽對輸入的測試矢量完成分路計數(shù)的功能。當id_re-ady有效時,讀入話路號slice_id,進行幀計數(shù),對應到說話人識別系統(tǒng)前端,就是對輸入話音進行計時。計數(shù)結(jié)果將決定對當前話路是繼續(xù)累加還是進行判決。如果計滿設定的幀數(shù)M,則使判決信號rcg_en為高,輸出至累加/判決子模塊。
運算控制模塊還要為累加和存儲器產(chǎn)生地址和寫請求信號,地址和寫請求也輸入到累加/判決子模塊。地址的產(chǎn)生依賴于話路號slice_id和碼本的個數(shù)S。
2.2.5 并行乘加及比較選擇模塊
并行乘加模塊由24個乘法器構(gòu)成并行乘法陣列,24個乘結(jié)果直接輸出到5級流水式加法器樹,并行乘加結(jié)果為||x·c||+e,在以opr_en為基準進行相應延遲后得到的使能信號的作用下,進行流水輸出。這里的乘法是有符號數(shù)乘法,利用FPGA內(nèi)部的DSP塊實現(xiàn),在用HDL語言描述時,需指明乘法器輸入為有符號數(shù)。并行乘法是提高速度的關(guān)鍵,在一個時鐘周期內(nèi)即可完成24次乘法,結(jié)果直接相加,加法器樹也在使能信號作用下以流水線形式輸出。比較選擇模塊由寄存器和比較器構(gòu)成,與并行乘加單元共同完成量化功能,并暫存量化誤差。
2.2.6 累加/判決模塊及緩存結(jié)構(gòu)
累加/判決模塊及緩存結(jié)構(gòu)是實現(xiàn)分路判決的關(guān)鍵,上面提到的并行乘加和比較選擇模塊實現(xiàn)的是矢量量化的功能,其目的是得到量化誤差,而接下來則需要對量化誤差進行累加,并根據(jù)累加和進行判決。累加和緩存采用以碼本號為橫坐標、以話路號為縱坐標的二維結(jié)構(gòu),這樣做的好處是在進行分路的同時,可以利用地址信息作為判決結(jié)果。圖6以32路話、64個碼本為例,其中坐標為(i,j)的單元格的內(nèi)容為第i路說話人對第j個碼本的距離累加和。

為了防止累加和溢出,該部分緩存利用片內(nèi)RAM實現(xiàn),并采用增加位寬的方式,增加16位,即可提供最多65 536幀的誤差累加而保證無溢出。利用FPGA可相對自由的定義數(shù)據(jù)及存儲格式來處理溢出問題,這是DSP系統(tǒng)無法比擬的優(yōu)勢之一。當判決使能rcg_en為低時,根據(jù)地址值,將到來的數(shù)據(jù)累加到相應的存儲單元;當rcg_en高時,依次讀出該話路所對應的行中每個存儲單元的值,進行比較,同時保存并更新最大值所對應的地址,作為結(jié)果輸出。
3 仿真與綜合結(jié)果
本系統(tǒng)選擇的目標器件為Altera公司的StratixII 系列中的EP2S60F1020C3,配置有36個36×36bit硬件乘法器,能對本設計中的并行乘加結(jié)構(gòu)提供足夠的支持。設計采用Verilog HDL語言描述,利用QuartusII 7.1自帶的綜合工具綜合,用Modelsim6.1進行仿真。圖7為模塊聯(lián)調(diào)時部分信號的仿真波形圖,顯示了初始化完成新一幀開始運算的情況,當加載測試矢量和碼本矢量的使能信號load_tv和load_code有效后,運算開始。其中前面處理單元寫入FIFO的特征參數(shù)為低速數(shù)據(jù),判決模塊在讀滿下一幀之前要處理完當前寄存器中的數(shù)據(jù)。

表1為在32路話、64個碼本、時鐘約束100M的條件下,利用QuartusII進行綜合、布局布線后的主要資源利用率及時序情況。

從資源利用情況來看,因為設計采用了并行乘法,所以消耗最多的是FPGA內(nèi)置的DSP資源,其次是片上RAM資源,主要用于累加和緩存,當話路數(shù)或碼本數(shù)發(fā)生改變時,消耗的RAM資源也會相應變化。整個系統(tǒng)可穩(wěn)定運行于100MHz時鐘,對于一個E1鏈路、64個碼本,完成一幀測試矢量量化誤差計算所需時間為64×64×10=40960ns,遠小于完成一個2M鏈路實時判決所需時間0.5ms(16ms內(nèi)到來32幀測試矢量,即每幀最慢處理時間為0.5ms),留有充足的設計裕量,可擴展性較好。
隨著FPGA技術(shù)的發(fā)展,其在數(shù)字信號處理領(lǐng)域的應用范圍迅速擴大,使得利用FPGA實現(xiàn)復雜算法成為現(xiàn)實。利用VQ原理進行說話人識別,其硬件結(jié)構(gòu)從功能上可分為兩個部分:矢量量化部分和利用量化誤差累加和進行判決的部分。其中矢量量化部分的結(jié)構(gòu)可根據(jù)應用需求和所選器件的資源情況靈活改變。例如,若器件的內(nèi)置DSP塊資源緊張,則可以減少乘法器及加法器的數(shù)量,改為乘累加的形式,用兩個以上時鐘周期完成一次矢量距離運算。本設計中矢量量化部分和多路判決部分是相對獨立的,量化部分結(jié)構(gòu)改變并不影響判決部分;若話路數(shù)或碼本數(shù)發(fā)生變化,則只需對累加和緩存大小進行調(diào)整即可。
目前,本設計已成功應用于多路實時說話人識別系統(tǒng),可滿足至少1個2M鏈路、64個說話人集合的閉集判決,并可根據(jù)實際情況擴展。
參考文獻
[1] 王炳錫.實用語音識別基礎[M].北京:國防工業(yè)出版社,2005.
[2] 吳樂南.數(shù)據(jù)壓縮[M].北京:電子工業(yè)出版社,2000.
[3] LINDE Y,BUZO A,GRAY R M.An Algorithm for Vector Quantizer Design[J].IEEE Transactions on Communications,1980,28(1):84-95.
[4] 王煒.文本無關(guān)的連續(xù)自然語音的說話人識別及基于DSP的實現(xiàn)[D].鄭州:解放軍信息工程大學,2004.
[5] 王炳錫.語音編碼[M].西安:西安電子科技大學出版社,2002:102-104.
[6] [美]PARHI K K著.VLSI數(shù)字信號處理系統(tǒng):設計與實現(xiàn).陳弘毅譯.北京:機械工業(yè)出版社,2004.