
摘 要: 在TI的DSK5402平臺上構(gòu)建了一個主要采用VQ方法的6個說話人識別系統(tǒng)。該系統(tǒng)采用了10階的線性預(yù)測參數(shù)、10階的線性預(yù)測倒譜參數(shù)及基音參數(shù),提出了一種改進(jìn)的LBG算法,以避免在迭代過程中產(chǎn)生空胞腔,使之能適應(yīng)多種距離測量。實驗證明,本系統(tǒng)在指定文本的說話人閉集測試中取得了滿意的效果。
關(guān)鍵詞: 數(shù)字信號處理器;說話人識別;矢量量化;LBG算法
自動說話人識別是一種自動識別說話人的過程,它著眼于提取語音信號中的個人特征,從而達(dá)到識別說話人的目的。說話人識別按是否規(guī)定說話人所說的內(nèi)容可以分為文本有關(guān)型和文本無關(guān)型,前者要求待識別人說指定內(nèi)容的一段話來進(jìn)行識別,而后者對識別人說的內(nèi)容無任何限制[1]。就整個說話人識別的發(fā)展來說,近幾年說話人身份識別在理論和實驗室條件下已經(jīng)達(dá)到比較高的識別精度,并開始走向?qū)嶋H應(yīng)用階段。AT&T、歐洲電信聯(lián)盟、ITT、Keyware、T-NETIX、Motorola和Visa等公司相繼開展了相關(guān)實用化研究,國內(nèi)有關(guān)這方面的研究主要在中科院聲學(xué)所、中科院自動化所、清華大學(xué)等研究所和大學(xué)中進(jìn)行。本文采用VQ方法在TI的DSK5402平臺上構(gòu)建了一個文本有關(guān)的說話人身份識別系統(tǒng),并采用線性預(yù)測語音合成方法來實現(xiàn)語音的人機交互。該系統(tǒng)具有使用方便、識別速度快和成本低等特點,具有廣闊的應(yīng)用前景。
1 算法的設(shè)計
本系統(tǒng)算法的流程如圖1所示。首先將輸入的經(jīng)過數(shù)字化處理的語音信號進(jìn)行預(yù)處理,然后提取其中與說話人有關(guān)的特征參數(shù),接著對參數(shù)進(jìn)行訓(xùn)練,為每個說話人生成一個模板。有了這組模板,在識別的時候,系統(tǒng)將提取新接收的語音的參數(shù),并分別與這些模板進(jìn)行比對,判斷是否與某個模板匹配,最后給出判決結(jié)果。
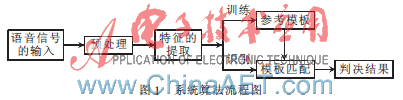
1.1 語音的預(yù)處理
本系統(tǒng)首先對采集到的語音信號進(jìn)行預(yù)處理。這里認(rèn)為待處理的語音是純凈的采樣數(shù)字語音。預(yù)處理主要包括預(yù)加重、分幀和加窗、端點檢測等操作。系統(tǒng)中采用一個6 dB/倍頻的一階濾波器來進(jìn)行預(yù)加重。為進(jìn)行分幀和加窗,系統(tǒng)取幀長10 ms(80個樣點),窗長30 ms(240個樣點、覆蓋幀前120個樣點、幀后40個樣點),由半個漢明窗和1/4個余弦窗組合而成。為減小計算量和提高計算精度,窗函數(shù)采用制表法,用浮點數(shù)算出數(shù)值,再定點化為一張表以供調(diào)用。由于幅度門限法相對簡單,計算量較小,因此系統(tǒng)采用它來進(jìn)行語音的端點檢測。通過預(yù)處理后,便可以應(yīng)用短時分析技術(shù)逐幀提取出相應(yīng)的特征參數(shù)。
1.2 語音特征參數(shù)的提取
本系統(tǒng)采用基音參數(shù)、LPC參數(shù)和LPCC參數(shù)作為語音的特征參數(shù)。基音周期的估計采用自相關(guān)法,其具體過程是先求出一幀語音的自相關(guān)參數(shù),然后系統(tǒng)在[20,39]、[40,79]、[80,143]3個區(qū)間內(nèi)各選一個自相關(guān)峰值點作為候選基音,接著對規(guī)格化的3個自相關(guān)峰值進(jìn)行比較,選擇最大的那個作為最終的基音。由于信號受聲帶共振峰特性的影響,求出的基音值會有所偏離,解決的辦法是采用中心削波法,即將信號小于門限的點賦值為0,大于門限的保持不變,然后將處理過的信號按以上方法求自相關(guān)。LPC參數(shù)就是在線性預(yù)測(LP)分析中求得的全極點濾波器的系數(shù)集{ai}pi=1,即在預(yù)測誤差最小均方誤差準(zhǔn)則下,由公式


1.5 線性預(yù)測語音合成
本系統(tǒng)中需要進(jìn)行人機交流,如語音提示輸入識別語句、識別結(jié)果提示等。為了節(jié)省系統(tǒng)資源,保存完整的語音提示信息是不現(xiàn)實的。由于線性預(yù)測語音合成具有占用資源少、數(shù)據(jù)率低和實現(xiàn)簡單等特點[3],而且系統(tǒng)交互所需要的語音對音質(zhì)沒有特別的要求,因此考慮用它來實現(xiàn)語音的人機界面。具體的實現(xiàn)過程是:首先利用PARCOR分析在PC上提取輸入語音提示的PARCOR參數(shù)km,以普通文本形式保存,然后在DSP平臺上利用km由PARCOR分析的逆過程來實現(xiàn)語音提示的語音合成。語音分析的過程可以在PC上實現(xiàn),不占用系統(tǒng)資源,而語音分析得到的參數(shù)保存為文本后大小僅有幾KB,與原始語音信號幾百KB相比,占用系統(tǒng)數(shù)據(jù)區(qū)的資源少了很多,而語音合成的程序本身占用資源非常少,因此利用固定的參數(shù)文本和語音合成的辦法實現(xiàn)有限的語音提示很適合本系統(tǒng)。
2 算法的DSP實現(xiàn)
在TI眾多DSP產(chǎn)品中,TMS320C54X系列用于多媒體信號的處理及便攜式設(shè)備,其片上資源及工作頻率能滿足一般的音頻信號處理,而同樣適合于多媒體處理的C64X和C62X系列雖然性能更加出色,但成本過高,因此本系統(tǒng)中采用TI的DSK5402集成開發(fā)環(huán)境作為開發(fā)平臺。該平臺上提供了一個PCM3002立體聲編解碼芯片,可以實現(xiàn)語音的采集和播放,通過它可以讀入識別或是訓(xùn)練用的語音以及播放系統(tǒng)運行時所需要的語音提示命令。下面給出算法的具體優(yōu)化方案。
2.1 精度保持與程序優(yōu)化
本系統(tǒng)在信號處理過程中,由于迭代運算的大量出現(xiàn),而TMS320C5402是定點DSP,為了防止誤差的不斷積累,需要在迭代的運算中做大量定點的高精度基本算術(shù)運算。為了在保持精度的同時又不過分降低運行速度,本系統(tǒng)將大量高精度的算術(shù)運算匯編化。本文根據(jù)自相關(guān)模塊和LPC空間中求取IS距離模塊自身的特點,著重對這兩個模塊進(jìn)行優(yōu)化。
自相關(guān)模塊中輸入的數(shù)據(jù)為加過窗的16 bit數(shù)組,輸出數(shù)據(jù)為長字?jǐn)?shù)組,其中歸一化前采用32 bit,歸一化后也采用32 bit,計算歸一化數(shù)據(jù)所用除法采用Tayloer級數(shù),使除法精度有效位達(dá)到32 bit(C++下浮點運算有效位為24 bit)。由于指數(shù)位對精度影響很小,因此這種方法下數(shù)據(jù)的精度已經(jīng)超過了浮點運算。在匯編模塊中使用了特殊指令EXP和NORM對數(shù)據(jù)進(jìn)行位對齊,使保存未歸一化數(shù)據(jù)時利用所有位,精度得到保持,使用累加、平方累加、塊循環(huán)指令以加速程序運行[4]。通過優(yōu)化,使得在保持精度的同時,對一幀信號作自相關(guān)耗費6 036個CLK,遠(yuǎn)遠(yuǎn)超過用C語言實現(xiàn)該模塊的消耗。
LPC空間中求取IS距離模塊的難點在于,向量本身是32 bit,中間計算都是48 bit,牽涉到32 bit×32 bit、48 bit×32 bit等高精度計算,而且該模塊在訓(xùn)練和識別程序中都要反復(fù)被調(diào)用去計算LPC向量間的距離,對程序整體性能影響很大,只能將整塊程序全部改為匯編,而在C語言中調(diào)用匯編的方法在速度上達(dá)不到要求。該模塊中還使用了零開銷循環(huán)、雙字操作等指令來加速程序運行,而且利用匯編可以對存儲器直接操作,使多個高精度共用一些存儲器,避免了繁瑣的賦值,節(jié)省了空間[4]。通過優(yōu)化,計算一次IS距離只需4 211個CLK,而采用C語言中調(diào)用匯編需要13 054個CLK,由此可見,優(yōu)化效果很明顯。
2.2 實驗結(jié)果與性能分析
實驗采用長度為1 s的語音,VQ模式匹配的碼本大小為16,對采樣頻率為8 kHz的單聲道語音,采用10 ms的幀長逐幀提取參數(shù),包括基音、10階的LPC參數(shù)(相應(yīng)的自相關(guān)參數(shù))和10階LPCC參數(shù)。按本文提出的VQ方法對單一說話人進(jìn)行語音說話人識別。實驗中首先訓(xùn)練這6個人的碼本,所用的語音是“語音身份識別”,然后又使用這6個人另外一組相同語音進(jìn)行鑒別,實驗結(jié)果如表1所示。
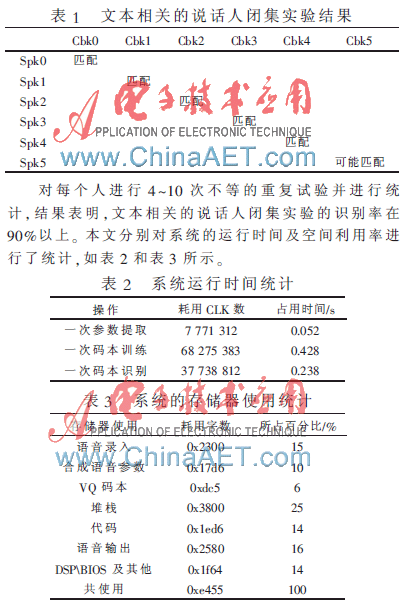
由表2和表3可知,系統(tǒng)運行的速度較快,基本可以達(dá)到準(zhǔn)實時的要求;整個系統(tǒng)占用近64 KB內(nèi)存空間,其中約32 KB是必需的存儲空間,32 KB是運行時所需的計算空間,由此可見,對系統(tǒng)資源的占用是較少的,完全可以滿足系統(tǒng)的要求。
基于DSP的說話人身份識別系統(tǒng)具有精度高、適應(yīng)性好、功耗低、費用低和體積小等優(yōu)勢,逐漸成為安全驗證領(lǐng)域新的研究熱點。本文在TI的DSK5402平臺上構(gòu)建了一個主要采用VQ方法的6個說話人識別系統(tǒng),該系統(tǒng)在指定文本的說話人閉集測試中取得了滿意的效果。與其他系統(tǒng)相比,本系統(tǒng)在實現(xiàn)算法上進(jìn)行了改進(jìn),在保證識別率的同時提高了速度,具有更大的使用價值。
本文的主要創(chuàng)新點在于:在TI的DSP平臺上實現(xiàn)了說話人身份識別算法的移植,并且在程序優(yōu)化過程中針對系統(tǒng)算法中一些模塊自身的特點,采取一系列手段使運算的精度得到保持、速度得到提高;系統(tǒng)還采用了線性預(yù)測語音合成方法來實現(xiàn)語音的人機交互界面,從而節(jié)省了更多系統(tǒng)內(nèi)存,使用起來更加方便快捷。
參考文獻(xiàn)
[1] 李財蓮,趙小陽,王麗娟,等.說話人識別中關(guān)鍵技術(shù)的現(xiàn)狀與發(fā)展[J].軍事通信技術(shù),2005,26(2):62.
[2] Huang H C, Pan J S, Lu Z M, et al. Vector quantization based on genetic simulated annealing[J]. Signal Processing, 2001, 81(7) :1513-1523.
[3] 賀艷平.基于線形預(yù)測下的語音信號合成[J].西北民族大學(xué)學(xué)報(自然科學(xué)版),2010,31(80):43.
[4] Texas Instruments. TMS320C54X assembly language tools user’s guide[Z]. 1997.
[5] 錢俊,王芙蓉.C代碼在TMS320C54X上的手工匯編優(yōu)化.DSP專欄[J].單片機與嵌入式系統(tǒng)應(yīng)用,2004(5):71-72.