
摘 要: 介紹了一種基于PCI總線和多片并行FPGA的高速計(jì)算平臺(tái)。FPGA+PCI板卡利用普通PC機(jī)作為CPU,通過PCI總線互聯(lián),實(shí)現(xiàn)了一個(gè)并行高速的通用數(shù)字運(yùn)算平臺(tái)。利用VHDL語言編寫各種算法,可用于加解密算法實(shí)現(xiàn)和高速數(shù)字信號(hào)處理等領(lǐng)域,而速度相當(dāng)于數(shù)臺(tái)PC機(jī)并行運(yùn)算。
關(guān)鍵詞: 并行計(jì)算 現(xiàn)場可編程門陣列 MD5
當(dāng)前對(duì)于各種加密算法,除了有針對(duì)性的破解算法,最基本的思想就是窮舉密鑰進(jìn)行匹配,通常稱為暴力破解算法。由于暴力破解算法包含密鑰個(gè)數(shù)較多,遍歷的時(shí)間超過實(shí)際可接受的范圍。如果計(jì)算速度提高到足夠快,這種遍歷的算法因結(jié)構(gòu)設(shè)計(jì)簡便而具有實(shí)際應(yīng)用的前景。
PCI 總線(外設(shè)互聯(lián)總線)與傳統(tǒng)的總線標(biāo)準(zhǔn)——ISA總線(工業(yè)標(biāo)準(zhǔn)結(jié)構(gòu)總線)相比, 具有更高的傳輸率(132MBps)、支持32位處理器及DMA和即插即用等優(yōu)點(diǎn),用于取代ISA總線而成為目前臺(tái)式計(jì)算機(jī)的事實(shí)I/O總線標(biāo)準(zhǔn),在普通PC機(jī)和工控機(jī)上有著廣泛的應(yīng)用。PCI總線為滿足在插卡和系統(tǒng)存儲(chǔ)器中高速傳輸數(shù)據(jù)的要求提供了很好的途徑。
PCI總線是一種獨(dú)立于處理器的局部總線,因此通過PCI總線插入擴(kuò)展板,利用并提升普通PC機(jī)和工控機(jī)對(duì)大規(guī)模數(shù)字信號(hào)處理的運(yùn)算能力和速度是一項(xiàng)非常具有實(shí)用意義的工作。
隨著數(shù)字技術(shù)日益廣泛的應(yīng)用,以現(xiàn)場可編程門陣列(FPGA)為代表的ASIC器件得到了迅速普及和發(fā)展,器件集成度和速度都在高速增長。FPGA既具有門陣列的高邏輯密度和高可靠性,又具有可編程邏輯器件的用戶可編程特性,可以減少系統(tǒng)設(shè)計(jì)和維護(hù)的風(fēng)險(xiǎn),降低產(chǎn)品成本,縮短設(shè)計(jì)周期。FPGA與通用CPU相比又具有如下顯著優(yōu)點(diǎn):
(1) FPGA一般均帶有多個(gè)加法器和移位器,特別適合多步驟算法中相同運(yùn)算的并行處理。通用CPU只能提供有限的多級(jí)流水線作業(yè)。
(2) 一塊FPGA中可以集成數(shù)個(gè)算法并行運(yùn)算。通用CPU一般只能對(duì)一個(gè)算法串行處理。
(3) 基于FPGA設(shè)計(jì)的板卡功耗小、體積小、成本低,特別適合板卡間的并聯(lián)。
本文介紹的基于PCI總線的FPGA計(jì)算平臺(tái)的系統(tǒng)實(shí)現(xiàn):通過在PC機(jī)上插入擴(kuò)展PCI卡,對(duì)算法進(jìn)行針對(duì)并行運(yùn)算的設(shè)計(jì),提升普通PC機(jī)對(duì)大計(jì)算量數(shù)字信號(hào)的處理速度。本設(shè)計(jì)采用5片F(xiàn)PGA 芯片及相關(guān)周邊芯片設(shè)計(jì)實(shí)現(xiàn)這一并行高速計(jì)算平臺(tái),并在該平臺(tái)上完成了DES和MD5等算法的加密和解密。文中通過基于MD5算法設(shè)計(jì)的加密方案(仿Yahoo郵箱的密碼校驗(yàn))進(jìn)行暴力破解,驗(yàn)證了本系統(tǒng)的可行性以及速度快、性價(jià)比高等顯著優(yōu)點(diǎn)。
1 系統(tǒng)結(jié)構(gòu)
系統(tǒng)利用普通PC機(jī)或工控機(jī)進(jìn)行控制、數(shù)據(jù)流下載和結(jié)果采集,大計(jì)算量的數(shù)字運(yùn)算利用IP-CORE技術(shù)并行地在FPGA中進(jìn)行。將數(shù)字信號(hào)處理的算法設(shè)計(jì)為一個(gè)單元模塊,并根據(jù)芯片的結(jié)構(gòu)對(duì)布局和布線進(jìn)行優(yōu)化,該單元模塊重復(fù)利用的技術(shù)被稱為IP-CORE技術(shù)。在本系統(tǒng)中利用IP-CORE的可重復(fù)利用性,通過仲裁邏輯調(diào)度數(shù)據(jù)的分配,從而實(shí)現(xiàn)算法的并行處理。
1.1 硬件結(jié)構(gòu)
系統(tǒng)中采用5片ALTERA公司的STRATIX EP1S10 FPGA 芯片,其中4片作為數(shù)字信號(hào)處理算法CORE的載體(文中稱為算法FPGA);1片作為連接PC機(jī)與運(yùn)算CORE的橋接芯片、加載程序、并行總線裁決和中斷判決等仲裁邏輯的載體。與PCI總線的接口使用PLX公司的 PCI9054芯片。系統(tǒng)硬件結(jié)構(gòu)如圖1所示。

1.2 邏輯結(jié)構(gòu)
BRIDGE FPGA的程序采用自頂向下的設(shè)計(jì)方法,其邏輯結(jié)構(gòu)如圖2所示,按功能可分為以下部分:頂層模塊 PCI_FPGA_PARALLEL;與PCI9054的接口模塊PCI接口;數(shù)據(jù)緩存及仲裁部分:數(shù)據(jù)緩存模塊 FIFO、寄存器模塊 regpart、數(shù)據(jù)回傳模塊deserial、內(nèi)部總線仲裁和流控模塊 CORE接口等。

PCI接口部分實(shí)現(xiàn)與PCI9054 芯片的接口時(shí)序,使得復(fù)用的地址和數(shù)據(jù)分開,產(chǎn)生地址空間的選取及使能信號(hào),便于后端處理。
仲裁邏輯部分:
(1)實(shí)現(xiàn)對(duì)地址空間內(nèi)數(shù)據(jù)緩沖區(qū)、各種寄存器的讀寫,以及根據(jù)配置寄存器的內(nèi)容對(duì)算法CORE和橋FPGA做相應(yīng)的操作(配置、啟動(dòng)、停止、復(fù)位等)。
(2)利用緩沖區(qū)及FIFO的隊(duì)列長度信號(hào)wrusedw、rdusedw、
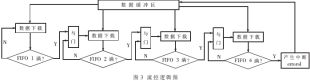
full和empty進(jìn)行數(shù)據(jù)流控制。數(shù)據(jù)由PC機(jī)下載時(shí)首先進(jìn)入緩沖區(qū),每一塊算法CORE均對(duì)應(yīng)一個(gè)數(shù)據(jù)下行FIFO,由FIFO當(dāng)前狀態(tài)來判定是否從緩沖區(qū)中取數(shù)。具體邏輯模型如圖3所示。
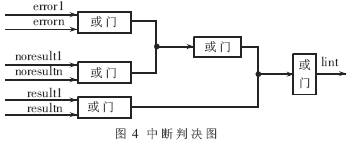
(3)返回結(jié)果引入本地中斷機(jī)制,當(dāng)有正確結(jié)果產(chǎn)生、或無正確結(jié)果但密鑰匹配完成、或系統(tǒng)異常狀態(tài),均產(chǎn)生中斷信號(hào)并填寫中斷類型寄存器,經(jīng)級(jí)聯(lián)后產(chǎn)生向PC機(jī)的中斷。中斷判決如圖4所示。
(4)實(shí)現(xiàn)與算法core間的協(xié)議邏輯,控制多種數(shù)據(jù)流的下行以及結(jié)果的返回。
2 MD5算法簡介
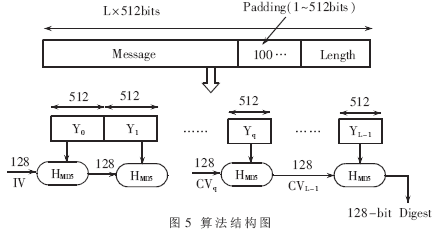
MD5(Message Digest 5)報(bào)文摘要算法是一種應(yīng)用廣泛的提取數(shù)字指紋的算法標(biāo)準(zhǔn),它由MIT的密碼學(xué)專家、RSA算法的發(fā)明人之一Rivest設(shè)計(jì)發(fā)明。MD5算法結(jié)構(gòu)如圖5所示。
對(duì)任意長度的信息輸入,MD5都將產(chǎn)生一個(gè)長度為128bit的輸出,這一輸出可以被看作是原輸入報(bào)文的“報(bào)文摘要值(Message Digest)”。
MD5的特點(diǎn):
(1)兩條不同的報(bào)文具有相同的報(bào)文摘要值的可能 性極小。
(2)對(duì)于預(yù)先給定的報(bào)文摘要值,要想尋找到一條報(bào)文,使得其報(bào)文摘要值與某個(gè)給定的報(bào)文摘要值相等,在計(jì)算上是不可能的。
(3)根據(jù)報(bào)文的摘要值,要
想推測出原來的報(bào)文是極端困難的。
MD5算法被廣泛地應(yīng)用于網(wǎng)絡(luò)數(shù)據(jù)完整性檢查以及各種數(shù)據(jù)加密技術(shù)中。Yahoo郵箱密碼算法是基于兩次MD5算法。共算法步驟如下:
step1: 對(duì)一個(gè)密碼字段(例如:'dfertgrhyt'),用MD5算法加密:h=md5('dfertgrhyt')。
step2: 將step1所得結(jié)果轉(zhuǎn)換為32Bytes的hex值:hex(h)。
step3: 將step2所得結(jié)果與一個(gè)yahoo提供的chanllenge值簡單級(jí)聯(lián):string=hex(h)+chanllenge
step4:將step3所得結(jié)果再進(jìn)行一次MD5運(yùn)算:hash=md5(string)。
由于未得到實(shí)際Yahoo郵箱密碼生成參數(shù)(例如challenge碼),本文構(gòu)造了相近算法以測試本系統(tǒng)性能。測試方案如下:
提供一個(gè)已知的challenge值與相應(yīng)的Hash值,從提供的字典中提取合適密碼,由生成算法計(jì)算出對(duì)應(yīng)的Hash值與提供的Hash值匹配來校驗(yàn)匹配的密碼。密鑰字典的產(chǎn)生有兩種方式:人為構(gòu)造字典及系統(tǒng)自加、窮舉產(chǎn)生密鑰。
3 實(shí)測性能分析
實(shí)際系統(tǒng)中算法CORE運(yùn)算時(shí)鐘為20MHz,64bit數(shù)據(jù)寬度輸入;采用多級(jí)流水線設(shè)計(jì)及運(yùn)算速度就是系統(tǒng)運(yùn)行時(shí)鐘的速度。除運(yùn)算初期流水線建立過程和運(yùn)算結(jié)束時(shí)流水線完成過程,運(yùn)算速度均可視為20MHz;實(shí)際制成的系統(tǒng)為四片算法FPGA并行運(yùn)算,實(shí)際吞吐量為4×20M×16bit=1.28Gb;經(jīng)Altera Quartus 4.1 綜合,實(shí)際仲裁邏輯占用3 725個(gè)邏輯單元。綜合頻率最高為156.2MHz,單算法邏輯占用7 718個(gè)邏輯單元,綜合頻率最高為37.10MHz。
典型的普通PC機(jī)定點(diǎn)運(yùn)算需要多個(gè)指令周期,包括取指令、取數(shù)據(jù)、計(jì)算、保存數(shù)據(jù)等指令周期,而一個(gè)x86指令周期又由多個(gè)CPU時(shí)鐘周期組成,大大降低了實(shí)際運(yùn)算速度。由于單個(gè)CORE以20MHz時(shí)鐘流水線運(yùn)算,相當(dāng)于一臺(tái)普通PC機(jī)的運(yùn)算速度,因此多個(gè)CORE并行運(yùn)算即可達(dá)到多臺(tái)PC機(jī)并行運(yùn)算的效率。
采取密鑰字典自FPGA窮舉產(chǎn)生方式,可發(fā)揮算法CORE的最大效能。若采取密鑰字典自PC機(jī)下載方式,則實(shí)際速率由PCI總線最高速率決定。但由于字典可以人為選取,大大降低了密鑰選取的盲目性。本系統(tǒng)接入普通PC機(jī)上32bit、32MHz的PCI總線,單算法CORE連續(xù)運(yùn)算(64bit×20MHz)即可滿足PCI總線全速下載。若使用64bit、66MHz的PCI總線或 PCI EXPRESS,將進(jìn)一步提高系統(tǒng)的實(shí)際吞吐量。
本文提出了一種基于FPGA的適合大規(guī)模數(shù)字信號(hào)處理的并行處理結(jié)構(gòu),利用CORE的可置換性,可以針對(duì)不同應(yīng)用的數(shù)字運(yùn)算設(shè)計(jì)不同的CORE,系統(tǒng)通用性的特點(diǎn)非常顯著。一臺(tái)普通PC機(jī)中可以同時(shí)插入數(shù)塊PCI卡,每塊卡上的任意一塊算法FPGA都可提供相當(dāng)或超過一臺(tái)普通PC機(jī)的運(yùn)算速度。而每增加一塊算法FPGA,在效率提高一倍的前提下,功耗增加不超過10W,而體積幾乎不變,成本也只是比普通PC機(jī)增加了五分之一。因此,本文提出的并行結(jié)構(gòu)具有極高的性價(jià)比。
如果將PCI總線接口模塊集成到FPGA中以取代PCI9054芯片,將進(jìn)一步降低硬件成本,減少硬件設(shè)計(jì)的復(fù)雜度;因?qū)嶋H運(yùn)算速度與算法的并行度和優(yōu)化有密切的關(guān)系,因此,設(shè)計(jì)不同應(yīng)用的CORE以及相關(guān)算法的優(yōu)化是下一步要進(jìn)行的重要工作。
參考文獻(xiàn)
1 Rivest R L. The MD5 message-digest algorithm. RFC 1321,MIT Laboratory for Computer Science and RSA Data Security,Inc.,April 1992
2 Jarvinen K, Tommiska M, Skytta J. Hardware implementation analysis of the MD5 hash algorithm. System Sciences, 2005. HICSS ′05. Proceedings of the 38th Annual Hawaii International Conference on 03-06 Jan. 2005:298
3 Shanley T. Anderson D. PCI系統(tǒng)結(jié)構(gòu).北京:電子工業(yè)出版社, 2000
4 侯伯亨,顧 新. VHDL硬件描述語言與數(shù)字邏輯電路設(shè)計(jì).西安:西安電子科技大學(xué)出版社, 1999