
摘 要: 涌現(xiàn)于社交網(wǎng)絡(luò)、電子商務(wù)中的超大規(guī)模非結(jié)構(gòu)化數(shù)據(jù)標(biāo)志著大數(shù)據(jù)時(shí)代的到來。大數(shù)據(jù)的多樣性、超大規(guī)模和可擴(kuò)展性等特征對運(yùn)行平臺產(chǎn)生新的要求。隨著大數(shù)據(jù)的產(chǎn)生和發(fā)展,形成了具有代表性的信息體系結(jié)構(gòu),包括編程模型、虛擬化和分布式文件系統(tǒng)等。隨著對大數(shù)據(jù)研究的深入,通過對大數(shù)據(jù)負(fù)載特性的分析,發(fā)現(xiàn)制約大數(shù)據(jù)的并不是計(jì)算能力,而是I/O延遲,采用基于內(nèi)存的分布式文件系統(tǒng),用于存儲和處理大規(guī)模分布式文件系統(tǒng)查詢的索引,可以有效降低I/O延遲,提高應(yīng)用性能。
關(guān)鍵詞: 大數(shù)據(jù);負(fù)載特征;內(nèi)存系統(tǒng);系統(tǒng)結(jié)構(gòu)
隨著電子技術(shù)的發(fā)展,計(jì)算成本降低,內(nèi)存容量增加,大部分平臺都可以用于高性能計(jì)算,可以處理比以往更多的數(shù)據(jù)信息,此外大規(guī)模集群技術(shù)的成熟,促成了多樣性、超大規(guī)模和可擴(kuò)展的多種典型應(yīng)用,即大數(shù)據(jù)應(yīng)用。大數(shù)據(jù)是一種數(shù)據(jù)分析技術(shù),用于從超大規(guī)模的多源信息中快速獲得有價(jià)值數(shù)據(jù)[1]。
在大數(shù)據(jù)應(yīng)用的發(fā)展進(jìn)程中,逐步形成了典型信息處理架構(gòu)。硬件架構(gòu)而言,其為大規(guī)模可擴(kuò)展但不穩(wěn)定的運(yùn)算和存儲基礎(chǔ)設(shè)施;軟件架構(gòu)而言,其涵蓋虛擬化、分布式數(shù)據(jù)庫系統(tǒng)、數(shù)據(jù)挖掘和機(jī)器學(xué)習(xí)等。
隨著大數(shù)據(jù)應(yīng)用的擴(kuò)展,對其研究的深入,提出了一些更有效的方法,這里基于大數(shù)據(jù)負(fù)載特性,分析以傳統(tǒng)用于計(jì)算的內(nèi)存作為存儲介質(zhì),以加速制約大數(shù)據(jù)應(yīng)用性能的延遲問題[2]。
1 大數(shù)據(jù)應(yīng)用典型架構(gòu)
以大數(shù)據(jù)應(yīng)用為典型架構(gòu),從開發(fā)搜索引擎的需要出發(fā),Google提出了Map/Reduce架構(gòu),此后開源社區(qū)根據(jù)該思想實(shí)現(xiàn)了Hadoop系統(tǒng),并得到廣泛應(yīng)用,使得大數(shù)據(jù)研究迅速成為熱點(diǎn)。
大數(shù)據(jù)應(yīng)用與高性能計(jì)算有典型區(qū)別,大數(shù)據(jù)應(yīng)用中基礎(chǔ)節(jié)點(diǎn)失效是正常的,運(yùn)算向存儲節(jié)點(diǎn)遷移,非結(jié)構(gòu)化文件的操作被優(yōu)化為追加操作。大數(shù)據(jù)典型結(jié)構(gòu)如圖1所示,在底層服務(wù)器節(jié)點(diǎn)之上是由存儲文件系統(tǒng)元數(shù)據(jù)的主節(jié)點(diǎn)和存儲文件實(shí)際數(shù)據(jù)的子節(jié)點(diǎn)組成的GFS或HDFS之類的分布式文件系統(tǒng)[3]。文件系統(tǒng)之上是分布式數(shù)據(jù)庫系統(tǒng),代表性的有BigTable和Hbase。數(shù)據(jù)庫節(jié)點(diǎn)同樣也分為兩類:Master節(jié)點(diǎn)管理元數(shù)據(jù)并處理客戶端元數(shù)據(jù)請求,Tablet節(jié)點(diǎn)存儲數(shù)據(jù)并處理數(shù)據(jù)請求。
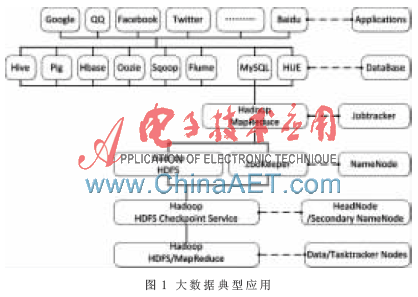
開源分布式文件系統(tǒng)HDFS由大量普通計(jì)算機(jī)組成,任何時(shí)候任何節(jié)點(diǎn)都有可能出現(xiàn)故障,因此在HDFS的核心架構(gòu)設(shè)計(jì)時(shí),基礎(chǔ)節(jié)點(diǎn)的出錯(cuò)檢測和自動(dòng)恢復(fù)是關(guān)鍵目標(biāo)之一。HDFS系統(tǒng)采用主/從架構(gòu),包括目錄服務(wù)器節(jié)點(diǎn)和數(shù)據(jù)節(jié)點(diǎn)。系統(tǒng)中文件實(shí)際上劃分為數(shù)據(jù)塊冗余存儲在多個(gè)數(shù)據(jù)節(jié)點(diǎn)里,數(shù)據(jù)節(jié)點(diǎn)在目錄節(jié)點(diǎn)的控制下執(zhí)行文件數(shù)據(jù)塊的操作,存儲管理本節(jié)點(diǎn)上的文件數(shù)據(jù)塊。目錄節(jié)點(diǎn)執(zhí)行文件系統(tǒng)的目錄空間操作,同時(shí)決定文件數(shù)據(jù)塊到具體數(shù)據(jù)節(jié)點(diǎn)的映射,目錄節(jié)點(diǎn)管理文件系統(tǒng)的目錄和客戶端對文件數(shù)據(jù)的訪問。
HDFS系統(tǒng)中分布式文件系統(tǒng)之上是數(shù)據(jù)庫系統(tǒng)。利用數(shù)據(jù)庫系統(tǒng),用戶可以按照類似數(shù)據(jù)庫范式進(jìn)行數(shù)據(jù)處理。大數(shù)據(jù)應(yīng)用中為非結(jié)構(gòu)化數(shù)據(jù),即NoSQL數(shù)據(jù)庫系統(tǒng),它支持簡單查詢操作,而將復(fù)雜查詢交給應(yīng)用層處理(例如基于Map/Reduce框架實(shí)現(xiàn)大規(guī)模數(shù)據(jù)分析)。BigTable和Hbase數(shù)據(jù)庫是典型的主/從結(jié)構(gòu)的鍵/值存儲NoSQL數(shù)據(jù)庫系統(tǒng)。
HDFS系統(tǒng)結(jié)構(gòu)中的頂層即為大數(shù)據(jù)應(yīng)用,典型的應(yīng)用例如搜索引擎和社交網(wǎng)絡(luò)等。其中許多大數(shù)據(jù)應(yīng)用將Hadoop系統(tǒng)當(dāng)作數(shù)據(jù)存儲設(shè)施,在此存儲設(shè)施上進(jìn)一步挖掘獲取或分析其中的有價(jià)值信息[4]。
2 大數(shù)據(jù)負(fù)載特征
基于分布式文件系統(tǒng)以及其上的分布式數(shù)據(jù)庫系統(tǒng)的大數(shù)據(jù)應(yīng)用,隨著應(yīng)用規(guī)模的擴(kuò)大,分布式系統(tǒng)中數(shù)據(jù)訪問延遲將極大地影響應(yīng)用的性能體驗(yàn)。Map/Reduce架構(gòu)通過將計(jì)算遷移到數(shù)據(jù)節(jié)點(diǎn),同時(shí)使用冗余請求有效降低延遲。盡管如此,大數(shù)據(jù)應(yīng)用的訪問延遲仍然占到較大比例,其中最大負(fù)擔(dān)是硬盤訪問延遲,因此系統(tǒng)發(fā)展趨向于使用SSD硬盤替換磁介質(zhì)硬盤,并將頻繁隨機(jī)訪問的數(shù)據(jù)都放到節(jié)點(diǎn)各自內(nèi)存中,而將順序操作數(shù)據(jù)存儲到硬盤。
網(wǎng)絡(luò)延遲對分布式系統(tǒng)的影響也是一個(gè)關(guān)鍵問題。在高性能計(jì)算架構(gòu)中采用InfiniBand、Myrinet和Arista等高性能互聯(lián)技術(shù)可實(shí)現(xiàn)跨數(shù)據(jù)中心微秒級延遲通信,而大數(shù)據(jù)應(yīng)用中服務(wù)器節(jié)點(diǎn)之間廣泛采用的TCP/IP以太網(wǎng)的延遲達(dá)到數(shù)百微秒。因此網(wǎng)絡(luò)延遲的優(yōu)化是影響大數(shù)據(jù)應(yīng)用性能的關(guān)鍵因素之一。
3 基于內(nèi)存的延遲優(yōu)化技術(shù)
內(nèi)存是計(jì)算機(jī)系統(tǒng)中處理器之外訪問延遲最小的部件,因此利用內(nèi)存技術(shù)優(yōu)化分布式系統(tǒng)數(shù)據(jù)訪問延遲是一個(gè)關(guān)鍵策略。以搜索引擎應(yīng)用為例,典型的搜索引擎已經(jīng)完全將網(wǎng)頁索引數(shù)據(jù)全部存儲在內(nèi)存中,有的系統(tǒng)甚至把所有網(wǎng)頁快照都全部存儲在分布式服務(wù)器內(nèi)存中[1]。
利用內(nèi)存的訪問延遲優(yōu)勢,基于內(nèi)存的數(shù)據(jù)庫可以支持對數(shù)據(jù)進(jìn)行實(shí)時(shí)處理。系統(tǒng)配置的內(nèi)存越多,對數(shù)據(jù)的處理速度也就越快。計(jì)算機(jī)系統(tǒng)中不同部件的數(shù)據(jù)訪問速度如圖2所示。目前典型數(shù)據(jù)庫系統(tǒng)都支持多核處理器平臺,基于內(nèi)存的數(shù)據(jù)庫技術(shù),利用更多的內(nèi)存資源,克服目前分布式系統(tǒng)服務(wù)延遲性能瓶頸。其中應(yīng)用較多的典型內(nèi)存數(shù)據(jù)庫有Memcached和Redis等。

Memcached是一個(gè)結(jié)構(gòu)簡潔的高性能內(nèi)存數(shù)據(jù)庫,常用于網(wǎng)絡(luò)應(yīng)用以減輕數(shù)據(jù)訪問負(fù)載。它通過在內(nèi)存中緩存數(shù)據(jù)來減少系統(tǒng)訪問次數(shù),從而提高基于數(shù)據(jù)庫網(wǎng)絡(luò)應(yīng)用的響應(yīng)速度。未使用內(nèi)存數(shù)據(jù)緩存時(shí),大的數(shù)據(jù)記錄在進(jìn)行讀寫訪問時(shí)需要較長時(shí)間響應(yīng),尤其是并發(fā)訪問頻繁時(shí),嚴(yán)重影響系統(tǒng)性能。而Memcached通過使用簡單的鍵值對存儲訪問數(shù)據(jù),可以較好地提高應(yīng)用性能。與Memcached相似的Redis是一個(gè)采用hash結(jié)構(gòu)來做鍵值對存儲的基于內(nèi)存的NoSQL數(shù)據(jù)庫[5]。
4 基于內(nèi)存數(shù)據(jù)庫元數(shù)據(jù)節(jié)點(diǎn)
大數(shù)據(jù)應(yīng)用中元數(shù)據(jù)的查詢管理操作直接影響整個(gè)系統(tǒng)性能,因此利用基于內(nèi)存技術(shù)的NoSQL數(shù)據(jù)庫管理元數(shù)據(jù)是一個(gè)較好的優(yōu)化方法。
Memcached用作分布式內(nèi)存數(shù)據(jù)緩存服務(wù)器,將鍵值數(shù)據(jù)對存儲于節(jié)點(diǎn)主內(nèi)存中,其瓶頸在于需要處理存儲的鍵值數(shù)據(jù)對與后臺數(shù)據(jù)庫服務(wù)器之間的一致性,需要刷新緩存值以更新數(shù)據(jù)庫,因此需要對具體應(yīng)用進(jìn)行管理,增加了應(yīng)用開發(fā)的復(fù)雜性。這類非關(guān)系型NoSQL數(shù)據(jù)庫以鍵值對方式存儲數(shù)據(jù),每一個(gè)元組可以有不一樣的字段,結(jié)構(gòu)不固定,可以根據(jù)需要增加一些鍵值數(shù)據(jù)對,不局限于固定結(jié)構(gòu),可以有效提高系統(tǒng)性能,但其后臺訪問速度[6]依然是瓶頸。
利用內(nèi)存技術(shù),特別是分布式系統(tǒng)中大量節(jié)點(diǎn)的內(nèi)存存儲數(shù)據(jù)以優(yōu)化訪問速度,可以有效提高系統(tǒng)性能,典型例子就是RAMCloud內(nèi)存云技術(shù)。這是利用數(shù)據(jù)中心或集群系統(tǒng)的大量服務(wù)器的內(nèi)存來存儲所有應(yīng)用數(shù)據(jù)的存儲結(jié)構(gòu)。傳統(tǒng)保存在磁盤上的所有數(shù)據(jù)都可以保存在RAMCloud內(nèi)存存儲中。RAMCloud可提供比磁盤存儲低數(shù)百倍延遲和比磁盤存儲高近千倍的吞吐量。利用內(nèi)存的訪存特點(diǎn)以及成熟的分布式系統(tǒng)技術(shù),RAMCloud具有優(yōu)異的性能體驗(yàn)和良好的可擴(kuò)展性,使之可以成為大數(shù)據(jù)應(yīng)用中性能優(yōu)化的關(guān)鍵技術(shù)。
RAMCloud的原理是基于分布式節(jié)點(diǎn)的內(nèi)存提供一個(gè)通用的存儲系統(tǒng),提供一個(gè)簡單易用的存儲模型,具有良好的擴(kuò)展性。開發(fā)人員不需要采取特殊的方式對待RAMCloud數(shù)據(jù)存儲,原有應(yīng)用程序不需要做架構(gòu)上的改變就可以遷移到RAMCloud平臺。
基于分布式內(nèi)存的RAMCloud的訪問延遲可低至微秒級別。這比傳統(tǒng)磁盤快近千倍,比基于半導(dǎo)體閃存器件的SSD要快數(shù)倍。RAMCloud的低延遲特性對于對響應(yīng)要求苛刻的網(wǎng)絡(luò)應(yīng)用和頻繁訪問數(shù)據(jù)為瓶頸的一些應(yīng)用(例如高性能計(jì)算)來說極為重要。
4.1 RAMCloud模型
基于內(nèi)存技術(shù)的RAMCloud的低延遲和可擴(kuò)展屬性,便于大規(guī)模部署,消除了大數(shù)據(jù)應(yīng)用所面臨的性能和擴(kuò)展性問題,可以處理比目前多數(shù)百倍的數(shù)據(jù)。RAMCloud技術(shù)的可擴(kuò)展性可以支持各個(gè)級別規(guī)模的應(yīng)用,并可在小型應(yīng)用擴(kuò)展為大型應(yīng)用時(shí)確保順利進(jìn)行,不涉及額外的存儲結(jié)構(gòu)。基于RAMCloud模型的應(yīng)用系統(tǒng)框圖如圖3所示。
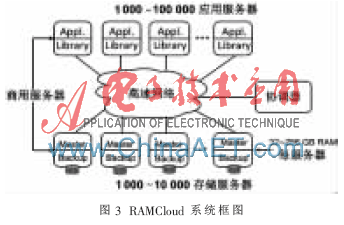
基于內(nèi)存技術(shù)的RAMCloud代表存儲服務(wù)的一種新存儲模型。RAMCloud與傳統(tǒng)存儲系統(tǒng)的區(qū)別在于,首先所有應(yīng)用數(shù)據(jù)在任何時(shí)候都存儲在構(gòu)成RAMCloud存儲系統(tǒng)的分布式內(nèi)存中;其次RAMCloud必須建立在一定數(shù)量的服務(wù)器上,并實(shí)現(xiàn)節(jié)點(diǎn)的出錯(cuò)檢測和自動(dòng)恢復(fù)。與傳統(tǒng)存儲系統(tǒng)一樣,存儲在RAMCloud系統(tǒng)的數(shù)據(jù)就像存儲在磁盤上那樣是持久的。單一節(jié)點(diǎn)的存儲出現(xiàn)故障后不會造成數(shù)據(jù)丟失或數(shù)據(jù)不可用的狀況。
與典型大數(shù)據(jù)應(yīng)用結(jié)構(gòu)一致,基于內(nèi)存技術(shù)的分布式內(nèi)存存儲系統(tǒng)也可以支持將計(jì)算遷移到數(shù)據(jù)節(jié)點(diǎn),同時(shí)使用冗余請求進(jìn)一步降低延遲。利用分布式內(nèi)存存儲技術(shù),在應(yīng)用服務(wù)器上運(yùn)行的進(jìn)程訪問數(shù)據(jù)的延遲有可能降低到微秒級別,而基于傳統(tǒng)磁介質(zhì)存儲系統(tǒng)通常為近毫秒級別。
4.2 分布式內(nèi)存存儲分析
基于分布式內(nèi)存技術(shù)的大數(shù)據(jù)應(yīng)用新架構(gòu),傳統(tǒng)的架構(gòu)是應(yīng)用程序的代碼和本地局部數(shù)據(jù)被加載到計(jì)算機(jī)主存儲中,需要時(shí)訪問本地或遠(yuǎn)程存儲節(jié)點(diǎn)。圖4顯示各種存儲方式下數(shù)據(jù)的訪問延遲。傳統(tǒng)應(yīng)用的性能瓶頸是顯而易見的,不同數(shù)據(jù)的頻繁訪問操作、應(yīng)用程序的并發(fā)訪問、規(guī)模大小都可能造成系統(tǒng)性能瓶頸。
基于分布式內(nèi)存存儲技術(shù)代替?zhèn)鹘y(tǒng)的存儲系統(tǒng),采用基于輕量低功耗處理器的微服務(wù)器,將在線應(yīng)用數(shù)據(jù)的主要存儲中心從傳統(tǒng)存儲遷移到分布式內(nèi)存上,利用成熟的集群技術(shù),構(gòu)建可擴(kuò)展的基于內(nèi)存的存儲系統(tǒng),利用Map/Reduce框架實(shí)現(xiàn)大數(shù)據(jù)應(yīng)用。

基于內(nèi)存技術(shù)的RAMCloud架構(gòu)原理在于將所有應(yīng)用的數(shù)據(jù)信息存儲在分布式內(nèi)存上,并使用大量服務(wù)器構(gòu)建可擴(kuò)展的大型存儲系統(tǒng)。利用內(nèi)存的訪存延遲極低的特性,存儲在內(nèi)存上的數(shù)據(jù)的延遲要比存儲在基于傳統(tǒng)存儲系統(tǒng)上低近千倍,而吞吐量則會高數(shù)百倍。
大數(shù)據(jù)應(yīng)用主要延遲來自數(shù)據(jù)訪問延遲,對處理器計(jì)算能力的需求遠(yuǎn)低于處理器所能提供的性能。采用基于輕量低功耗處理器的微服務(wù)器,將應(yīng)用數(shù)據(jù)從傳統(tǒng)存儲遷移到分布式內(nèi)存上。內(nèi)存存儲充分結(jié)合了內(nèi)存的低延遲和集群的規(guī)模化優(yōu)勢,保持應(yīng)用可擴(kuò)展性的同時(shí)降低了數(shù)據(jù)訪問延遲。這種基于分布式內(nèi)存存儲的大數(shù)據(jù)可以同時(shí)實(shí)現(xiàn)大規(guī)模和低延遲的優(yōu)勢,有效加速大數(shù)據(jù)應(yīng)用。
參考文獻(xiàn)
[1] KAI H, GEOFFREY C F, JACK J D. Distributed and cloud computing: from parallel processing to the internet of things[M]. Massachusetts: Morgan Kaufmann Publishers, 2012.
[2] Jia Zhen, Wang Lei, Zhan Jianfeng, et al. Characterizing data analysis workloads in data centers[C]. In Workload Characterization (IISWC), 2013 IEEE International Symposium on. IEEE. 2013.
[3] 吳朱華. 云計(jì)算核心技術(shù)剖析[M]. 北京:人民郵電出版社,2011.
[4] 王鵬.云計(jì)算的關(guān)鍵技術(shù)與應(yīng)用實(shí)例[M]. 北京:人民郵電出版社,2010.
[5] 曾超宇,李金香.Redis在高速緩存系統(tǒng)中的應(yīng)用[J].微型機(jī)與應(yīng)用, 2013,32(12):11-13.
[6] 張青鳳, 張鳳琴, 王磊.多數(shù)據(jù)中心的數(shù)據(jù)同步模型研究與設(shè)計(jì)[J]. 微型機(jī)與應(yīng)用, 2013,32(12):60-62.