
摘要: 根據CMMB中LDPC 碼校驗矩陣的結構特點, 提出了一種部分并行譯碼結構的實現方法, 并在XILINX的VirtexIV的XC4VLX80型FPGA上實現了這種結構。該設計充分利用了LDPC校驗矩陣的規(guī)律, 采用了一種適當的硬件結構和獨特的存儲器調用控制策略, 故可在保證高性能和較大吞吐率的情況下, 以較少的硬件資源實現兩種碼率的復用。
0 引言
低密度奇偶校驗(Low Density Parity Check,LDPC) 碼是由Gallager博士在1962年首次提出來的, 由于LDPC碼的誤碼性能能夠逼近香農限,因而在無線通信、衛(wèi)星通信等領域都得到了較多應用。中國移動多媒體廣播(CMMB) 中使用的就是LDPC糾錯編碼。在CMMB標準中, LDPC碼長為9216, 可支持1/2和3/4 兩種碼率。作者通過深入分析CMMB中LDPC碼校驗矩陣的特點, 采用了一種合適的硬件實現結構, 因而在保證譯碼器較高性能和較快譯碼速度的情況下, 以較低的硬件資源實現了兩種碼率的復用。
1 CMMB 標準中的LDPC 譯碼算法
1.1 CMMB中LDPC 碼的主要特征
CMMB采用規(guī)則的LDPC 碼, 兩種碼率的LDPC校驗矩陣有類似的規(guī)律。CMMB 中1/2 碼率的LDPC碼校驗矩陣為一個4608×9216 的矩陣, 進一步可劃分為256個18×9216行子矩陣。其中下一個行子矩陣是上一個行子矩陣的向右循環(huán)移36位,每一個行子矩陣的行重都為6; 也可以把它劃分為25*608×36 列子矩陣, 其中后一個列子矩陣是前一個列子矩陣的向下循環(huán)移18位, 每一個列子矩陣的列重都為3。同理, 3/4碼率的矩陣也可以進行類似的劃分, 可劃分為256個9×9216的行子矩陣, 每個行子矩陣的行重為12; 當然, 也可以分為256個2304×36, 列重為3的列子矩陣。
從校驗矩陣的特點可以看出, 只要存儲器能存儲一個行或列子矩陣的非零元素, 則利用這些非零元素, 就可以恢復出整個校驗矩陣, 從而進行譯碼。而且更為重要的是, 對于同種碼率, 行子矩陣組和列子矩陣組之間在非零元素位置上有著潛在的對應關系。本文正是通過挖掘這種潛在的對應關系, 設計出了一種獨特的存儲器調用控制策略, 并成功實現了復用RAM的同時, 滿足了兩種碼率的硬件結構。
1.2 LDPC譯碼算法
常用的LDPC碼譯碼算法為置信度傳遞解碼算法(BP decoding)。該算法相對比較成熟, 性能非常優(yōu)異。但是, BP算法中的f (x) 函數包含對數運算和指數運算, 這些復雜運算大大增加了BP譯碼器的運算量和復雜度。Fossorier等在1999年提出了一種min-sum譯碼算法, 即利用一種近似的方法來處理BP算法中的f (x) 函數, 以將對數和指數運算化簡為乘法和比較運算, 從而減少了譯碼器的運算量, 但該方法在性能上也有一定損失。后來, Jinghu Chen和Fossorier又提出了修正的min-sum算法。在碼長較長的情況下, 修正的min-sum算法比BP算法性能只差0.03~0.05 dB, 而在算法復雜度上則只需要乘以一個常量修正因子。基于以上分析, 本文采用修正的min-sum算法來進行迭代更新, 此更新分為校驗節(jié)點更新和變量節(jié)點更新。其迭代譯碼步驟分為兩步。
第一步是初始化, 即對每個m和n, R0n→m=0其次是迭代過程。而每次迭代又包括以下3個步驟:

記集合N (m) 表示與校驗節(jié)點相連的所有變量節(jié)點; 集合M (n) 表示與變量節(jié)點相連的所有校驗節(jié)點; N (m) \n表示N (m) 中除去變量節(jié)點n, 同理, M (n) \m表示M (n) 中除去校驗節(jié)點m。α一般取值為0.6~0.9, 本系統(tǒng)中通過C模型浮點和定點仿真, 可以得到α的最佳取值約為0.8,為了便于移位實現, 取值為0.7875或者0.8125均可。
2 CMMB中LDPC譯碼器的硬件實現
2.1 譯碼器總體結構
LDPC碼的譯碼器通常有串行結構、并行結構和部分并行結構等。根據校驗矩陣的特點,LDPC部分并行譯碼結構可簡單分為輸入和輸出存儲單元、VNU ( 變量節(jié)點運算) 單元、CNU(校驗節(jié)點運算) 單元和中間結果存儲單元。其譯碼器結構如圖1所示。為了便于ASIC實現, 本文采用單端口RAM, 每塊RAM由一個控制器控制以實現不同碼率的地址初始化、讀RAM、寫RAM等操作。
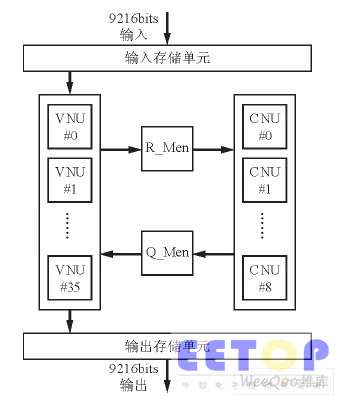
圖1 譯碼器的總體結構。
2.2 輸入和輸出存儲單元
檢測到輸入數據有效后, 可把輸入的串行數據依次存到初始化RAM 里。本譯碼器一共有36個初始化存儲器, 每個存儲器的深度為256。第1個數據存到第1個RAM的0 地址, 第2個數據存到第2個RAM的0地址, 依次類推, 第37個數據再存到第1個RAM的1地址, 直到一幀9216個數據全部存滿36個RAM。同樣, 輸出存儲單元可采用類似的存儲器調度方式。為了實現譯碼的連續(xù)性, 本設計在輸入和輸出部分使用了乒乓結構, 即采用兩組相同的36個RAM交替操作方式。
2.3 VNU單元
VNU單元用于完成兩部分工作: 一是由校驗節(jié)點和初始化信息來更新變量節(jié)點的值; 二是對每一列進行硬判決。檢驗節(jié)點更新后的值將存儲到存儲單元R_Mem, 而硬判決后的比特值則存到輸出存儲單元, 直到滿足停止譯碼兩個條件之一時才可輸出碼字。第一次垂直更新時, 不用輸入存儲單元Q_Mem的值, 而只把輸入存儲單元里的初始值送到VNU單元進行更新運算即可。由于兩種碼率下LDPC 檢驗矩陣的列重都是3, 因此, 兩種碼率下的VNU個數都為36個, 且每個VNU結構也都是4輸入的VNU。每次運算時, 都必須讀輸入存儲單元和Q_Mem (除第一次迭代外) 中的數據的運算結果, 但應同時寫入R_Mem存儲單元中。本操作內部采用流水線結構, 每次迭代都延遲2個時鐘周期。由于讀地址都為0, 而且讀地址每次加1, 因此, 執(zhí)行變量節(jié)點更新運算共需花費256+2個時鐘, 垂直更新結構的變量節(jié)點單元加法運算器結構如圖2所示。
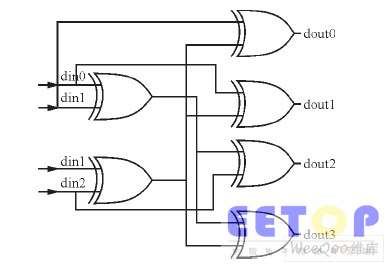
圖2 變量節(jié)點單元加法運算器結構。
2.4 CNU單元
CNU 單元也包括兩部分工作: 一是由變量節(jié)點來更新校驗節(jié)點的值, 并將更新后的值存儲到外部存儲器; 二是對每一行硬判決后的比特進行校驗, 以確定其是否滿足校驗方程, 也就是對每一行所對應比特進行異或, 并看結果是否為零。
若所有行的異或結構都為零, 則譯碼成功, 退出迭代。在CMMB標準中, 兩種碼率校驗矩陣H的行重有所不同(分別為6和12)。為了能共用CNU模塊并且共享存儲器資源, 筆者設計了12輸入的CNU單元, 并且使用9個CNU單元并行計算。這樣, 當碼率為1/2時, 1個CNU單元更新2行, 9個正好更新18行; 而當碼率為3/4時, 9個CNU單元更新9行。每個12輸入的CNU單元由2 個6 輸入CNU單元組成, 通過1個選擇器可控制CNU輸出。
1/2碼率時, 2個6輸入CNU的輸出結果可直接作為12 輸入CNU的輸出結果, 然后經緩存后送入Q_Mem; 3/4碼率時, 2個6輸入CNU的輸出再經過一級比較器得出的結果, 才作為12輸入CNU的輸出值送到Q_Mem存儲。為了方便比較最后一級比較器, 可在復用已有的兩組6輸入輸出比較單元的同時, 還得輸出兩組最小值。CNU單元電路采用流水線結構來設計延時增加4個時鐘周期(1/2碼率) 和5個時鐘周期(3/4碼率)。6輸入輸出CNU單元的結構簡圖如圖3所示。
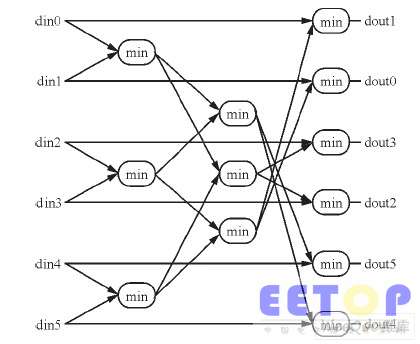
圖3 檢驗節(jié)點單元6輸入輸出結構。
2.5 中間結果存儲單元(R_Mem和Q_Mem)
由于兩種碼率時, 校驗矩陣第1個子矩陣中非零元素的位置不一樣。故在水平更新時, RAM的初始化地址也不一樣, 需要用兩組初始地址值。對兩種碼率來說, 第1個行子矩陣非零元素的個數都為108 (18×6或9×12)。事實上, 第1個列子矩陣非零元素的個數同樣為108 (3×36)。第1個行子矩陣和第1個列子矩陣非零元素位置有著潛在的一一對應的關系。舉例來說, 第1行(下標從0開始) 6個1的列位置(下標從0開始) 分別為0, 7, 19, 26, 31, 5*。若分析第5*列可以發(fā)現5*=157×36+12, 即5*列是第12列的移位。第12 列中非零位置對應的行號為0, 119, 1783=99×18+1。第5*列中非零位置對應的行號為1, 826, 2945。于是非零位置(1783, 12) 的映射為(1, 5*)。這樣, 通過挖掘行子矩陣和列子矩陣中每一個非零位置的對應關系, 就能準確地得出VNU和CNU運算單元數據之間的對應關系。把這種對應關系體現到memory的調度上來, 就能準確地從R_Mem和Q_Mem中取值以進行水平和垂直更新。表1所列是中間結果存儲單元和寫地址的對應關系。
表1 中間結果寫入單元和寫地址的對應關系
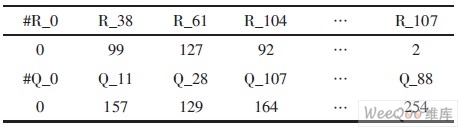
這里分別用了108個深度為256、寬度為6bits的單口RAM作為R_Mem和Q_Mem。當進行變量節(jié)點運算時, VNU輸入可從Q_Mem中讀取, 讀數時, 首地址為0, VNU輸出寫入R_Mem中, 寫順序首地址為黑體數字, 運算周期為256; 當所有變量節(jié)點更新后, 接著是校驗節(jié)點的運算, 同時可進行檢驗方程運算。此時, CNU輸入從R_Mem中讀取, 讀數的首地址為0, CNU 輸出寫入Q_Mem中, 寫入順序首地址為黑體數字, 運算周期同樣為256。如此交替, 便可完成迭代過程。
上述例子中, (1, 5*) 和(1783, 1) 的對應關系反映在存儲單元上, 正如表1中的第2列所示。
3 譯碼器的性能分析及FPGA實現
作者通過C語言模型和MATLAB模型對譯碼器進行了浮點和定點仿真。為了達到性能和面積的平衡, 位寬的取值為6 bits, 而譯碼器性能只比浮點模型損失了約0.15 dB。在AWGN信道和BPSK的調制解調方式下, 當碼率為1/2, 信噪比SNR為1.6 dB時, 誤碼率已經降至10-5以下。而在信噪比SNR為1.7 dB時, 誤碼率已經降至10-7以下; 當碼率為3/4時, 在信噪比SNR為3.0 dB時,誤碼率可以降至10-6以下。
本文按照上面所描述的硬件結構, 采用XILINX的VirtexIV-XC4VLX80器件實現了CMMB標準中兩種碼率的LDPC譯碼, 并且達到了和C定點模型同樣的性能。在ISE開發(fā)工具上對其進行編譯時, 其具體的資源利用情況如表2所列。
表2 VirtexIV-XC4VLX80的資源利用情況
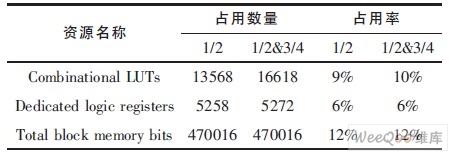
從表2中可以看出, 此結構不僅完全地復用了存儲器資源, 而且最大限度地復用了邏輯運算單元。正是因為兩種碼率可復用RAM資源, 使memory消耗較少, 從而剩下大量的RAM資源可以用作CMMB其余部分(如解交織模塊) 使用。LUT資源相對來說用得較多, 這是由于并行結構造成的, 它有36個VNU和9個CNU交替進行運算。
4 結束語
本文設計的部分并行結構的LDPC譯碼器能夠兼容不同碼率和不同校驗矩陣行重的LDPC碼。
運用該譯碼結構在XILINX的VirtexIV-XC4VLX80器件上可實現CMMB標準中兩種碼率的LDPC譯碼。事實上, 針對校驗矩陣的特點, 采用一種獨特的存儲器控制策略, 可以最大限度地復用硬件資源, 從而大大減少了譯碼器的資源消耗。