
摘 要: 將黑白名單技術(shù)與chinaaet.com/search/?q=Balanced Winnow" title="Balanced Winnow">Balanced Winnow算法相結(jié)合,實(shí)現(xiàn)對(duì)垃圾短信的過濾。采用CHI特征提取算法并對(duì)權(quán)重計(jì)算方法進(jìn)行改進(jìn),同時(shí)提出了去除訓(xùn)練樣本中野點(diǎn)的想法,通過判定去除野點(diǎn),減緩在訓(xùn)練過程中出現(xiàn)的抖動(dòng)現(xiàn)象。實(shí)驗(yàn)表明這種改進(jìn)對(duì)于提高訓(xùn)練速度及提高短信過濾的性能均有很好的作用。
關(guān)鍵詞: balanced Winnow;短信過濾;CHI;野點(diǎn)
手機(jī)短信以其短小、迅速、簡(jiǎn)便、價(jià)格低廉等優(yōu)點(diǎn)成為一種重要的通信和交流方式,受到眾多人士的青睞。然而,手機(jī)短信與郵件一樣存在著垃圾信息問題。
目前,垃圾短信過濾主要有黑名單過濾、關(guān)鍵詞過濾和基于文本分類的內(nèi)容過濾等方式。黑名單過濾和關(guān)鍵詞過濾方式能快速過濾垃圾短信,但這兩種過濾方式實(shí)質(zhì)是基于規(guī)則的過濾,雖然在一定程度上阻擋了一些垃圾短信,但規(guī)則的方法需要更多的用戶自定義設(shè)置,很容易被反過濾。基于文本分類的短信過濾采用常見的分類算法,如樸素貝葉斯、SVM、神經(jīng)網(wǎng)絡(luò)等。黎路[1]等人將貝葉斯分類應(yīng)用到J2ME模擬環(huán)境中成功地過濾了中獎(jiǎng)短信和祝福短信。浙江大學(xué)的金展、范晶等[2]將樸素貝葉斯和支持向量機(jī)結(jié)合,解決了傳統(tǒng)垃圾短信過濾系統(tǒng)短信特征和內(nèi)容未能得到及時(shí)更新而導(dǎo)致過濾性能降低的問題。王忠軍[3]將基于樸素貝葉斯短信過濾算法與基于最小風(fēng)險(xiǎn)貝葉斯算法進(jìn)行了實(shí)驗(yàn)分析和比較,結(jié)論是基于最小風(fēng)險(xiǎn)的短信過濾算法具有較好的性能。然而,短信過濾的準(zhǔn)確率依賴于其訓(xùn)練樣本的數(shù)量及質(zhì)量,這些分類算法需要經(jīng)過訓(xùn)練學(xué)習(xí)建立分類器模型,因此在速度上不能很好地滿足短信過濾實(shí)時(shí)性的要求。從現(xiàn)有技術(shù)上來(lái)說,垃圾短信的過濾在準(zhǔn)確率和效率方面仍然不能滿足現(xiàn)實(shí)需要。
本文針對(duì)現(xiàn)有短信過濾技術(shù)的不足,設(shè)計(jì)了在手機(jī)終端的短信過濾系統(tǒng),根據(jù)垃圾短信的特點(diǎn)將黑白名單和基于內(nèi)容過濾相結(jié)合。這種過濾方式要求能夠快速地對(duì)短信進(jìn)行分類,并且能夠?qū)崿F(xiàn)用戶對(duì)短信過濾的個(gè)性化要求,使垃圾短信過濾系統(tǒng)具有更好的過濾性能。
Winnow算法是在1987年由Nick Littlestone提出并對(duì)可行性做了嚴(yán)格證明的線性分類算法[4]。當(dāng)時(shí)的目標(biāo)是想找到一種時(shí)空復(fù)雜度僅僅與分類對(duì)象相關(guān)屬性相關(guān)的數(shù)量呈線性相關(guān)的算法。平衡Winnow算法是對(duì)基本W(wǎng)innow算法的一種改進(jìn),該算法具有過濾速度快、性能好、支持反饋更新的優(yōu)點(diǎn),在信息過濾領(lǐng)域有很好的應(yīng)用前景,尤其適合于對(duì)實(shí)時(shí)性要求較高的短信過濾系統(tǒng)。
本文設(shè)計(jì)并實(shí)現(xiàn)了一個(gè)基于平衡Winnow算法的短信內(nèi)容過濾系統(tǒng),對(duì)該算法在短信過濾系統(tǒng)上的應(yīng)用進(jìn)行了詳細(xì)分析。分類器的訓(xùn)練過程分成預(yù)處理、訓(xùn)練、分類和反饋四個(gè)部分。
1 預(yù)處理模塊
預(yù)處理模塊包括中文分詞、特征提取以及短信的向量表示子模塊。
1.1 中文分詞
中文分詞是漢語(yǔ)所特有的研究課題。英語(yǔ)、法語(yǔ)等印歐語(yǔ)種詞與詞之間存在著自然的分割,一般不存在分詞的問題。本系統(tǒng)采用了目前國(guó)內(nèi)較多使用的中科院計(jì)算所開發(fā)的漢語(yǔ)詞法分析系統(tǒng)ICTCLAS[5](Institute of Computing Technology,Chinese Lexical Analysis System)。ICTCLAS 3.0分詞速度單機(jī)996 Kb/s,分詞精度98.45%,API不超過200 KB,各種詞典數(shù)據(jù)壓縮后不到3 MB,是當(dāng)前相對(duì)較好的漢語(yǔ)詞法分析器。

2 構(gòu)造分類器
訓(xùn)練分類器是研究的重點(diǎn),采用Balanced Winnow算法并對(duì)其進(jìn)行改進(jìn)。
2.1 Winnow分類算法
Winnow算法是二值屬性數(shù)據(jù)集上的線性分類算

在平衡Winnow算法中,一旦參數(shù)α、β和閾值θ確定下來(lái)后,將在訓(xùn)練過程中不斷更新權(quán)重向量w+和w-至最適合這組參數(shù)。因此對(duì)參數(shù)的依賴較小,需要手工調(diào)整的參數(shù)不多。
2.3 去除野點(diǎn)
在短信過濾中,短信樣本是由手動(dòng)或自動(dòng)方式收集的,收集的過程中難免會(huì)出錯(cuò),因此短信樣本集中可能存在一些被人為錯(cuò)分的樣本點(diǎn),即野點(diǎn)。這些野點(diǎn)在訓(xùn)練時(shí),會(huì)使得分類器產(chǎn)生嚴(yán)重的抖動(dòng)現(xiàn)象,降低分類器的性能。因此,好的分類器應(yīng)具有識(shí)別野點(diǎn)的能力[11]。
對(duì)于Winnow算法,若樣本中存在野點(diǎn),則野點(diǎn)在訓(xùn)練時(shí)以較大的概率出現(xiàn)在兩分類線之外,且分類錯(cuò)誤。這些野點(diǎn)對(duì)分類器的訓(xùn)練過程產(chǎn)生很大的影響,可能會(huì)造成分類器的“過度學(xué)習(xí)”。因此引入損失函數(shù),按照損失函數(shù)的定義,這些野點(diǎn)損失較大,因此可以通過給損失函數(shù)設(shè)置一個(gè)上界函數(shù)來(lái)處理線性分類器中的野點(diǎn)問題,如圖1所示。
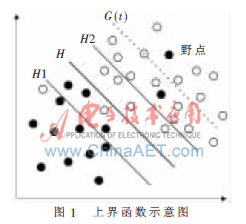
圖1所示為兩類線性可分情況,圖中實(shí)心點(diǎn)和空心點(diǎn)分別表示兩類訓(xùn)練樣本,H為兩類樣本沒有被錯(cuò)誤地分開的分類線,H1和H2分別為平行于分類線H且與分類線H的距離為單位距離的兩條直線。直線G(t)為平衡Winnow算法中第t輪迭代后損失函數(shù)的上界線。該上界線是關(guān)于迭代次數(shù)t的函數(shù),因此可以將該上界線G(t)對(duì)應(yīng)的上界函數(shù)記為g(t)。從圖1可知,在直線G(t)左下側(cè)誤分樣本的損失較少,可以認(rèn)為這些誤分樣本是由于當(dāng)前分類器的性能較低而誤分的;在直線G(t)右上側(cè)誤分的樣本由于在第t輪迭代后損失仍較大,則可以認(rèn)為這些誤分的樣本是野點(diǎn)。根據(jù)線性分類器和野點(diǎn)的性質(zhì)可知,上界函數(shù)g(t)具有以下性質(zhì):
(1)隨著Winnow算法中迭代次數(shù)t的增加,上界函數(shù)g(t)單調(diào)遞減,并且遞減的速率也隨著t的增加而遞減,即上界函數(shù)的導(dǎo)數(shù)g(t)為單調(diào)遞減函數(shù);

在每一輪訓(xùn)練中,若該樣本的G(t)值大于分類線的值,并且超過一定的閾值,且不屬于該類,則判定該樣本具有野點(diǎn)的性質(zhì),應(yīng)當(dāng)在訓(xùn)練集中將該樣本去除,以便提高下一輪訓(xùn)練的準(zhǔn)確性。這樣不僅有效削弱了分類器的抖動(dòng)現(xiàn)象,而且提高了分類器的性能。
3 系統(tǒng)反饋
Winnow是一種在線學(xué)習(xí)的、以錯(cuò)誤為驅(qū)動(dòng)的分類器,適于結(jié)合增量式學(xué)習(xí)來(lái)解決自適應(yīng)問題,實(shí)現(xiàn)用戶的個(gè)性化要求。平衡Winnow算法是基本W(wǎng)innow算法的另外一種形式,同樣具有在線更新能力。在分類器訓(xùn)練過程中,對(duì)錯(cuò)分的短信通過α和β更新類別權(quán)重向量,實(shí)現(xiàn)對(duì)分類器的更新,平衡Winnow算法中w+和w-的雙向調(diào)節(jié),使算法的訓(xùn)練速度更快,適合于對(duì)分類實(shí)時(shí)性要求較高的短信過濾系統(tǒng)。
4 實(shí)驗(yàn)資源及分析與評(píng)價(jià)
本文在自建短信語(yǔ)料庫(kù)的基礎(chǔ)上完成對(duì)比實(shí)驗(yàn),其中正常短信1 892條,垃圾短信270條,將短信語(yǔ)料庫(kù)隨機(jī)分成5等份,其中4份用于訓(xùn)練樣本,1份作為測(cè)試樣本。
4.1 評(píng)價(jià)指標(biāo)
分類系統(tǒng)評(píng)價(jià)指標(biāo)如下,包括兩類短信各自的準(zhǔn)確率(precision)和召回率(recall),由于系統(tǒng)目標(biāo)是垃圾短信過濾,于是增加了針對(duì)垃圾短信的綜合評(píng)價(jià)指標(biāo)(F1):F1=(2×準(zhǔn)確率×召回率)/(準(zhǔn)確率+召回率)。
4.2 實(shí)驗(yàn)結(jié)果分析
(1)實(shí)驗(yàn)1:探討改進(jìn)的特征權(quán)重計(jì)算方法對(duì)實(shí)驗(yàn)結(jié)果的影響。實(shí)驗(yàn)結(jié)果如表1所示。
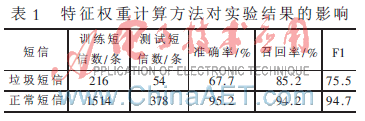
其中測(cè)試樣本中正常短信被誤分為垃圾短信條數(shù)為22條,正常短信召回率為94.2%;垃圾短信被誤分為正常短信8條,準(zhǔn)確率僅為67.7%。


其中測(cè)試樣本中正常短信被誤分為垃圾短信條數(shù)為18條,正常短信召回率為96.1%;而測(cè)試用的垃圾短信正確識(shí)別了44條,準(zhǔn)確率為71.0%。由此可見,參數(shù)對(duì)實(shí)驗(yàn)結(jié)果的影響不大。
(3)實(shí)驗(yàn)3:去除野點(diǎn)對(duì)實(shí)驗(yàn)結(jié)果的影響。實(shí)驗(yàn)結(jié)果如表3所示。
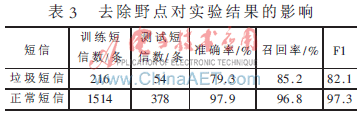
從實(shí)驗(yàn)結(jié)果分析,僅有12條正常短信和8條垃圾短信被錯(cuò)誤分類。通過去除野點(diǎn),發(fā)現(xiàn)不僅緩減了抖動(dòng)現(xiàn)象,而且提高了分類器的分類性能及正常短信的召回率。
Balanced Winnow在訓(xùn)練速度和分類速度上具有較大優(yōu)勢(shì),所以具有更高的實(shí)用價(jià)值,非常適合短信過濾的要求。另外,Winnow作為一種在線學(xué)習(xí)方法,在訓(xùn)練集合不斷擴(kuò)大的情況下能夠快速對(duì)分類器進(jìn)行更新。正是基于Winnow不斷學(xué)習(xí)、不斷調(diào)整的機(jī)制,使其非常適合用戶自己定制需要的分類標(biāo)準(zhǔn)。隨著用戶不斷地反饋調(diào)整,整個(gè)系統(tǒng)會(huì)表現(xiàn)出越來(lái)越好的效果。
參考文獻(xiàn)
[1] 黎路,秦衛(wèi)平.淺析貝葉斯分類方法在手機(jī)垃圾短信過濾系統(tǒng)中的應(yīng)用[J].科技廣場(chǎng),2007(7):76-78.
[2] 金展,范晶.基于樸素貝葉斯和支持向量機(jī)的自適應(yīng)垃圾短信過濾系[J].計(jì)算機(jī)應(yīng)用,2008,28(3):714-718.
[3] 王忠軍.文本分類在短信過濾中的應(yīng)用[D].遼寧:大連理工大學(xué),2006.
[4] LITTLESTONE N. Learning quickly when irrelevant attributes abound: a new linear threshold algorithm. Machine Learning, 1988(2):285-318.
[5] YANG YI MING, PEDERSEN JAN. A comparative study on feature selection in text categorization proceedings of the 14th international conference on machine learning[C]. Nashville: Morgan Kaufmann, 1997:412-420.
[6] 周志軍.中文郵件分類系統(tǒng)的研究及其實(shí)現(xiàn)[D].蘇州:蘇州大學(xué),2005.
[7] 潘文峰,王斌.Winnow算法在垃圾郵件過濾中的應(yīng)用[C].第一屆全國(guó)信息檢索與內(nèi)容安全學(xué)術(shù)會(huì)議論文集,上海,2004.