
文獻(xiàn)標(biāo)識(shí)碼: A
文章編號(hào): 0258-7998(2010)07-0044-04
隨著網(wǎng)絡(luò)發(fā)展和計(jì)算機(jī)的普及應(yīng)用,人們對(duì)存儲(chǔ)系統(tǒng)的性能要求越來越高,尤其是關(guān)鍵事務(wù)的應(yīng)用。廉價(jià)冗余磁盤陣列(RAID)[1,2,3]采用分條和冗余的方法提高了存儲(chǔ)系統(tǒng)的容量、速度和可靠性,已成為高性能數(shù)據(jù)存儲(chǔ)的首選結(jié)構(gòu)。磁盤陣列控制器是磁盤陣列的核心,多數(shù)緩存預(yù)取策略、緩存置換策略、磁盤聚合寫策略、數(shù)據(jù)冗余計(jì)算、數(shù)據(jù)備份與重建均由磁盤陣列控制器完成。磁盤接口控制器主要負(fù)責(zé)磁盤組的管理及讀寫磁盤操作的具體實(shí)現(xiàn)。
流水線技術(shù)[4,5,6]是計(jì)算機(jī)技術(shù)中同時(shí)具備空間并行性和時(shí)間并行性的技術(shù),它把一個(gè)順序處理的過程分解成若干個(gè)子處理過程,每個(gè)子處理過程能在專用的獨(dú)立模塊上有效地并行工作。本文通過對(duì)磁盤接口控制器的流水線設(shè)計(jì),提高了磁盤接口的吞吐率。較高的磁盤接口控制器吞吐率可以降低平均訪問時(shí)間,使復(fù)雜有效的預(yù)取和置換算法方便地應(yīng)用于磁盤陣列,提高緩存的命中率,從而提高磁盤陣列的整體性能。
1 現(xiàn)有磁盤接口控制器設(shè)計(jì)
磁盤接口設(shè)計(jì)方式主要有2種:(1)使用通用處理器充當(dāng)磁盤接口控制器,通過在處理器上運(yùn)行相應(yīng)的軟件完成來自控制器上其他處理器的磁盤操作請(qǐng)求。這種方式最大的優(yōu)點(diǎn)就是實(shí)現(xiàn)簡(jiǎn)單,但缺點(diǎn)也很明顯。每一個(gè)新的磁盤操作請(qǐng)求必須在前一磁盤操作請(qǐng)求完成之后才能啟動(dòng),并且需要占用大量處理器時(shí)間的異或操作也由該處理器承擔(dān),這使得每一次磁盤操作的時(shí)間太長(zhǎng),進(jìn)而使得磁盤接口控制器的平均磁盤訪問時(shí)間過長(zhǎng),吞吐率較低,尤其是降級(jí)模式讀操作和磁盤寫操作。(2)把需要長(zhǎng)時(shí)間占用通用處理器的異或操作獨(dú)立出來,由異或?qū)S肁SIC完成此功能,其他操作仍由通用處理器運(yùn)行相應(yīng)的軟件完成。現(xiàn)在的中低端磁盤陣列常采用這種方式。使用專用的ASIC分擔(dān)所有的異或操作,雖然可以部分減少需要異或操作的磁盤訪問時(shí)間,如降級(jí)模式讀操作和磁盤寫操作,但新的磁盤操作也必須在前一磁盤操作完成之后才會(huì)啟動(dòng),磁盤操作過程也是按順序執(zhí)行的,整體的吞吐率仍不是很高。所以這種方式不適合于高端磁盤陣列的需要。
2 并行流水線設(shè)計(jì)模型
與其他磁盤接口不同,磁盤陣列中的磁盤接口除了簡(jiǎn)單地完成磁盤的讀寫外,還需要完成數(shù)據(jù)塊的邏輯地址到實(shí)際磁盤物理地址的映射和保證數(shù)據(jù)塊在磁盤陣列中可靠地存儲(chǔ)。根據(jù)所有磁盤操作請(qǐng)求完成的特點(diǎn),磁盤接口操作被劃分為4個(gè)子任務(wù),每一個(gè)子任務(wù)由一個(gè)獨(dú)立的模塊來實(shí)現(xiàn)。在具體實(shí)現(xiàn)時(shí),這些模塊可以在同一芯片內(nèi),也可以在不同芯片中。這4個(gè)模塊分別是:共享緩存操作模塊、異或計(jì)算操作模塊、地址映射模塊和磁盤操作模塊。共享緩存操作模塊根據(jù)給定的共享緩存數(shù)據(jù)塊地址讀寫數(shù)據(jù)塊;異或計(jì)算操作模塊是在降級(jí)模式讀磁盤操作和正常模式下磁盤寫操作時(shí),完成異或計(jì)算;地址映射模塊主要實(shí)現(xiàn)磁盤數(shù)據(jù)塊的放置策略[7],將主機(jī)訪問磁盤陣列的地址,如邏輯塊地址LBA、邏輯單元號(hào)LUN,轉(zhuǎn)換為實(shí)際的磁盤號(hào)、柱面號(hào)、磁道號(hào)、扇區(qū)號(hào)等;磁盤操作模塊主要是根據(jù)地址映射模塊操作后的結(jié)果完成磁盤的讀寫,包括相應(yīng)的協(xié)議轉(zhuǎn)換。圖1是同一芯片實(shí)現(xiàn)各模塊的磁盤接口控制器的結(jié)構(gòu)框圖。
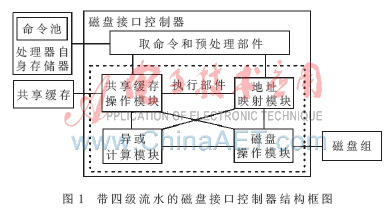
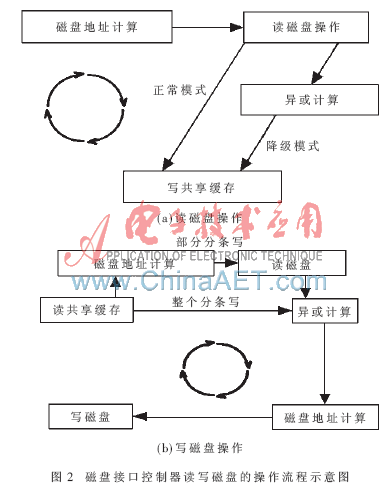
實(shí)際上每個(gè)磁盤操作執(zhí)行的這四個(gè)模塊的次序和次數(shù)是不定的。讀磁盤操作的數(shù)據(jù)流方向與寫磁盤操作的數(shù)據(jù)流方向是相反的,執(zhí)行這四個(gè)模塊的順序也是相反的。讀寫磁盤操作的各模塊執(zhí)行順序如圖2所示。一個(gè)磁盤操作請(qǐng)求只要在其執(zhí)行的第一個(gè)模塊空閑時(shí)便可啟動(dòng),多個(gè)磁盤操作請(qǐng)求可以重疊的方式被磁盤接口控制器處理。理想情況下,磁盤接口控制器可以同時(shí)處理4個(gè)磁盤操作請(qǐng)求。
3 關(guān)鍵問題分析
磁盤接口的并行流水線設(shè)計(jì)模型在具體實(shí)現(xiàn)時(shí)有2個(gè)問題需要解決:(1)如何控制磁盤操作請(qǐng)求在模塊間執(zhí)行順序和執(zhí)行次數(shù)。因?yàn)樵诰唧w執(zhí)行時(shí)有3種情況:4個(gè)模塊每個(gè)模塊執(zhí)行1次、執(zhí)行部分模塊多次和只執(zhí)行3個(gè)模塊。(2)需要操作的數(shù)據(jù)塊如何在模塊間進(jìn)行傳遞。
3.1 任務(wù)通信
要控制一個(gè)磁盤操作請(qǐng)求如何在模塊間進(jìn)行處理,一種有效的方式就是讓每個(gè)模塊都知道這個(gè)磁盤操作請(qǐng)求的具體需求。為此,一個(gè)用來描述磁盤操作請(qǐng)求的特殊的數(shù)據(jù)結(jié)構(gòu)被引入,其結(jié)構(gòu)如圖3。每一個(gè)磁盤操作請(qǐng)求都有一個(gè)磁盤操作數(shù)據(jù)塊結(jié)構(gòu),磁盤接口控制器預(yù)處理部件每收到一個(gè)來自控制器上的其他處理器的磁盤操作請(qǐng)求便產(chǎn)生相應(yīng)的操作數(shù)據(jù)塊結(jié)構(gòu),并根據(jù)其操作類型放入相應(yīng)的模塊任務(wù)池中。

每一個(gè)模塊都有一個(gè)任務(wù)池來存放操作數(shù)據(jù)塊結(jié)構(gòu)。模塊總是從自己的任務(wù)池中取操作數(shù)據(jù)塊結(jié)構(gòu),然后根據(jù)數(shù)據(jù)塊結(jié)構(gòu)中的說明進(jìn)行相應(yīng)的處理,處理完成后再根據(jù)數(shù)據(jù)塊結(jié)構(gòu)中的說明正確地放入到下一個(gè)模塊的任務(wù)池中。如某個(gè)模塊處理后磁盤操作請(qǐng)求已完成,則該模塊不再向其他模塊傳遞該數(shù)據(jù)塊結(jié)構(gòu),直接將其刪除。這種方式簡(jiǎn)單有效,易于編碼實(shí)現(xiàn)。
3.2 緩沖管理
在RAID5中,計(jì)算奇偶校驗(yàn)塊需要同分條中的4個(gè)數(shù)據(jù)塊,因此異或計(jì)算模塊需要一個(gè)較大的緩沖來存放數(shù)據(jù)塊。其他模塊也至少需要一個(gè)數(shù)據(jù)塊大小的緩沖存放當(dāng)前操作的數(shù)據(jù)塊。一個(gè)雙隊(duì)列的生產(chǎn)者-消費(fèi)者模型(如圖4)被用來實(shí)現(xiàn)高效緩沖管理。
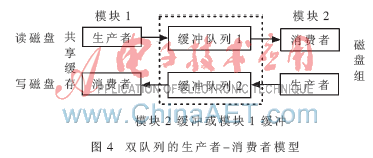
這2個(gè)隊(duì)列的長(zhǎng)度不是固定的,是根據(jù)每個(gè)操作方向上的請(qǐng)求數(shù)量動(dòng)態(tài)調(diào)整。在圖4中,若讀磁盤操作請(qǐng)求較多則增加緩沖隊(duì)列1的長(zhǎng)度;若寫磁盤操作請(qǐng)求較多則增加緩沖隊(duì)列2的長(zhǎng)度。2個(gè)隊(duì)列的總大小總是小于或等于整個(gè)緩沖的大小。每一個(gè)隊(duì)列都是循環(huán)隊(duì)列,生產(chǎn)者總是把新的數(shù)據(jù)塊放到隊(duì)列的尾部;只要該隊(duì)列不為空,消費(fèi)者總是從隊(duì)列的頭部取走數(shù)據(jù)塊。
4 磁盤接口控制器系統(tǒng)設(shè)計(jì)與實(shí)現(xiàn)
4.1 應(yīng)用環(huán)境
本控制器應(yīng)用在RAID控制器的系統(tǒng)總線與連接硬盤的SAS總線之間,主要根據(jù)RAID控制器中的主處理器命令進(jìn)行可靠快速的磁盤數(shù)據(jù)塊的讀寫。
圖5描述了本控制器典型應(yīng)用環(huán)境。深色部分為本控制器,淺色部分是外部環(huán)境。
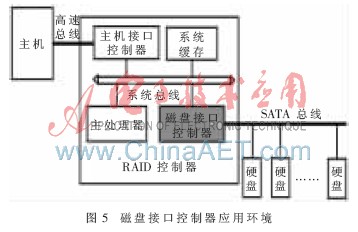
從應(yīng)用環(huán)境中可以看出,磁盤接口控制器是連接RAID控制器與硬盤組的橋梁。磁盤接口控制器通過SAS總線連接多個(gè)硬盤,通過系統(tǒng)總線(如PCI總線)連接到RAID控制器整個(gè)系統(tǒng)中。
4.2 總體結(jié)構(gòu)與各功能模塊
磁盤接口控制器包括5個(gè)大的功能模塊:磁盤命令預(yù)處理模塊、共享緩存操作模塊、地址映射模塊、異或計(jì)算模塊、磁盤操作模塊。由于采用的是FPGA測(cè)試和驗(yàn)證,對(duì)成熟的模塊,如PCI模塊、SATA模塊、DMA模塊直接使用FPGA中的資源。四級(jí)流水的磁盤接口控制器總體結(jié)構(gòu)如圖6。
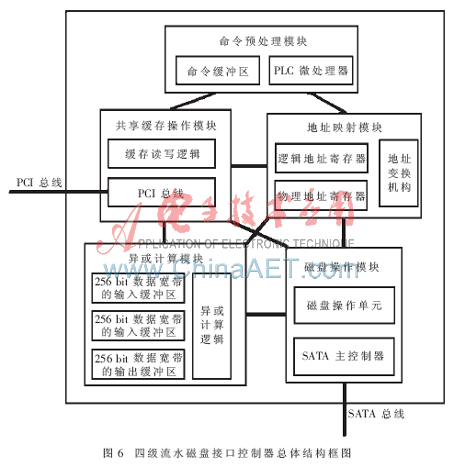
4.2.1 命令預(yù)處理模塊
命令預(yù)處理模塊主要根據(jù)RAID控制器中主處理器的命令決定該命令的操作流程,不同的讀寫方式在不同的工作模式下其數(shù)據(jù)流程不一樣。命令預(yù)處理模塊主要包括命令緩沖區(qū)和PLC微處理器。命令緩沖區(qū)主要接收RAID控制器中主處理器發(fā)過來的命令,命令包括:2種工作模式命令(正常模式和降級(jí)模式)、2種分條讀寫方式(完整分條和部分分條)、磁盤寫命令(首個(gè)邏輯塊地址LBA,邏輯塊數(shù))、磁盤讀命令(首個(gè)邏輯塊地址LBA,邏輯塊數(shù))。PLC微處理器是一個(gè)8 bit RISC微處理器,也是整個(gè)控制器的核心,負(fù)責(zé)解析磁盤操作命令和控制命令的整個(gè)執(zhí)行過程,包括其他4個(gè)功能模塊的任務(wù)分派和協(xié)調(diào)。
4.2.2 共享緩存操作模塊
RAID控制器包含有大容量的SDRAM作為磁盤陣列的緩存,所有異或操作的數(shù)據(jù)塊都存放在緩存中。共享緩存操作模塊主要完成緩存數(shù)據(jù)塊的讀寫,包括PCI總線和讀寫控制邏輯。PCI總線使用FPGA芯片自身所帶的邏輯,讀寫控制邏輯主要根據(jù)命令預(yù)處理模塊發(fā)過來的命令產(chǎn)生相應(yīng)的讀寫時(shí)序并解決總線沖突。
4.2.3 地址映射模塊
由于RAID控制器中主處理器操作的都是邏輯地址,地址映射模塊完成的是邏輯地址到物理盤號(hào)、柱面號(hào)、扇區(qū)號(hào)的映射。地址映射模塊包括邏輯地址寄存器和物理地址寄存器,并包括一個(gè)地址變換機(jī)構(gòu)。地址變換機(jī)構(gòu)是一個(gè)快速哈希變換機(jī)構(gòu),輸入的邏輯地址通過快速哈希變換和相應(yīng)的查表獲得實(shí)際的物理地址。
4.2.4 異或操作模塊
異或操作模塊是RAID保證數(shù)據(jù)可靠性的基礎(chǔ),主要完成異或計(jì)算。這個(gè)模塊比較簡(jiǎn)單,包括2個(gè)數(shù)據(jù)輸入寄存器和一個(gè)輸出寄存器,所有寄存器的位數(shù)是256 bit,一次異或操作可完成2個(gè)16 B數(shù)據(jù)的操作。一個(gè)分條的異或操作通過多次執(zhí)行異或計(jì)算邏輯來實(shí)現(xiàn)。
4.2.5 磁盤操作模塊
磁盤操作模塊主要完成實(shí)際磁盤的數(shù)據(jù)讀寫,該模塊通過SATA總線連接多個(gè)磁盤。該模塊主要包括SATA主控制器和磁盤操作單元,SATA主控制器使用FPGA芯片本身自帶的邏輯,磁盤操作單元是要實(shí)現(xiàn)的邏輯,主要接收和執(zhí)行PLC微處理器發(fā)過來的讀寫命令,將數(shù)據(jù)從磁盤讀到共享緩沖區(qū)或把共享緩沖區(qū)的數(shù)據(jù)寫到對(duì)應(yīng)的磁盤上。
4.3 RTL設(shè)計(jì)與實(shí)現(xiàn)
根據(jù)前述的系統(tǒng)結(jié)構(gòu)和各功能模塊,對(duì)本控制器進(jìn)行了RTL設(shè)計(jì)和實(shí)現(xiàn)[8-10]。這里以復(fù)位控制、輸入控制為例說明其實(shí)現(xiàn)過程。
復(fù)位控制是IC設(shè)計(jì)中一個(gè)基本而重要的問題。綜合同步復(fù)位和異步復(fù)位的優(yōu)缺點(diǎn),對(duì)復(fù)位控制電路的設(shè)計(jì)采用“異步復(fù)位,同步撤離”的策略,使用2個(gè)觸發(fā)器級(jí)聯(lián),消除亞穩(wěn)態(tài)的影響。同時(shí),為了濾除異步復(fù)位中毛刺的影響,在復(fù)位端口用一個(gè)二輸入與非門和一個(gè)緩沖器設(shè)計(jì)了一級(jí)濾除毛刺的電路,這樣就可以得到一個(gè)干凈的復(fù)位信號(hào)。
在本控制器的5個(gè)子模塊中都存在數(shù)據(jù)的輸入和輸出。不同的模塊只需要配置不同大小的FIFO。輸入控制的設(shè)計(jì)主要以一個(gè)異步FIFO作為彈性緩沖器,該FIFO的大小是可配置的。另外還有一部分邏輯用來生成輸出數(shù)據(jù)有效指示信號(hào),這個(gè)指示信號(hào)采集到的FIFO讀信號(hào)有效時(shí)即為有效。
5 FPGA測(cè)試與實(shí)驗(yàn)結(jié)果
經(jīng)過RTL設(shè)計(jì)、仿真及相應(yīng)的EDA驗(yàn)證,實(shí)現(xiàn)了流水線的磁盤接口控制器并對(duì)該控制器進(jìn)行了FPGA測(cè)試。測(cè)試過程中,使用的測(cè)試平臺(tái)板為Xilinx ML505測(cè)試平臺(tái),主芯片為Virtex-5 FPGA,在不加SATA多路器的情況下可同時(shí)連接4個(gè)SATA硬盤。
為了進(jìn)行性能分析和比較,除了流水線的磁盤接口控制器外,同樣基于Virtex-5 FPGA并使用MIPS CPU核的磁盤接口控制器也被實(shí)現(xiàn)。基于MIPS CPU核的磁盤接口控制器在Virtex-5 FPGA上可以很方便地實(shí)現(xiàn),因?yàn)閂irtex-5 FPGA本身自帶MIPS CPU核和SATA控制器。只需要實(shí)現(xiàn)專用異或邏輯及在MIPS CPU核實(shí)現(xiàn)地址映射和讀寫控制即可。
測(cè)試過程中使用的磁盤為高速SATA磁盤,對(duì)應(yīng)的磁盤參數(shù)見表1。這里只對(duì)磁盤接口控制器進(jìn)行測(cè)試,對(duì)磁盤陣列控制器中主處理器產(chǎn)生的磁盤操作命令通過模擬產(chǎn)生。命令到達(dá)的方式服從泊松分布,工作為正常工作模式,讀寫方式為隨機(jī)產(chǎn)生。在讀磁盤請(qǐng)求數(shù)與寫磁盤請(qǐng)求數(shù)相等的情況下,其實(shí)驗(yàn)結(jié)果如圖7所示。由圖可知,在任何磁盤請(qǐng)求到達(dá)率情況下,基于流水線的磁盤接口控制器的吞吐率都比基于MIPS的吞吐率高。在其他讀寫請(qǐng)求比率的條件下,也可以得到類似的結(jié)果。
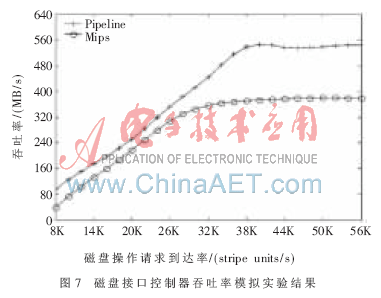
磁盤陣列控制器是磁盤陣列的核心,直接決定了整個(gè)磁盤陣列的性能。本文通過研究現(xiàn)有磁盤接口設(shè)計(jì)和磁盤接口完成的功能,提出了一種磁盤接口的并行流水線設(shè)計(jì)模型,并對(duì)該模型實(shí)現(xiàn)過程中的模塊間的通信問題和模塊間的緩沖管理問題進(jìn)行了相應(yīng)的分析和設(shè)計(jì)。實(shí)驗(yàn)結(jié)果表明,在各種情況下,磁盤接口的吞吐率都有提高,在高寫請(qǐng)求率和重負(fù)載兩種情況下尤為顯著。較高的磁盤接口控制器的吞吐率可以降低平均訪問時(shí)間,使復(fù)雜有效的預(yù)取和置換算法方便地應(yīng)用于磁盤陣列,提高緩存的命中率,從而提高磁盤陣列的整體性能。
參考文獻(xiàn)
[1] SCHWABE E.J.,SUTHERLAND I.M.,Improved paritydeclustered data layouts for disk arrays.J. Comput. Syst. Sci.1996,53(3):328-343.
[2] STOCKMEYER L..Parallelism in parity-declustered layouts for disk arrays.Technical Report RJ9915,IBM Almaden Research Center,1994.
[3] ZHOU K,ZHANG J L,F(xiàn)ENG D,et al.Cache prefetching adaptive policy based on access pattern.Proceedings of 2002 International Conference on Machine Learning and Cybernetics,2002(1):496-500.
[4] WEI-KENG L,ALOCK C,DONALD W,et al.Performance evaluation of a parallel pipeline computational model for space-time adaptive processing. The Journal of Supercomputing,2005(31):137-160.
[5] WEI-KENG L,ALOCK C,DONALD W,et al.I/O implementation and evaluation of parallel pipelined STAP on high performance computers. Lecture Notes in Computer Science,2004,17(45):354-358.
[6] 姚念民,鄭名揚(yáng),鞠九濱.基于流水線的高性能Web服務(wù)器[J],軟件學(xué)報(bào),2003,14(6):1127-1130.
[7] SCHWABE E J,SUTHERLAND I M,Efficient data mappings for parity-declustered data layouts. Theoretical Computer Science,2004,325(3):391-407.
[8] 武杰,喬崇,張俊杰,等.MIPS系統(tǒng)中北橋的FPGA設(shè)計(jì)[J].小型微型計(jì)算機(jī)系統(tǒng),2004,25(11):2028-203.
[9] 苗勝.硬盤數(shù)據(jù)加密系統(tǒng)的設(shè)計(jì)及其FPGA實(shí)現(xiàn)[J].計(jì)算機(jī)應(yīng)用研究,2004(10):221-223.
[10] 葉頂勝.基于FPGA的Serial ATA1.0a設(shè)備IP CORE設(shè)計(jì)[D].南充:西南石油大學(xué),2006.