
??? 摘 要: 針對(duì)當(dāng)前基于DSP、ARM等硬核處理器設(shè)計(jì)的嵌入式說(shuō)話人識(shí)別" title="說(shuō)話人識(shí)別">說(shuō)話人識(shí)別系統(tǒng)訓(xùn)練和辨認(rèn)時(shí)間長(zhǎng)等缺陷,根據(jù)MFCC提取過(guò)程的特點(diǎn)與遺傳聚類" title="聚類">聚類算法中適應(yīng)度計(jì)算的原理,提出一種基于SoPC平臺(tái)與矢量量化" title="矢量量化">矢量量化原理的說(shuō)話人識(shí)別系統(tǒng)" title="說(shuō)話人識(shí)別系統(tǒng)">說(shuō)話人識(shí)別系統(tǒng)實(shí)現(xiàn)方案。經(jīng)測(cè)試,該實(shí)現(xiàn)方案在保證識(shí)別率前提下,可有效提高訓(xùn)練與識(shí)別速度。
??? 關(guān)鍵詞: 說(shuō)話人識(shí)別 ?矢量量化 ?遺傳算法" title="遺傳算法">遺傳算法 ?適應(yīng)度 ?SOPC
?
??? 說(shuō)話人識(shí)別(Speaker Recognition)又稱話者識(shí)別,是指根據(jù)特定說(shuō)話人語(yǔ)音波形中反映生理和行為等特征的語(yǔ)音參數(shù)來(lái)對(duì)說(shuō)話人身份進(jìn)行識(shí)別[1]。說(shuō)話人識(shí)別技術(shù)作為一種非接觸性識(shí)別技術(shù),在保安、司法、軍事和信息服務(wù)等領(lǐng)域都有廣泛的應(yīng)用前景。
??? 文本無(wú)關(guān)的說(shuō)話人識(shí)別方法是當(dāng)前說(shuō)話人識(shí)別技術(shù)的研究重點(diǎn)。常用的識(shí)別算法有:基于矢量量化VQ(Vector Quantization)的方法[2]、基于HMM的方法、基于ANN的方法等。其中,基于VQ的說(shuō)話人識(shí)別方法無(wú)需考慮復(fù)雜的統(tǒng)計(jì)模型和時(shí)間歸整問(wèn)題,運(yùn)算過(guò)程簡(jiǎn)單,在說(shuō)話人識(shí)別領(lǐng)域被廣泛應(yīng)用。
??? 基于VQ的說(shuō)話人識(shí)別通常采用MFCC參數(shù),因?yàn)镸FCC是一種基于人耳對(duì)語(yǔ)音頻率的非線形感知特征的描述參數(shù)[3],在說(shuō)話人識(shí)別中,其性能優(yōu)于LPC、LPCC等參數(shù)。
??? SoPC技術(shù)是一種基于FPGA解決方案的SoC,由美國(guó)ALTERA公司于2000年提出[4]。基于SoPC平臺(tái)的開(kāi)發(fā)結(jié)合了FPGA靈活可編程與片上NiosII軟核處理器的用戶可配置等特點(diǎn)。在實(shí)現(xiàn)某功能時(shí),可編寫(xiě)C/C++程序運(yùn)行于NiosII處理器實(shí)現(xiàn),也可設(shè)計(jì)硬件模塊實(shí)現(xiàn),不占用CPU,起到了硬件加速效果。本系統(tǒng)綜合兩種實(shí)現(xiàn)思路,采用高性價(jià)比的Cyclone II 2C35系列FPGA實(shí)現(xiàn)。經(jīng)驗(yàn)證,該說(shuō)話人識(shí)別系統(tǒng)識(shí)別率高,實(shí)時(shí)性優(yōu)于硬核處理器系統(tǒng),應(yīng)用前景良好。
1 基于矢量量化的說(shuō)話人識(shí)別算法
??? 說(shuō)話人識(shí)別中,先需要建立表征用戶語(yǔ)音特征的碼書(shū),碼書(shū)由從用戶的訓(xùn)練語(yǔ)音中提取的MFCC聚類而成。識(shí)別階段,系統(tǒng)先采集一段測(cè)試者的語(yǔ)音,提取出MFCC,再與用戶VQ碼書(shū)匹配,如果失真測(cè)度達(dá)到一定范圍,則可認(rèn)為測(cè)試者即為碼書(shū)表征的用戶。
??? 建立碼書(shū)時(shí),先由系統(tǒng)采集一段用戶語(yǔ)音,經(jīng)分幀與MFCC提取后可得到N 個(gè)M 維原始矢量On={o1,o2,?
oM}(n=1,2,3…,N ),其中每一矢量相當(dāng)于M維空間中的一點(diǎn)。然后將N 個(gè)原始矢量在M 維空間作K聚類,得到的聚類結(jié)果即是表征說(shuō)話人語(yǔ)音特征的K容量碼書(shū)。其中,用于構(gòu)建碼書(shū)的N幀M維MFCC稱為訓(xùn)練序列。
??? 根據(jù)實(shí)驗(yàn)驗(yàn)證并綜合考慮系統(tǒng)資源與識(shí)別性能,參數(shù)設(shè)定總幀數(shù)M一般取256或512,碼書(shū)大小K取64,M取12或16(若加上差分參數(shù)可擴(kuò)至24、36等)。由于是在高維空間聚類,普通聚類方法易導(dǎo)致結(jié)果陷入局部最優(yōu)點(diǎn),因而選擇具有全局搜索性能的遺傳算法進(jìn)行聚類,可得到最優(yōu)碼書(shū)。針對(duì)說(shuō)話人識(shí)別設(shè)計(jì)的算法,具體細(xì)節(jié)如下:
??? 群體規(guī)模:30
??? 編碼方式:二進(jìn)制編碼
??? 交叉變異:無(wú)回放隨機(jī)選擇策略選擇單點(diǎn)交叉,交叉概率PC =90%,變異概率PM =10%
??? 遷移間隔:每運(yùn)行2代遷移一次
??? 選擇(替換) 輪盤(pán)賭方式+10%最優(yōu)個(gè)體保存
??? 個(gè)體適應(yīng)度計(jì)算公式為:
????
??? X 為訓(xùn)練序列,Y 為個(gè)體,d(Xj,Yi)是訓(xùn)練序列中某點(diǎn)Xj與個(gè)體中某點(diǎn)Yi之間的歐氏距離。
停止條件為當(dāng)遺傳代數(shù)達(dá)到規(guī)定閾值或最近三代最優(yōu)個(gè)體適應(yīng)度比值達(dá)一定閾值。
??? 同時(shí),在遺傳過(guò)程中可每隔若干代執(zhí)行一次K-means聚類以加快收斂速度。遺傳結(jié)束后,最末代得到的最優(yōu)適應(yīng)度個(gè)體即為用戶的VQ語(yǔ)音碼書(shū)。
??? 識(shí)別階段,系統(tǒng)先采集一段測(cè)試者的語(yǔ)音,提取出MFCC,稱為測(cè)試序列,然后與用戶VQ碼書(shū)比較。如果匹配度達(dá)到一定范圍,則可認(rèn)為測(cè)試者即為碼書(shū)表征的用戶。
2 系統(tǒng)方案與實(shí)現(xiàn)
??? 說(shuō)話人識(shí)別系統(tǒng)主要有四項(xiàng)任務(wù):(1)說(shuō)話人語(yǔ)音采集與有效語(yǔ)音提取;(2)語(yǔ)音幀MFCC提取;(3)通過(guò)遺傳算法計(jì)算得到說(shuō)話人語(yǔ)音VQ碼書(shū);(4)在說(shuō)話人識(shí)別時(shí)實(shí)時(shí)采集測(cè)試者語(yǔ)音并提取MFCC,然后與已有碼書(shū)進(jìn)行匹配并作出決策。
??? SoPC設(shè)計(jì)中,根據(jù)需要可在單FPGA內(nèi)配置多CPU。本系統(tǒng)配置了雙CPU,兩塊CPU均以同一片SDRAM為運(yùn)行內(nèi)存,由Avalon總線模塊提供仲裁機(jī)制實(shí)現(xiàn)雙CPU對(duì)SDRAM的分時(shí)訪問(wèn)。系統(tǒng)除含有必要的儲(chǔ)存器與語(yǔ)音輸入接口外,還外接PS2鍵盤(pán)與LCD、VGA顯示器等人機(jī)交互設(shè)備,整體設(shè)計(jì)框圖如圖1所示。
?
????????????????????????? 
?
2.1 語(yǔ)音采集與有效語(yǔ)音提取
??? 語(yǔ)音A/D轉(zhuǎn)換由WOLFSON公司的WM8751語(yǔ)音芯片實(shí)現(xiàn)。系統(tǒng)上電后,F(xiàn)PGA內(nèi)的用戶制定配置模塊以I2C時(shí)序配置該芯片工作模式為8kHz采樣頻率與16bit采樣深度,采樣得到的語(yǔ)音數(shù)據(jù)以I2S時(shí)序串行傳輸?shù)紽PGA芯片中。
??? 語(yǔ)音數(shù)據(jù)由采樣芯片傳至FPGA芯片端口后,由用戶制定硬件采集模塊負(fù)責(zé)接收,該模塊還負(fù)責(zé)計(jì)算本次收到數(shù)據(jù)的前向差值與平方值,然后將接收的數(shù)據(jù)、前向差值和平方值通過(guò)Avalon總線傳至SRAM。這樣,該模塊在實(shí)現(xiàn)數(shù)據(jù)采集的同時(shí),完成部分過(guò)零率與短時(shí)能量計(jì)算的工作。SRAM中有兩塊地址固定的數(shù)據(jù)存儲(chǔ)區(qū)A與B。當(dāng)采樣模塊采集滿A區(qū)并通知CPU讀數(shù)后,如果語(yǔ)音芯片繼續(xù)傳來(lái)數(shù)據(jù),采樣模塊將接收的數(shù)據(jù)存儲(chǔ)到B區(qū)中,這樣CPU讀A區(qū)不會(huì)與模塊寫(xiě)B(tài)區(qū)產(chǎn)生沖突,B區(qū)寫(xiě)滿后模塊與CPU以相同方式工作。
??? CPU采集到語(yǔ)音數(shù)據(jù)后進(jìn)一步作分幀處理與靜音檢測(cè),經(jīng)檢測(cè)為有效語(yǔ)音的數(shù)據(jù)幀予以保留。每一語(yǔ)音幀根據(jù)式(2)、式(3)計(jì)算短時(shí)能量與過(guò)零率,然后通過(guò)雙門(mén)限法檢測(cè)該段數(shù)據(jù)是否為有效語(yǔ)音。式(2)、式(3)中,N為每幀采樣點(diǎn)數(shù)。由于每個(gè)采樣點(diǎn)的前向差值與平方值已由數(shù)據(jù)接收模塊算出,CPU只需提出這些值按幀累加即可。檢測(cè)為有效語(yǔ)音的數(shù)據(jù)幀放入SDRAM中的循環(huán)緩沖區(qū)中,當(dāng)有效語(yǔ)音數(shù)據(jù)足量后,CPU停止采集模塊工作。
???  ???
???
?
2.2 語(yǔ)音MFCC參數(shù)運(yùn)算
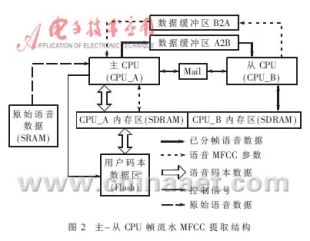
??? 語(yǔ)音采集與檢測(cè)過(guò)程中,若采用筆者設(shè)計(jì)的主-從CPU幀流水MFCC提取結(jié)構(gòu)(圖2),可使語(yǔ)音和MFCC提取在雙CPU上同步進(jìn)行,從而提高系統(tǒng)效率。雙CPU結(jié)構(gòu)中,主CPU完成采集與檢測(cè),從CPU實(shí)現(xiàn)MFCC提取。該結(jié)構(gòu)工作過(guò)程如下:
??????
?????????????????????????? 
?
??? 當(dāng)主CPU采集到一段原始語(yǔ)音數(shù)據(jù)后,對(duì)該段數(shù)據(jù)進(jìn)行分幀與檢測(cè),然后將有效語(yǔ)音數(shù)據(jù)按幀寫(xiě)至緩沖區(qū)A2B,并通過(guò)郵箱通知從CPU。若主CPU在下一段原始語(yǔ)音數(shù)據(jù)到來(lái)前通過(guò)郵箱得知緩沖區(qū)B2A有從CPU處理完成的MFCC,則將其讀出至主CPU內(nèi)存中。由于主CPU對(duì)MFCC的接收是查詢,對(duì)語(yǔ)音數(shù)據(jù)的接收是中斷,故收發(fā)數(shù)據(jù)不會(huì)產(chǎn)生沖突。由郵箱消息啟動(dòng)從CPU,一旦獲悉有新語(yǔ)音數(shù)據(jù)到來(lái),即從緩沖區(qū)A2B中讀取數(shù)據(jù)到從CPU內(nèi)存。當(dāng)從CPU運(yùn)算出MFCC,將MFCC寫(xiě)至B2A緩沖區(qū),然后發(fā)送信息至郵箱。從CPU的內(nèi)存區(qū)內(nèi)設(shè)有MFCC緩沖區(qū),若B2A內(nèi)的數(shù)據(jù)未被主CPU讀完,而新MFCC已經(jīng)提取完成,則從CPU將新MFCC暫存在緩沖區(qū)中,待B2A中的數(shù)據(jù)被讀完后再將新MFCC寫(xiě)入。主從CPU進(jìn)行通信的郵箱由硬件邏輯資源構(gòu)成,雙CPU可通過(guò)該郵箱同時(shí)收發(fā)信息。
??? 主-從CPU流水結(jié)構(gòu)串行處理語(yǔ)音數(shù)據(jù)可有效加速M(fèi)FCC參數(shù)的提取,相當(dāng)于數(shù)據(jù)在雙CPU系統(tǒng)中以幀為單位作流水處理,使語(yǔ)音采集與MFCC參數(shù)提取同步進(jìn)行。
2.3 適應(yīng)度計(jì)算硬件結(jié)構(gòu)及遺傳算法實(shí)現(xiàn)
??? MFCC參數(shù)提取完成,設(shè)得到N幀M維MFCC。根據(jù)前面討論,碼書(shū)容量選擇為F=64,若取M=12并加上一階差分參數(shù),N=512,遺傳個(gè)體T=30;根據(jù)式(1)估算,執(zhí)行一代群體適應(yīng)度計(jì)算至少需作(2M)×N × T × F =23592960≈24M次乘法和48M次加減法,加上遺傳動(dòng)作,執(zhí)行一代遺傳的總步驟更遠(yuǎn)遠(yuǎn)超過(guò)運(yùn)算次數(shù)。實(shí)驗(yàn)可知,遺傳收斂代數(shù)大約為40~150,因此直接用軟件程序?qū)崿F(xiàn)必導(dǎo)致耗時(shí)過(guò)長(zhǎng)。
??? 根據(jù)適應(yīng)度計(jì)算的算法特點(diǎn),在設(shè)計(jì)中采用并行流水結(jié)構(gòu)實(shí)現(xiàn)適應(yīng)度計(jì)算,可大大減少耗時(shí)。根據(jù)式(1),K維空間中兩點(diǎn)之間距離的計(jì)算可采用K路并行運(yùn)算器實(shí)現(xiàn),得到的K路輸出并行進(jìn)入K輸入加法器,再作開(kāi)方處理即得到兩點(diǎn)距離,然后通過(guò)比較得到式(1)中的最短距離值![]() 并累加,再將此距離累加便可得到適應(yīng)度的倒數(shù)。這一系列計(jì)算可通過(guò)流水硬件結(jié)構(gòu)實(shí)現(xiàn)。
并累加,再將此距離累加便可得到適應(yīng)度的倒數(shù)。這一系列計(jì)算可通過(guò)流水硬件結(jié)構(gòu)實(shí)現(xiàn)。
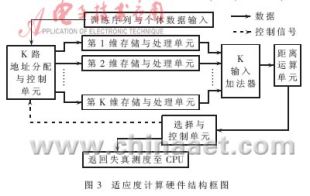
??? 根據(jù)該思路設(shè)計(jì)的適應(yīng)度計(jì)算的硬件結(jié)構(gòu)框圖如圖3所示。由圖3可知,CPU將訓(xùn)練序列與單個(gè)個(gè)體通過(guò)地址分配單元按維寫(xiě)入K路數(shù)據(jù)存儲(chǔ)與運(yùn)算單元,由選擇與控制單元啟動(dòng)運(yùn)算,K路并行運(yùn)算的結(jié)果通過(guò)K輸入加法器與距離運(yùn)算單元得到兩點(diǎn)歐氏距離,選擇與控制單元輸出結(jié)果進(jìn)行比較,搜索 ![]() 并累加,經(jīng)過(guò)N次處理后,得到該個(gè)體適應(yīng)度的倒數(shù),并由控制與選擇單元以中斷方式將該值返回給CPU,完成一個(gè)個(gè)體的適應(yīng)度運(yùn)算。CPU處理完這個(gè)個(gè)體的適應(yīng)度值后,再將下一個(gè)個(gè)體寫(xiě)入存儲(chǔ)單元并重復(fù)上述過(guò)程,直至求出最佳個(gè)體。
并累加,經(jīng)過(guò)N次處理后,得到該個(gè)體適應(yīng)度的倒數(shù),并由控制與選擇單元以中斷方式將該值返回給CPU,完成一個(gè)個(gè)體的適應(yīng)度運(yùn)算。CPU處理完這個(gè)個(gè)體的適應(yīng)度值后,再將下一個(gè)個(gè)體寫(xiě)入存儲(chǔ)單元并重復(fù)上述過(guò)程,直至求出最佳個(gè)體。
?
??????????????????????? 
?
??? 該適應(yīng)度運(yùn)算并行流水結(jié)構(gòu)由硬件實(shí)現(xiàn),執(zhí)行一代群體適應(yīng)度計(jì)算僅需時(shí)鐘周期數(shù)為:(F + 1)×N ×T +(2M ×T×F)=1044480≈1M,遠(yuǎn)優(yōu)于軟件實(shí)現(xiàn)。
??? 在嵌入式系統(tǒng)中實(shí)現(xiàn)遺傳算法,為降低運(yùn)算量,通常要對(duì)適應(yīng)度函數(shù)作各種簡(jiǎn)化,如穩(wěn)態(tài)方式[5],通過(guò)限制每一代發(fā)生變化的個(gè)體數(shù)量來(lái)減少運(yùn)算,但是這些改進(jìn)一定程度上限制了算法的隨機(jī)性。SoPC系統(tǒng)采用硬件資源設(shè)計(jì)的適應(yīng)度計(jì)算硬件結(jié)構(gòu)加速了適應(yīng)度運(yùn)算,克服了算法實(shí)現(xiàn)上的難點(diǎn)。
??? 遺傳聚類算法中,交叉和變異等遺傳操作主要是對(duì)存儲(chǔ)器的讀寫(xiě)與位操作,采用硬件加速效果提升不大,因此這部分功能由軟件在處理器上實(shí)現(xiàn)。總體而言,系統(tǒng)設(shè)計(jì)中,將運(yùn)算量小但步驟繁雜的部分通過(guò)軟件完成,運(yùn)算量大的部分通過(guò)硬件模塊實(shí)現(xiàn),體現(xiàn)了SoPC設(shè)計(jì)的靈活性能。
2.4 實(shí)現(xiàn)說(shuō)話人識(shí)別
??? 說(shuō)話人識(shí)別階段是針對(duì)說(shuō)話人的辯識(shí)過(guò)程,通過(guò)VQ特征提取與遺傳算法操作得到的說(shuō)話人模板的1個(gè)64容量的碼書(shū),其值表征某用戶的個(gè)人語(yǔ)音特征。識(shí)別階段,先采集一定量測(cè)試者語(yǔ)音并提取MFCC,由主CPU執(zhí)行測(cè)試者語(yǔ)音MFCC和用戶碼書(shū)的匹配操作,匹配度計(jì)算公式與適應(yīng)度計(jì)算公式相同。當(dāng)?shù)玫降钠ヅ涠却笥诮?jīng)驗(yàn)閾值,則測(cè)試者為合法用戶,小于閾值則測(cè)試者被拒絕。
3 實(shí)驗(yàn)分析與結(jié)論
??? VQ說(shuō)話人識(shí)別中,參數(shù)的選擇對(duì)系統(tǒng)性能有一定影響。主要可選參數(shù)有訓(xùn)練序列長(zhǎng)度與MFCC維數(shù);被影響的性能參數(shù)有誤識(shí)率,F(xiàn)PGA資源消耗與訓(xùn)練識(shí)別時(shí)間。
??? 實(shí)驗(yàn)測(cè)試環(huán)境為普通實(shí)驗(yàn)室,參與實(shí)驗(yàn)者共24人(男15人,女9人),測(cè)試語(yǔ)音時(shí)長(zhǎng)不低于5秒。實(shí)驗(yàn)中,隨機(jī)選不同人員語(yǔ)音生成用戶碼書(shū),然后全體人員參與測(cè)試。
??? 表1為不同參數(shù)設(shè)置下系統(tǒng)性能與資源耗用情況。根據(jù)表1可知:在相同的訓(xùn)練語(yǔ)音時(shí)長(zhǎng)(即訓(xùn)練序列幀數(shù))基礎(chǔ)上,使用MFCC+差分參數(shù)的系統(tǒng)識(shí)別率優(yōu)于單純使用MFCC,但帶來(lái)的數(shù)據(jù)處理量、存儲(chǔ)單元和邏輯單元的消耗也相應(yīng)增大;同時(shí),訓(xùn)練序列幀數(shù)對(duì)識(shí)別率的影響比提高維數(shù)更加重要。這是因?yàn)樵谟?xùn)練語(yǔ)音幀數(shù)有限的情況下,訓(xùn)練語(yǔ)音時(shí)長(zhǎng)對(duì)用戶碼書(shū)的修正效果更加明顯,使碼書(shū)更能反映用戶的語(yǔ)音特征。但是這樣也帶來(lái)大量存儲(chǔ)單元的消耗與訓(xùn)練時(shí)間的增加。
?
???????????????????????? 
??? 此外,還進(jìn)行了不同平臺(tái)上相同算法的耗時(shí)比較實(shí)驗(yàn),結(jié)果如圖4所示。圖4中DSP平臺(tái)采用C5502,PC平臺(tái)為主頻1.6GHz的AMD處理器,縱軸表示完成訓(xùn)練過(guò)程的用時(shí)。可見(jiàn),采用適應(yīng)度計(jì)算模塊的SoPC系統(tǒng)速度性能遠(yuǎn)遠(yuǎn)優(yōu)于硬處理器系統(tǒng)。
?
??????????????????????? 
參考文獻(xiàn)
[1] O′SHAUGHNESSY D.Speaker recognition.IEEE Acoustic. Speech and Signal Processing Magazine,1986,3(4):4-7.
[2] SOONG F K.Vector quantization approach to speaker?recognition.ProcICASSP85,1985:387~390.
[3] 張軍英.說(shuō)話人識(shí)別的現(xiàn)代方法與技術(shù)[M].西安:西北大學(xué)出版社,1994.
[4] 任愛(ài)峰,初秀琴,常存,等.基于FPGA的嵌入式系統(tǒng)設(shè)計(jì)[M].西安:西安電子科技大學(xué)出版社,2004.
[5] BORNHOLDT S,GRAUDENZ D.General asymmetric neural networks and structure design by genetic algorithm.Neural?Networks,1992,5(2):327-334.
?
?