
引 言
在視頻監(jiān)控、遠(yuǎn)程視頻播放等系統(tǒng)中,通常需要將視頻圖形數(shù)據(jù)通過(guò)網(wǎng)絡(luò)傳輸?shù)竭h(yuǎn)程處理機(jī)上。作為數(shù)字信號(hào)處理專用處理器,DSP雖然在視頻壓縮等方面有很大的優(yōu)勢(shì),但對(duì)諸如任務(wù)管理,網(wǎng)絡(luò)通信等功能的實(shí)現(xiàn)較困難。運(yùn)行于通用嵌入式處理器的Linux操作系統(tǒng),開(kāi)源,可以根據(jù)需要修改內(nèi)核,支持各種網(wǎng)絡(luò)協(xié)議,并且其任務(wù)調(diào)度機(jī)制性能卓越。綜合二者的優(yōu)點(diǎn),嵌入式視頻平臺(tái)可以由DSP完成圖形處理功能,并通過(guò)高速接口把視頻數(shù)據(jù)傳輸給嵌入式微處理器,然后由嵌入式Linux系統(tǒng)完成網(wǎng)絡(luò)傳輸功能。
目前DSP與微處理器之間的高速通信方式有以下幾種:共享內(nèi)存,此種技術(shù)對(duì)軟硬件的設(shè)計(jì)要求都非常高,同樣效率也最高;通用高速總線接口,如PCI、 USB等,這種類型的通信方式采用復(fù)雜的鏈路協(xié)議,軟件設(shè)計(jì)困難;專用接口,如TI公司DSP提供的HPI(Host Port Inter-face)。本文研究了TMS320E)M642的HPI接口,并提出一種在TMS320DM642和AT91RM9200間高速通信的軟硬件實(shí)現(xiàn)方案。通過(guò)HPI接口,TMS320DM642可以高速地將實(shí)時(shí)視頻數(shù)據(jù)傳輸給AT91RM9200;在AT91RM9200上,Lnux驅(qū)動(dòng)實(shí)現(xiàn)存儲(chǔ)器映射I/O和物理內(nèi)存重映射,避免了視頻數(shù)據(jù)在應(yīng)用程序與內(nèi)核之間的二次拷貝,提高了應(yīng)用程序的網(wǎng)絡(luò)發(fā)包效率。
1 HPI接口硬件設(shè)計(jì)
HPI是一種并行接口,支持32位(HPl32)和16位(HPll6)數(shù)據(jù)總線,通過(guò)HPI的數(shù)據(jù)寄存器(HPIDA、HlPIDF),ARM可以間接存取DSP的存儲(chǔ)空間。在DSP內(nèi)部,數(shù)據(jù)從存儲(chǔ)單元到HPI數(shù)據(jù)寄存器的傳輸,是由EDMA(增強(qiáng)DMA)控制器完成的。
HPI控制器的外圍引腳包括HD[0-31]、數(shù)據(jù)總線。HCNTL[O-1]是寄存器訪問(wèn)控制線,HPI控制器有4個(gè)寄存器,通過(guò)這兩根控制線,DSP 可以確定ARM要訪問(wèn)的寄存器。其中,HPIA地址寄存器,存放當(dāng)前訪問(wèn)單元的地址;HPIC為控制寄存器,實(shí)現(xiàn)各種控制命令;HPIDA自增長(zhǎng)數(shù)據(jù)寄存器,每訪問(wèn)一次該寄存器HPIA的內(nèi)容加4;HPIDF固定地址數(shù)據(jù)寄存器,與HPIDA不同之處在于,訪問(wèn)該寄存器后HPIA的內(nèi)容不變。HHWIL,高低位訪問(wèn)控制線,它只用于HPll6模式中,該控制引腳決定寄存器的高或低16位被主機(jī)訪問(wèn)。HR/nW,HPI控制器4個(gè)寄存器的讀寫(xiě)控制線。 HDSl、HDS2和HCS,其中HDSl、HDS2可連接ARM的讀、寫(xiě)控制線,HCS連接ARM的nCS7片選線,三者在DSP內(nèi)部組合形成一個(gè) HSTROBE信號(hào),當(dāng)HCS低有效并且HDSl或HDS2的讀或?qū)懙陀行В瑳Q定數(shù)據(jù)寄存器(HPIDA、HPIDF)的讀或?qū)懖僮鳌AS,地址鎖存線,當(dāng)主機(jī)的地址線與數(shù)據(jù)線復(fù)用時(shí),主機(jī)可用該控制線通知。DSP鎖存地址;其他不用該控制線情況時(shí),應(yīng)接高電平。nHRDY,DSP輸出線,表示HPI 總線是否可訪問(wèn)。nHINT,中斷輸出線,用于中斷ARM。
DSP與ARM接口電路如圖1所示。采用HPI16模式,16根數(shù)據(jù)線通過(guò)16245數(shù)據(jù)隔離器接到ARM數(shù)據(jù)總線的低16位,將HPI的片選空間置于 ARM的nCS7片選線上,HR/nW讀寫(xiě)信號(hào)經(jīng)反向器接到ARM的AB4地址線,HCNTL[O-1]與ARM的地址線AB[2-3]相連,則HPI的 4個(gè)寄存器的讀基地址為0x80000000,寫(xiě)基地址為0x80000010。在ARM端從這兩個(gè)地址開(kāi)始訪問(wèn),相應(yīng)地對(duì)HPI 4個(gè)寄存器訪問(wèn)。
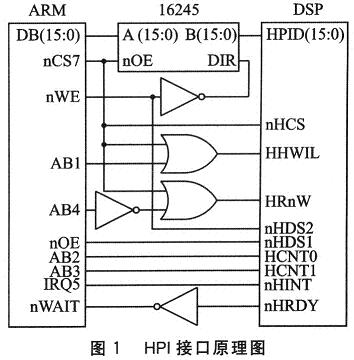
ARM通過(guò)HPI讀寫(xiě)DSP數(shù)據(jù)空間,須按以下三步順序執(zhí)行:首先,對(duì)HPIC寄存器初始化,主要針對(duì)HPI16模式最低位HWOB位設(shè)置,決定數(shù)據(jù)傳輸格式是按高半字在前(設(shè)置為0),還是低半字在前(設(shè)置為1),該位對(duì)于HPI32模式無(wú)效,可不設(shè)置;然后,對(duì)HPIA寄存器初始化,設(shè)置訪問(wèn)單元的地址;最后通過(guò)讀寫(xiě)數(shù)據(jù)寄存器(HPIDA、HPIDF)實(shí)現(xiàn)數(shù)據(jù)讀寫(xiě)操作,其中讀寫(xiě)HPIDA寄存器是完成連續(xù)地址單元讀寫(xiě)操作,讀寫(xiě)HPIDF寄存器是完成固定地址單元讀寫(xiě)操作。注意,在ARM讀寫(xiě)的過(guò)程中,如果DSP的nHRDY控制線一直為高,表示HPI數(shù)據(jù)總線未準(zhǔn)備好,ARM的讀寫(xiě)操作必須等待;當(dāng)nHRDY為低后,ARM才繼續(xù)向下執(zhí)行指令。
2 Linux驅(qū)動(dòng)設(shè)計(jì)
Linux雖然是一種整體式操作系統(tǒng),但允許在運(yùn)行時(shí)動(dòng)態(tài)加載或刪除功能模塊。這個(gè)特點(diǎn)方便了驅(qū)動(dòng)功能模塊的開(kāi)發(fā)。Linux系統(tǒng)支持兩種模塊調(diào)用方式:一種是靜態(tài)編譯,直接編譯進(jìn)內(nèi)核,在系統(tǒng)啟動(dòng)時(shí)就運(yùn)行;另外一種是動(dòng)態(tài)加載,在內(nèi)核運(yùn)行時(shí),用insmod/rmmod實(shí)現(xiàn)模塊的加載和刪除功能。在嵌入式系統(tǒng)開(kāi)發(fā)中,一般采用動(dòng)態(tài)加載方式,避免了系統(tǒng)頻繁重啟。當(dāng)最終發(fā)布產(chǎn)品時(shí),可以把模塊直接編譯進(jìn)內(nèi)核。這種處理方式比較簡(jiǎn)單,且效率高。
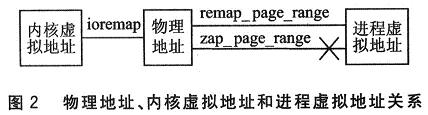
Linux系統(tǒng)中,內(nèi)存地址主要涉及以下幾個(gè)概念:物理地址、內(nèi)核虛擬地址(包括內(nèi)核邏輯地址)和進(jìn)程虛擬地址。在內(nèi)核層,當(dāng)內(nèi)核要訪問(wèn)某內(nèi)存空間時(shí),用的是內(nèi)核虛擬地址,再由MMU(存儲(chǔ)器管理單元)將內(nèi)核虛擬地址轉(zhuǎn)換為物理地址。采用虛擬內(nèi)存技術(shù),每個(gè)進(jìn)程都有互不干涉的虛擬空間。三者直接映射的關(guān)系如圖2所示,其中內(nèi)核函數(shù)zap_page_range完成去掉物理地址與進(jìn)程虛擬地址映射關(guān)系的功能。
2.1 驅(qū)動(dòng)結(jié)構(gòu)
在Linux中,設(shè)備也是作為文件來(lái)訪問(wèn)的。VFS(虛擬文件系統(tǒng))為各種不同的文件系統(tǒng)提供了統(tǒng)一的訪問(wèn)接口,通過(guò)這些接口,應(yīng)用程序可以直接使用open、read和IOctl等系統(tǒng)調(diào)用對(duì)設(shè)備進(jìn)行訪問(wèn)和控制。
本例中,把HPI作為一個(gè)外圍設(shè)備,其驅(qū)動(dòng)主要實(shí)現(xiàn)對(duì)設(shè)備的打開(kāi)、關(guān)閉、內(nèi)存映射、視頻數(shù)據(jù)緩沖區(qū)管理和物理內(nèi)存切換等功能。根據(jù)原理圖,可以確定HPI 四個(gè)寄存器對(duì)應(yīng)的物理地址,在驅(qū)動(dòng)初始化過(guò)程中,調(diào)用ioremap_uncache函數(shù)把物理地址映射為內(nèi)核虛擬地址,在驅(qū)動(dòng)層通過(guò)內(nèi)核虛擬地址訪問(wèn) HPI的4個(gè)寄存器。
存儲(chǔ)器映射I/O把HPI驅(qū)動(dòng)分配的數(shù)據(jù)空間直接映射到應(yīng)用程序的虛擬地址空間,應(yīng)用程序直接訪問(wèn)該空間,避免了用read/write系統(tǒng)調(diào)用導(dǎo)致的視頻數(shù)據(jù)二次拷貝。在內(nèi)核里,由驅(qū)動(dòng)分配一定的緩存,當(dāng)應(yīng)用程序不能及時(shí)處理DSP發(fā)送過(guò)來(lái)的視頻數(shù)據(jù),可以緩存這些數(shù)據(jù);當(dāng)應(yīng)用程序處理完一幀圖像時(shí),采用Linux的物理內(nèi)存切換技術(shù),把下一幀數(shù)據(jù)所在的物理地址重映射到應(yīng)用程序的同一虛擬地址,這樣,應(yīng)用程序不用頻繁調(diào)用mmap函數(shù)映射內(nèi)存。
2.2 存儲(chǔ)器映射I/O
一般情況下,當(dāng)應(yīng)用程序用read/write讀寫(xiě)設(shè)備數(shù)據(jù)時(shí),該設(shè)備的驅(qū)動(dòng)先將設(shè)備數(shù)據(jù)從設(shè)備上采樣到內(nèi)核緩沖區(qū),再?gòu)膬?nèi)核緩沖區(qū)拷貝到應(yīng)用程序緩沖區(qū),數(shù)據(jù)經(jīng)過(guò)了兩次拷貝。當(dāng)數(shù)據(jù)量比較小時(shí),如一些控制命令或狀態(tài)信息,對(duì)系統(tǒng)性能幾乎沒(méi)有影響。但是,如果一次傳輸?shù)臄?shù)據(jù)量比較大,比如視頻顯卡上的實(shí)時(shí)視頻圖像,兩次拷貝將大大影響系統(tǒng)的數(shù)據(jù)處理效率。這時(shí),可采用存儲(chǔ)器映射I/O技術(shù),在內(nèi)核層存儲(chǔ)器映射I/O由函數(shù) remap_page_range完成。
由remap_page_range函數(shù)的原型可以知道,該函數(shù)的意義在于通過(guò)將特定物理地址映射到進(jìn)程虛擬地址,進(jìn)程可以訪問(wèn)特定的物理地址,而這在普通情況下是不可能的。在本例中,當(dāng)進(jìn)程調(diào)用mmap函數(shù)進(jìn)行存儲(chǔ)映射時(shí),內(nèi)核會(huì)調(diào)用驅(qū)動(dòng)注冊(cè)的hpi_mmap函數(shù),傳入的參數(shù)之一包括進(jìn)程虛擬地址。在 hpi_mmap函數(shù)里,調(diào)用remap_page_range完成從緩沖區(qū)物理地址到進(jìn)程虛擬地址的映射。hpi_mmap函數(shù)實(shí)現(xiàn)如下:

mmap系統(tǒng)調(diào)用返回一個(gè)進(jìn)程虛擬地址,該地址就是vma->vm_start字段,進(jìn)程對(duì)該虛擬地址的訪問(wèn),最終變?yōu)閷?duì)物理地址CACHE_PHY的訪問(wèn)。
2.3 數(shù)據(jù)緩沖管理
緩沖管理的主要任務(wù)是,當(dāng)ARM接收到新的一幀時(shí),為其分配相應(yīng)的緩存,并將在物理地址重映射到進(jìn)程虛擬地址。當(dāng)應(yīng)用程序處理該幀時(shí),緩沖管理負(fù)責(zé)內(nèi)存區(qū)域的回收。
當(dāng)Linux內(nèi)核啟動(dòng)時(shí),可以傳人參數(shù)mem=PHY_LEN,指定存儲(chǔ)空間的大小。在本例中,內(nèi)核啟動(dòng)時(shí)為HPI驅(qū)動(dòng)預(yù)留8 MB的高端物理內(nèi)存。在本例中,借助Linux中對(duì)普通外設(shè)I/O內(nèi)存(PCI卡內(nèi)存等)管理的思想,用高度為2的樹(shù)表示一塊連續(xù)的區(qū)域。該數(shù)據(jù)結(jié)構(gòu)的優(yōu)點(diǎn)在于,資源分配簡(jiǎn)單,把離散的小內(nèi)存合并為一塊連續(xù)的大緩沖區(qū)的算法復(fù)雜度為O(1)。具體實(shí)現(xiàn)請(qǐng)參閱內(nèi)核源碼中resource結(jié)構(gòu)相關(guān)部分。

在當(dāng)前視頻處理平臺(tái)上,視頻處理、視頻傳輸、復(fù)雜任務(wù)管理等工作一般都是由一塊DSP處理器單獨(dú)完成,結(jié)合其他嵌入式微處理器協(xié)同工作的技術(shù)方案剛剛起步。經(jīng)測(cè)試,在基于本文提出的高速通信方法設(shè)計(jì)的視頻處理平臺(tái)上,TMS320DM642與AT9lRM9200間的通信速率可以達(dá)到50 Mbps,帶寬足夠用來(lái)傳輸MPEG等壓縮視頻數(shù)據(jù)。如果用HPl32模式,速度還會(huì)大幅度提高。同時(shí),因?yàn)長(zhǎng)inux系統(tǒng)的實(shí)時(shí)性不是很強(qiáng),如果采用其他實(shí)時(shí)性強(qiáng)的操作系統(tǒng),如Vxworks等,系統(tǒng)性能還會(huì)有大的提高。