
摘 要: 針對實際工作環(huán)境中數(shù)據(jù)文件格式繁多,,結(jié)構(gòu)與標準不統(tǒng)一,與既定數(shù)據(jù)庫之間互轉(zhuǎn)化難的問題,,提出了一種通用的,、新型的結(jié)構(gòu)化數(shù)據(jù)與關系數(shù)據(jù)庫互轉(zhuǎn)化的思路,并從理論和結(jié)構(gòu)上對該思路進行了構(gòu)思與設計,,形成了一套新的能夠支持多種文件格式的結(jié)構(gòu)化數(shù)據(jù)文件到指定關系數(shù)據(jù)庫的全自動互轉(zhuǎn)化軟件系統(tǒng),,并利用軟件復用等思想和技術在當前已有的可靠工程組件基礎上,以Java Web開發(fā)技術對模塊進行了初步實現(xiàn),,取得了較好的預期效果,,為今后解決類似異樣數(shù)據(jù)互轉(zhuǎn)化問題提供了思路和途徑,在工程實現(xiàn)上也具有一定參考與借鑒價值,。
關鍵詞: 結(jié)構(gòu)化數(shù)據(jù),;數(shù)據(jù)轉(zhuǎn)化;關系數(shù)據(jù)庫,;軟件設計
實際工作中記錄數(shù)據(jù)的數(shù)據(jù)格式及文件多種多樣,,這些多樣性在給用戶提供了較多的選擇自由時,也潛在的帶來了差異與統(tǒng)一的問題,。在現(xiàn)實的生活與工作中,,最典型的便是多種結(jié)構(gòu)化數(shù)據(jù)文件統(tǒng)一化的困難。
大多數(shù)與數(shù)據(jù)庫相關的數(shù)據(jù)遷移及轉(zhuǎn)化研究都關注于數(shù)據(jù)庫系統(tǒng)或信息系統(tǒng)后臺控制方面,比如參考文獻[1][2][3][4]討論的是企業(yè)數(shù)據(jù)庫后臺遷移方面的問題,;也有文獻討論了諸如XML之類更結(jié)構(gòu)化數(shù)據(jù)向數(shù)據(jù)庫轉(zhuǎn)化和遷移的問題,,比如參考文獻[5][6][7],;也有一些關注于通用或?qū)S脭?shù)據(jù)庫遷移或轉(zhuǎn)化中間件研究,,比如參考文獻[8][9][10]。但他們的目標基本都在實現(xiàn)數(shù)據(jù)庫后臺管理和減輕DBA的負擔,,而不是把目標指向一線的數(shù)據(jù)錄入業(yè)務人員,。
然而在實際工作中,一線人員面臨著很大的異種數(shù)據(jù)錄入困難問題,。由于地區(qū)差異,、個人差異、單位差異和信息化軟件更迭差異等導致本來應該是同一數(shù)據(jù)結(jié)構(gòu)和格式的數(shù)據(jù)經(jīng)過諸多差異影響后,,出現(xiàn)了統(tǒng)一難或難統(tǒng)一的問題,,給工作人員帶來了新的矛盾和工作難度。比如,,在參與某地區(qū)的審計系統(tǒng)信息化培訓時發(fā)現(xiàn),,這些數(shù)據(jù)操作員平時用的軟件可能是微軟的Excel2003、Excel2007,、Excel2010,,也可能是Access2003、Access2007,、Access2010,,也有些選擇Sqlserver系列,也有的選擇Orical系列,,甚至有些農(nóng)村,、偏遠地區(qū)和少數(shù)民族地區(qū)計算機操作能力較低的人員使用word或TXT格式的純文本文件來記錄數(shù)據(jù)。而他們處理的本是同一格式審計數(shù)據(jù),,卻出現(xiàn)了不同格式和版本的數(shù)據(jù)文件,,導致最終的匯總難度很大。
另外,,在諸如學校,、機關單位、企業(yè)或商業(yè)系統(tǒng)的網(wǎng)站或管理信息系統(tǒng)中,,也面臨類似問題,。系統(tǒng)要求用戶按照規(guī)定的格式輸入大量的業(yè)務數(shù)據(jù)。而這些數(shù)據(jù)此前可能因個人喜好問題以不同的格式和文件類型存在于用戶本地機器上,。當要輸入時,,用戶首先會期盼系統(tǒng)能夠批量處理;其次期望系統(tǒng)能夠處理的文件格式是當前的數(shù)據(jù)文件格式。這種依賴于個人需求的期望和系統(tǒng)單一或有限支持功能形成了明顯矛盾,,而矛盾的根源就是數(shù)據(jù)文件的多樣性和不統(tǒng)一,。
在百度搜索中以“數(shù)據(jù)庫數(shù)據(jù)轉(zhuǎn)換”,“數(shù)據(jù)文件轉(zhuǎn)化為數(shù)據(jù)庫”之類的關鍵字進行搜索,,可以找到數(shù)量巨大的與終端用戶數(shù)據(jù)輸入工作有關的提問,、帖子和文章,這反映了在現(xiàn)實工作中一線用戶所面臨的諸多問題,,恰如前面所分析,。
其實正是選擇的多樣性導致了記錄數(shù)據(jù)的文件類型多樣、格式不統(tǒng)一等現(xiàn)象,,進而使得許多在業(yè)務上需要綜合和匯總的數(shù)據(jù)文件因格式和文件類型差異而無法合并或難于合并的尷尬現(xiàn)象出現(xiàn),。
本文所述內(nèi)容正是為了解決這類問題而進行的一些研究和開發(fā)工作及成果。
1 問題的解決思路
解決實際工作中所產(chǎn)生的不同格式,、結(jié)構(gòu)和文件類型的統(tǒng)一化問題顯得很急迫和重要,。如何解決這個問題,大體上可分為兩類思路,。
?。?)對用戶的政策化管理方式
即利用行政文件或命令的形式,要求所有用戶采用某種統(tǒng)一格式或規(guī)范對數(shù)據(jù)進行處理與存儲,,保障數(shù)據(jù)格式和文件類型的統(tǒng)一,。
優(yōu)點:對信息系統(tǒng)的技術依賴性較低,對原系統(tǒng)或指定系統(tǒng)需要少了甚至不需要改動,,系統(tǒng)改造成本低,。
缺點:行政性過強,導致用戶需要改變或?qū)W習指定的數(shù)據(jù)文件處理技術,,有一定的行政命令執(zhí)行時間段,,同時還需要一定時間的統(tǒng)一化培訓和學習時間,從行政命令下發(fā)到系統(tǒng)可用的時間間隔較大,;行政管理成本大,、人工成本高、用戶體驗度較低,,系統(tǒng)可擴展性較弱,。
(2)對系統(tǒng)進行技術升級或改進
升級(或設計和開發(fā))可支持多種數(shù)據(jù)文件處理功能的新系統(tǒng),,使系統(tǒng)可以自動對現(xiàn)有的異種數(shù)據(jù)文件進行正確處理與存儲的能力,,從而保障數(shù)據(jù)格式和文件類型的一致性。
優(yōu)點:系統(tǒng)一旦升級或開發(fā)完成,,在不是很長的部署周期后,,系統(tǒng)即可投入使用,,部署距離實用時間較短;系統(tǒng)自動進行異種類型數(shù)據(jù)文件的統(tǒng)一化處理,,各終端用戶不需考慮學習新軟件或數(shù)據(jù)文件處理技術,,用戶體驗度較高;對行政依賴相對較小,,管理成本相對較低,;系統(tǒng)可擴展性較強。
缺點:對信息技術依賴程度相對較高,,需要投入一定的開發(fā)成本,,并組織工程技術隊伍對原有系統(tǒng)進行升級,或重新設計開發(fā)新系統(tǒng),;需要一定的開發(fā)周期。
2 軟件模塊結(jié)構(gòu)的設計
根據(jù)業(yè)務實際需求,,采取了第(2)種思路的方式,。首先查閱了與主題有關的許多文獻資料,有一些從軟件結(jié)構(gòu)上做了一些研究工作,,如參考文獻[2][8][10],,但重點不是面向用戶數(shù)據(jù)服務;也已經(jīng)有一些如參考文獻[11][12][13]用來實現(xiàn)一些指定文件向數(shù)據(jù)庫的轉(zhuǎn)化,,然而這些文獻僅僅從編程角度對問題進行了說明,,在軟件的架構(gòu)設計和軟件工程的層面上,卻鮮有較系統(tǒng)和規(guī)范的設計與實現(xiàn)見于報道,。
鑒于此,,根據(jù)數(shù)據(jù)轉(zhuǎn)化的需求,本文設計和實現(xiàn)了一種能夠自動轉(zhuǎn)化軟件的結(jié)構(gòu),。
2.1 轉(zhuǎn)化軟件模塊的總體結(jié)構(gòu)
根據(jù)實際業(yè)務需求設計出整個數(shù)據(jù)處理概念模型如圖1所示,。在該概念模型中,可以看到,,對于可支持的多種類型的數(shù)據(jù)文件,,比如Excel系列、TXT文件,、Access系列,、MySQL等類型,經(jīng)期望的“數(shù)據(jù)統(tǒng)一化綜合處理模塊”處理后,,可以轉(zhuǎn)化為某指定后臺數(shù)據(jù)庫中的標準形式,,從而達到了自動標準化與統(tǒng)一化的目地。整個模型中“數(shù)據(jù)統(tǒng)一化綜合處理模塊”是核心,,也是系統(tǒng)要解決的重點問題,,依據(jù)此要設計出期望的軟件模塊,。
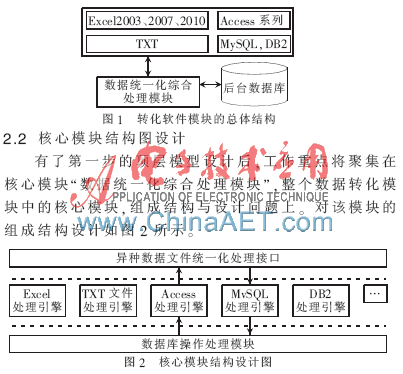
圖2所述模塊通過統(tǒng)一化處理接口接收或發(fā)送用戶數(shù)據(jù),通過圖中數(shù)據(jù)操作處理模塊與數(shù)據(jù)庫進行互操作,。比如用戶經(jīng)過web界面將數(shù)據(jù)文件提交于處理模塊,,模塊中異種數(shù)據(jù)文件統(tǒng)一化處理接口根據(jù)文件類型將文件選擇性的傳遞給對應的文件處理引擎。經(jīng)專門的引擎處理后,,形成相對統(tǒng)一化的數(shù)據(jù),,然后將這些數(shù)據(jù)再寫入到統(tǒng)一的數(shù)據(jù)庫中去,從而最終形成統(tǒng)一標準的結(jié)構(gòu)化數(shù)據(jù)信息,。
以用戶提交一個TXT文本最終系統(tǒng)轉(zhuǎn)化成MySQL數(shù)據(jù)庫數(shù)據(jù)為例,。這個過程如下:
用戶通過UI(比如web頁面形式)提交文件→“異種數(shù)據(jù)文件統(tǒng)一接口”進行預處理和選擇對應引擎→對應“引擎”進行轉(zhuǎn)化分析與處理→“數(shù)據(jù)庫操作處理模塊”實現(xiàn)與數(shù)據(jù)庫的互操作。用戶下載的過程與此相反,,不再贅述,。
3 軟件模塊的設計與實現(xiàn)
本文采用基于Java的Web系統(tǒng)開發(fā)技術,平臺采用Java2SE,、eclipse,、dreamweaver8.0作為開發(fā)平臺,以resin3.1.9為Web服務器運行平臺,,后臺數(shù)據(jù)庫采用,。因此,在模塊的實現(xiàn)中,,所要解決的就是其他類型的數(shù)據(jù)文件與MySQL數(shù)據(jù)庫的互轉(zhuǎn)化問題,。
3.1 TXT與MySQL的互轉(zhuǎn)化
利用從后臺數(shù)據(jù)庫讀取數(shù)據(jù)后,經(jīng)處理然后生成TXT文件,,再將該文件傳送到客戶端,。為了解決TXT與MySQL的相互轉(zhuǎn)化,對TXT文本的格式做了要求,,第一行表示表頭,,其他每一行代表一條記錄,每個字段使用制表符(Tab)隔開,,如圖3所示,。

這樣就可以利用Java操縱本地文件的功能,方便地根據(jù)制表符Tab和回車換行符(\r\n)來讀取TXT文件中的每一行記錄和每一個記錄字段,。再順利讀取了表頭后,,就可以形成用于執(zhí)行數(shù)據(jù)庫插入的PrepareStatement對象,然后再逐行讀入每行的各字段形成Preparestatement對象的執(zhí)行參數(shù),,然后通過exceute函數(shù)執(zhí)行,,從而實現(xiàn)寫入數(shù)據(jù)庫的目的。
從數(shù)據(jù)庫向TXT文本轉(zhuǎn)化時,,先利用JDBC從數(shù)據(jù)庫中讀出記錄,,在利用java的本地文件讀寫功能,,以格式化的形式向文件中寫入每一個記錄。以上圖所示為例,,具體寫入語句格式為:
“工號”字段值+“\t”+“姓名”字段值+“\t”+“出生日期”字段值+“\t”+“職務”字段值+“\t”+“部門”字段值+“\r\n”
對應數(shù)據(jù)視圖讀寫完畢后,,將形成一個載有所有記錄數(shù)據(jù)的TXT文檔,將此文檔再利用遠程下載方式傳送到客戶端,,從而實現(xiàn)MySQL數(shù)據(jù)庫向TXT文本的轉(zhuǎn)化功能,。
3.2 Excel 2003與MySQL的互轉(zhuǎn)化
利用類似TXT文件處理的思路,加入對Excel進行針對性操作的功能,,可以將后臺數(shù)據(jù)庫中所生成視圖中數(shù)據(jù)按照順序和結(jié)構(gòu)依次寫入到所生成Excel文件的對應單元格中,,主要以Excel2003為基礎進行試驗。為了提高開發(fā)效率和降低成本,,采取了在Jakarta的POI基礎上來進行二次開發(fā)的策略,。具體過程是在工程中引入“poi.jar”包,在此基礎上開發(fā)出讀寫Excel文件中數(shù)據(jù)的應用模塊,,并結(jié)合JDBC,,實現(xiàn)后臺數(shù)據(jù)庫與Excel文件之間的相互自動轉(zhuǎn)化技術。
整個業(yè)務處理流程如圖4所示,,其原理與3.1中TXT文檔的處理相似,除處理的文件類型不同外,,主要是流程中間引入了用于精細化操作Excel的POI模塊,。

為實現(xiàn)Aceess與MySQL的相互轉(zhuǎn)化,創(chuàng)建了一個類DB_Tran_MySQL_Access,,在該類中用Java JDBC操縱MySQL,,利用JDBC-ODBC橋操縱Access,然后根據(jù)業(yè)務需求利用Java代碼實現(xiàn)二者轉(zhuǎn)化,,部分核心代碼如下:
//連接源數(shù)據(jù)庫
Class.forName("sun.jdbc.odbc.JdbcOdbcDriver"),;
Connection connAccess=
DriverManager.getConnection(
"jdbc:odbc:target","",,""),;Statement stmt=connAccess.createStatement();ResultSet rs=stmt.executeQuery("select* from employee"),;
//連接目標數(shù)據(jù)庫
Class.forName("com.mysql.jdbc.Driver"),;
String url="jdbc:mysql://127.0.0.1:3306/test"
+"?characterSetResults=GBK",;
Connection connMySQL=
DriverManager.getConnection(
url,,"tester","pass123"),;
//執(zhí)行記錄的轉(zhuǎn)移
PreparedStatement pstmt=
connMySQL.prepareStatement(
"insert into employee(id,,name,,department,salary)
values(,?,,?,,,?,,?)"),;
while(rs.next()){//循環(huán)裝入數(shù)據(jù)
pstmt.setInt(1,rs.getInt("id")),;pstmt.setString(2,,rs.getString("name"));
pstmt.setString(3,,rs.getString("department")),;
pstmt.setDouble(4,rs.getDouble("salary")),;pstmt.executeUpdate(),;}……
上述是Aceess向MySQL轉(zhuǎn)化的主要實現(xiàn)思路和過程。其他數(shù)據(jù)庫文件與MySQL的自動互轉(zhuǎn)化實現(xiàn)與此過程基本相似,,不再贅述,。
4 系統(tǒng)的性能評估
4.1 測試用數(shù)據(jù)說明
為了檢驗系統(tǒng)對用戶的業(yè)務提升效率,將開發(fā)后的原型系統(tǒng)部署在某省的審計單位進行測試,。該單位在全省各市,、州和縣均有下屬機構(gòu)或單位,并且由于多民族和地區(qū)發(fā)展不均衡,,業(yè)務人員的信息化操作水平參差不齊,,差異較大,如文章開頭部分所述,,是比較典型的面臨數(shù)據(jù)文件多樣與不一致問題的單位,。再進行協(xié)調(diào)后,選取了其某一季度的業(yè)務數(shù)據(jù)用本文所述系統(tǒng)進行處理的效果對比,,所處理數(shù)據(jù)文件數(shù)量及類型情況如表1所示(涉及到的記錄大概30 000多條):
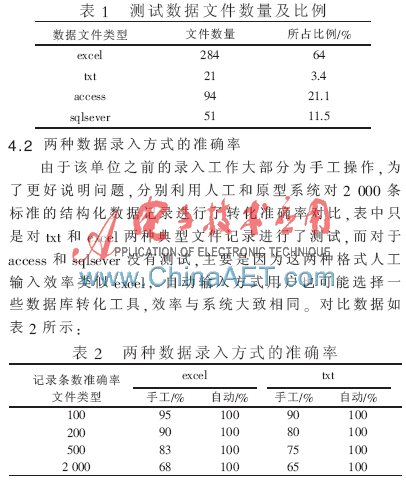
由于人工錯誤率較高,,那么在實際的使用中,可能會進行多次的檢查,,意味著需要更多的人工和時間,。
4.3 部署前后的效果對比
對所選取的數(shù)據(jù)文件利用文中所述系統(tǒng)進行了自動轉(zhuǎn)換,并與其以往的方式所消耗時間進行了對比,。為了更真實的分析本系統(tǒng)對業(yè)務的積極影響,,這里所謂處理時間不是單指計算機中的處理時間,,而是包含了整個文件準備、輸入,、處理和快速檢查等步驟,,因為這個時間是真正的業(yè)務處理過程所消耗。
所測數(shù)據(jù)文件中,,幾個類型的數(shù)據(jù)文件所消耗時間均不到一個小時,,這里為了對比方便,都視為處理時間為1個小時,。而之前該單位利用其以往的處理方式進行處理所消耗時間就相對大的多,。對其業(yè)務量和勞動時間進行了統(tǒng)計,部署前后的對比數(shù)據(jù)如表3所示:
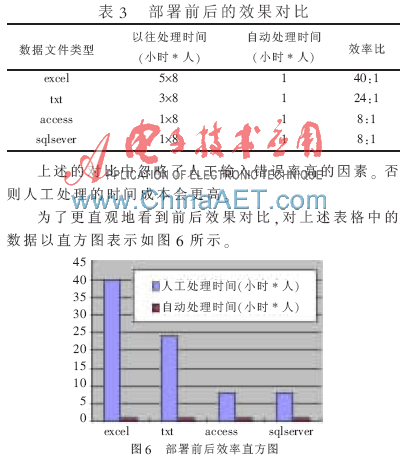
從圖可見,,所設計和實現(xiàn)的異種數(shù)據(jù)文件自動轉(zhuǎn)化系統(tǒng)確實大大提高了數(shù)據(jù)的統(tǒng)一和規(guī)范化的處理效率,,很實際的解決了用戶單位所面臨的具體業(yè)務困難,節(jié)省了業(yè)務成本,。
總體上,,本文所提出的軟件設計思路較新穎的從系統(tǒng)層面提出了一種通用異種數(shù)據(jù)轉(zhuǎn)化為統(tǒng)一數(shù)據(jù)庫數(shù)據(jù)的解決方法;并從中間件的角度構(gòu)思和設計了一個可實現(xiàn)異種數(shù)據(jù)轉(zhuǎn)化的軟件模塊的全新架構(gòu),;對系統(tǒng)進行初步工程實現(xiàn),,驗證了設計的可行性;原型系統(tǒng)表現(xiàn)出較好的自動化處理效果,,為解決用戶存在的實際困難和問題提供了一個有效途徑,。同時本文所提出的軟件思想和設計也不僅僅局限于文中所述問題,也可以對諸如Web系統(tǒng)中的不同網(wǎng)頁格式的統(tǒng)一化處理,、對于網(wǎng)絡中的不同配置文件的統(tǒng)一化處理、以及其他類似問題的處理都有很實際的參考和借鑒價值,。
當然,,由于系統(tǒng)初步實現(xiàn),還存在一些問題,,如:(1)txt文本和excel文件內(nèi)容必須是全結(jié)構(gòu)化的,,因此對文件內(nèi)容格式要求較嚴格,導致用戶對文件的操作受到一定限制,;(2)系統(tǒng)對文件內(nèi)容的格式依賴程度較高,,如果文件中不慎出現(xiàn)格式問題,將可能導致數(shù)據(jù)轉(zhuǎn)化的錯誤與失??;(3)系統(tǒng)穩(wěn)定性等方面的問題。不足之處,,將在今后的工作中繼續(xù)關注和解決,,期望能有更完善的結(jié)構(gòu)和軟件實現(xiàn),。
參考文獻
[1] 熊華平.大型異構(gòu)數(shù)據(jù)庫數(shù)據(jù)遷移系統(tǒng)的研究與應用[J].計算機應用與軟件,2012(10):178-181.
[2] 唐彬.異構(gòu)數(shù)據(jù)庫數(shù)據(jù)遷移中間件設計[D].蘭州:蘭州理工大學,,2011.
[3] 張小波.基于協(xié)同數(shù)據(jù)庫的數(shù)據(jù)遷移模型研究與實現(xiàn)[J].計算機工程與設計,,2005,26(5):1220-1222,,1301.
[4] Xiong Junjun. Key Technology Research of Migration from Informix to Oracle[J]. Computer Engineering,, 2012,7(14):52-55.
[5] 黃根平,,郭紹忠,,陳海勇,等.數(shù)據(jù)集成中XML模式和關系模式映射模型研究[J].信息工程大學學報,,2009(4):527-531.
[6] 鄭仕勇.基于XML和中間件的異構(gòu)數(shù)據(jù)庫數(shù)據(jù)遷移的研究與應用[D].桂林:桂林理工大學,,2010.
[7] Li Aimin, Tan Xianhai. Research on conversion of unstructured data to structured data based on XML technology[J]. Railway computer application,,2012(10):12-16.
[8] 劉如九.一種通用的多數(shù)據(jù)庫間數(shù)據(jù)抽取方法及應用[J].北京交通大學學報(自然科學版),,2008(4):14-18.
[9] 韋琳,袁泉,,霍劍青,,等.E-learning非結(jié)構(gòu)化數(shù)據(jù)管理系統(tǒng)的構(gòu)建與實現(xiàn)[J].中國科學技術大學學報,2010,,6(40):307-311.
[10] 徐燕.信息系統(tǒng)中的通用數(shù)據(jù)遷移工具的研究與設計[J].計算機與現(xiàn)代化,,2010(6):156-158.
[11] http://www.sj00.com/article/578/579/2006/200605238423.html[EB/OL][2006-05-23].
[12] http://www.docin.com/p-244646744.html[EB/OL][2011-08-16].
[13] http://wenda.tianya.cn/question/4d2c1166d69e0f8f[EB/OL][2009-05-10].