
文獻標(biāo)識碼: A
文章編號: 0258-7998(2013)03-0040-04
在過去數(shù)十年中,摩爾定律下的電路集成密度按照指數(shù)率增長,,目前的大型芯片已經(jīng)可以集成數(shù)十億個晶體管,。但是,靠提高芯片主頻來增加處理器能力的方法會帶來日益增長的功耗,,致使芯片無法克服散熱問題,。研究表明,內(nèi)存中數(shù)據(jù)的傳輸和ILP(指令級并行)[1]的復(fù)雜控制機制是造成芯片功耗過大的主要原因,。而大的片上存儲和輕核處理器才是克服功耗過大的有效辦法,,因此引發(fā)了新一輪的并行處理熱潮。本設(shè)計的處理器采用了特殊的指令集,,線程管理器也不同于一般的輕核機器[2],。
1 輕核陣列機
本文設(shè)計了一種新型的多線程輕核處理器,該輕核并行處理器是一個陣列機,,由多個處理單元簇(cluster)組成,,每個簇是由處理單元(PE)組成的一個二維陣列(2D Array),是一種較常見的陣列結(jié)構(gòu),。一個基本簇(base cluster)通常是16個處理單元組成的4×4陣列,,如圖1所示。其特點是:采用近鄰連接的網(wǎng)絡(luò)拓撲結(jié)構(gòu),;采用雙模式的指令集,,高效實現(xiàn)并行處理所需的線程間通信;采用專用遠程數(shù)據(jù)傳輸指令和多播方式及相應(yīng)的路由器,,滿足了輸出數(shù)據(jù)的扇出需求和遠距離線程間的數(shù)據(jù)通信,。
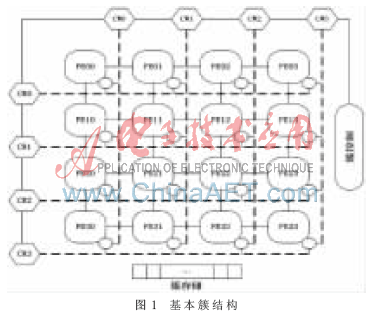
上述特點需要高性能的線程管理機制[3]來提高執(zhí)行速度和效率。使用軟件來進行線程調(diào)度無法滿足高性能并行計算的要求,因此設(shè)計了硬件的管理機制,。一個處理單元由一個ALU,、一個進程控制器(t-control)、一個路由器(RU),、4個鄰接共享存儲(MISI),、一個數(shù)據(jù)存儲(D-men)和一個指令存儲(I-men)組成,整體結(jié)構(gòu)如圖2所示,。
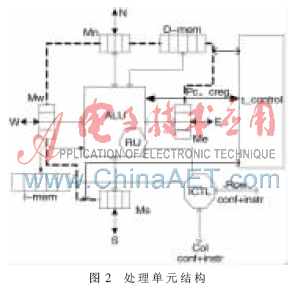
鄰居共享存儲M[S]分為4個部分:Me(東),、Mw(西)、Ms(南)和Mn(北),,每部分用于與相鄰處理器通信,。在設(shè)計中分別為寄存器R28、R29,、R30,、R31,。共享存儲器的存取采用阻塞模式(線程間同步),每個共享存儲地址都有一位數(shù)據(jù)有效位,。當(dāng)讀取數(shù)據(jù)時,,如果數(shù)據(jù)無效,則當(dāng)前線程需要等待,;如果數(shù)據(jù)有效,,則讀取數(shù)據(jù),并將其置為無效,。當(dāng)寫入數(shù)據(jù)時,,數(shù)據(jù)無效則直接寫入,數(shù)據(jù)有效則等待,。路由器RU負責(zé)將數(shù)據(jù)傳輸?shù)竭h程處理器件,,指令控制器(ICTL)模塊通過計算把指令寫入指令存儲(I-men)中,方便處理器對所需指令的讀取,。
ALU中的指令讀取單元含有一個程序計數(shù)器(PC)和一個進程地址寄存器(Creg)。每個進程都分配一塊數(shù)據(jù)存儲,,其基地址可以放在Creg中,。T_control完成進程的調(diào)度、每個進程自身的狀態(tài)跳轉(zhuǎn),、每個進程信息的存儲,,以及事件檢測(路由器遠程數(shù)據(jù)傳輸和相鄰的共享存儲器中數(shù)據(jù)的檢測)。t_control根據(jù)進程表實現(xiàn)一步到位的上下文轉(zhuǎn)換,,發(fā)送相應(yīng)的PC和Creg中的當(dāng)前數(shù)值給ALU來調(diào)度處理器處理當(dāng)前進程,。
2 進程管理的硬件設(shè)計
總體設(shè)計中采用8個進程并發(fā)執(zhí)行。進程管理器由一個控制模塊(t_manager),、一個就緒隊列模塊(ready_list),、8個進程的狀態(tài)轉(zhuǎn)換模塊(t_state)、8個進程的寄存器模塊(regfile)和一個進程信息表模塊(t_table)構(gòu)成[4],,總體設(shè)計如圖3所示,。各模塊功能如下:

(1)控制模塊(t_manager):首先創(chuàng)建進程,根據(jù)每個進程的狀態(tài)(初始態(tài),、就緒態(tài),、運行態(tài)、阻塞態(tài))創(chuàng)建就緒隊列,;完成后開始采用輪詢的方法控制每個進程的調(diào)度[5],;最后輸出ALU的控制信號。
(2)進程狀態(tài)轉(zhuǎn)換模塊(t_state):主要分為兩部分:其一是進程的自身4個狀態(tài)之間的跳轉(zhuǎn)控制部分,;其二是進程阻塞后的檢測部分,。一般是實現(xiàn)8個或者16個并發(fā)進程,,圖3所示為8個進程的設(shè)計圖,每個進程需要有自己的t_state模塊,,圖中可以看到8個進程狀態(tài)控制轉(zhuǎn)換模塊,。
(3)寄存器模塊(regfile):每個進程擁有自己獨立的32個寄存器,寄存器R0~R27每個進程自己可以讀寫,,但是鄰居處理器不可以讀寫,;寄存器R28~R31是處理器與鄰居4個處理器共享的寄存器,本設(shè)計的Me(東),、Mw(西),、Ms(南)、Mn(北)4個寄存器分別指的是R28,、R29,、R30和R31。
(4)進程的相關(guān)參數(shù)的維護表(t_table):用來記錄每個進程的當(dāng)前狀態(tài),,并且維護進程阻塞和恢復(fù)時的數(shù)據(jù),。整個控制模塊根據(jù)這個進程表中的每個進程的當(dāng)前狀態(tài)和處理器的忙閑來實現(xiàn)一步到位的上下文轉(zhuǎn)換。
2.1 進程的狀態(tài)參數(shù)表t_table設(shè)計
當(dāng)創(chuàng)建一個進程時,,就為進程建立了一個相應(yīng)的狀態(tài)參數(shù)表,,圖4所示為一個進程的狀態(tài)參數(shù)表。設(shè)計中為8個進程,,需要8組如圖所示的參數(shù)表,。狀態(tài)參數(shù)描述如下:

(1)QT:時間片,是指系統(tǒng)給每個進程所分配的執(zhí)行時間,。一旦時間片用完,,當(dāng)前進程就掛起,等待下次的調(diào)度,。
(2)PC:程序計數(shù)器,,是指進程的程序在內(nèi)存或者外存中的物理位置。進程掛起或者阻塞時,,首先存儲當(dāng)前程序執(zhí)行的PC到t_table中,,再進行其他操作;進程需要執(zhí)行時,,首先從t_table中讀取PC值,,再進行程序的讀取和其他操作。
(3)STAMP:時間戳,。每次從進程開始執(zhí)行進行計數(shù),,如果STAMP==QT,則掛起進程,;如果在STAMP,!=QT時,,進程發(fā)生阻塞,則保存當(dāng)前的STAMP,,待下次調(diào)度進程時,,從保存的STAMP值開始計數(shù)并與時間片進行比較。
(4)STATE:狀態(tài)標(biāo)志,。每個進程都有4個狀態(tài),,即:IDLE初始狀態(tài):00,READY就緒狀態(tài):01,,RUNNING初始狀態(tài):10,,WAITING阻塞狀態(tài):11。
(5)進程現(xiàn)場保護:AVAIL表示3個算子中是否有數(shù)據(jù),;MASK表示3個算子是否有用,;A0,A1,,AD表示進程阻塞時候的3個算子的地址,。
(6)ACT:表示進程是否有效。
2.2 控制模塊t_manager設(shè)計
每個進程都有自身4個狀態(tài)之間的跳轉(zhuǎn)控制,,設(shè)計中8個進程采用輪詢的調(diào)度策略來控制進程的上下文轉(zhuǎn)換,,并且產(chǎn)生與處理器之間的接口信號,狀態(tài)機如圖5所示,。
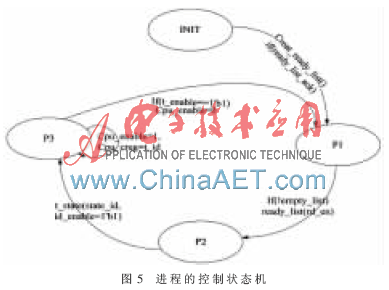
狀態(tài)跳轉(zhuǎn)解釋如下:
(1)INIT:初始狀態(tài)。首先創(chuàng)建進程和進程的就緒隊列,,就緒隊列完成后跳轉(zhuǎn)到P1狀態(tài),。
(2)P1:檢測就緒隊列的空滿。如果就緒隊列空,,則說明沒有就緒狀態(tài)的進程,,繼續(xù)等待就緒隊列的產(chǎn)生;如果不空則說明有就緒的進程,,采用輪詢的調(diào)度方法調(diào)度進程,,即從就緒隊列中讀取第一個進程號碼。
(3)P2:發(fā)送進程id號碼到進程狀態(tài)控制模塊t_state,,并且發(fā)送進程處理信號id_enable為高電平給進程狀態(tài)控制模塊t_state,,跳轉(zhuǎn)到P3狀態(tài)。
(4)P3:發(fā)送信號cpu_enable(高電平),、cpu_creg(進程id號碼),、pc(進程的程序地址)給處理器,等待處理器的處理,。一旦信號t_enbale為高電平,,表示當(dāng)前進程掛起或者執(zhí)行完成了,,則跳轉(zhuǎn)到P1狀態(tài),cpu_enable置低,。
2.3 進程狀態(tài)轉(zhuǎn)換模塊t_state設(shè)計
進程狀態(tài)轉(zhuǎn)換模塊的設(shè)計分為兩部分介紹:一是進程自身4個狀態(tài)之間的跳轉(zhuǎn)控制部分的詳細設(shè)計,;二是每個進程阻塞后的檢測部分的詳細設(shè)計。下面主要介紹單個進程的狀態(tài)控制,。
每個進程都有4個狀態(tài),,跳轉(zhuǎn)如圖6所示。各狀態(tài)說明如下:

(1)INIT:初始狀態(tài),。檢測進程的PCB表的act信息,,一旦為高(表示進程是可用的),則跳轉(zhuǎn)到下一個狀態(tài)READY,。
(2)READY:就緒狀態(tài),,表示進程已經(jīng)具備了運行條件,但是處理器不一定是空閑的,,如果不空閑,,則暫時不能使用,需等待分配處理器,。即檢測進程啟動信號id_enable,,一旦為高(表示處理器空閑,進程可以執(zhí)行),,則跳轉(zhuǎn)到RUNNING狀態(tài),。
(3)RUNNING:運行狀態(tài)。首先讀取t_table中對應(yīng)進程號的QT(時間片),、PC(進程的程序的計數(shù)器)和STAMP(時間戳),;處理器開始執(zhí)行該進程的程序后,時間戳與時間片相等了,,表示該進程的時間片結(jié)束了,,則跳轉(zhuǎn)到READY狀態(tài),并且保護現(xiàn)場,把當(dāng)前的進程號寫入就緒隊列中,,等待下次的調(diào)度,;當(dāng)處理過程中發(fā)生了阻塞,則跳轉(zhuǎn)到WAIT狀態(tài),,把當(dāng)前的PC(進程的程序的計數(shù)器),、STAMP(時間戳)、MASK(3個算子中有用的算子標(biāo)志),、AVAIL(3個算子中有數(shù)據(jù)的標(biāo)志),、A0,A1,AD(3個算子的地址)寫入t_table中,,保護現(xiàn)場,;當(dāng)進程的程序處理完時,act置低,,跳轉(zhuǎn)到INIT狀態(tài),,不再被調(diào)度。
(4)WAIT:阻塞狀態(tài),,即進程在運行過程中,,因為等待某一事件(如等待一個輸入/輸出操作完成)而暫時不能運行的狀態(tài)。這種狀態(tài)下,,發(fā)送t_enable高電平到進程控制模塊,,同時啟動監(jiān)測模塊進行所需數(shù)據(jù)的監(jiān)測,如果t_flag為高電平,,則表示監(jiān)測信號監(jiān)測到了相應(yīng)的數(shù)據(jù),,此時進程恢復(fù)READY狀態(tài),并且跳轉(zhuǎn)到READY狀態(tài),,等待下一次進程的啟動,。
3 驗證和分析
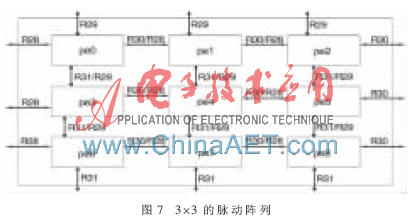
電路設(shè)計采用Verilog硬件描述語言,在Xinlinx公司的ISE環(huán)境下完成功能仿真和綜合,。在陣列機的基礎(chǔ)上,,采用指令集編寫簡單的算法完成了簡單功能測試。算法如3×3矩陣的加減法,、多個數(shù)的最大公約數(shù)與最小公倍數(shù)的求解和奇偶算法,。圖7所示是一個簡單的3×3陣列機,采用一個處理器和一個進程控制器組成一個pe,,圖中的寄存器是相鄰處理器之間的共享寄存器,。
3.1 輕核陣列機的功能測試
測試激勵為:pe0、pe1,、pe2各自包括3個進程,3個進程分別執(zhí)行不同的3×3矩陣加法,。圖7所示的pe之間的寄存器(即共享寄存器)中,,R30/R28是pe與左右鄰之間的共享寄存器,R31/R29是pe與上下鄰之間的共享寄存器,。
根據(jù)測試激勵,,pe0會發(fā)生阻塞,pe1和pe3進程都是順序執(zhí)行,。pe0的仿真結(jié)果圖如8所示,,分析如下:
(1)首先執(zhí)行0號進程。從圖中cpu_creg為000(0號進程)的信號可以看出,,當(dāng)執(zhí)行完成以后沒有發(fā)現(xiàn)阻塞,,進程0順利執(zhí)行完成,,信號t_over為高。

(2)然后根據(jù)調(diào)度算法調(diào)度1號進程(cpu_creg為001),。信號cpu_flag為標(biāo)志信號,,其為1表示寄存器R8或者R31沒有數(shù)據(jù),此時發(fā)生阻塞,,則掛起1號進程,,同時啟用監(jiān)測模塊對1號進程沒有數(shù)據(jù)的寄存器R31進行監(jiān)測。
(3)在監(jiān)測的同時根據(jù)調(diào)度算法調(diào)度2號進程(cpu_
creg為010),。若2號進程也發(fā)生了阻塞(cpu_flag為1),,則掛起2號進程,同時進行2號進程所需要的數(shù)據(jù)的監(jiān)測,;在2號進程的執(zhí)行過程中1號進程就緒,,這時2號進程一旦掛起則調(diào)度1號進程(cpu_creg為001)繼續(xù)執(zhí)行,直到1號進程執(zhí)行完成(t_over為1),;重復(fù)以上操作,,處理完所有的進程。
3.2 奇偶排序
基于奇偶原理和歸并—拆分模式[6-7],,在線性陣列上實現(xiàn)并行排序,,步驟如下:
(1)將6個數(shù)據(jù)分別存儲到6個pe的寄存器R0中。
(2)開始進行第一次偶排序,,此時pe0,、pe2、pe4分別讀取R30(CPU與右鄰的共享寄存器)的數(shù)據(jù),,而pe1,、pe3、pe5把數(shù)據(jù)從寄存器R0移到R28中,,這樣3個pe并發(fā)地執(zhí)行第一次偶排序,。
(3)開始進行第一次奇排序,此時pe1,、pe3通過R30讀取右鄰的pe2,、pe4中的數(shù)據(jù),pe2,、pe4在上次的偶排序時已經(jīng)把數(shù)據(jù)存放到自身寄存器R28中,,這樣2個pe并發(fā)地執(zhí)行第一次奇排序,pe0和pe5等待下次的偶排序,。
(4)重復(fù)步驟(2)和步驟(3),,最多執(zhí)行6/2=3次即可得到最后的結(jié)果。
多線程輕核陣列機是一個新提出的概念,目前所采用的進程管理器都是由軟件實現(xiàn),,而對于輕核陣列機中的進程調(diào)度采用軟件的方式很難實現(xiàn)高效的上下文轉(zhuǎn)換,,故本文采用硬件實現(xiàn)進程管理,對電路進行了模塊劃分和詳細設(shè)計,,最后在Xilinx的ISE環(huán)境中完成了輕核陣列機的功能仿真和綜合,。硬件設(shè)計使得進程的上下文轉(zhuǎn)換和監(jiān)測不占用處理器的處理時間,簡化了進程間的通信,,從而明顯地提高了執(zhí)行效率,。
參考文獻
[1] RAU B R,F(xiàn)ISHER J A.Instruction-level parallel processing:history,over view and perspective[J].Journal of Supercomputing,,1993,,7(1):24-31.
[2] 李濤.一種圖形處理器的輕核陣列機結(jié)構(gòu)[J].西安郵電大學(xué)學(xué)報,2012,,17(3):42-46.
[3] MAROWKA A,,GAN R.Back to thin-core massively parallel processors[J].IEEE Computer,2011,,44(12):49-54.
[4] STALLINGS W.Operating systems Internals and design principles[M].Seven Edition,,Prentice Hall,2012:158-171.
[5] Liu Chunglang,,LAYLAND J W.Scheduling algorithms for multiprogramming in a hard-real-time environment[J].Journal of the ACM,,1973,20(1):46-61.
[6] 祁金才,,張錦雄,,黃毅,等.線性陣列上的奇偶歸拆排序并行算法的MPI實現(xiàn)[J].廣西大學(xué)學(xué)報(自然科學(xué)版),,2005(S2):88-89.
[7] 官東.基于并行計算機的奇偶交換排序[J].荊門職業(yè)技術(shù)學(xué)院學(xué)報,,1999,14(6):28-29.