
當(dāng)數(shù)據(jù)在傳送中出錯(cuò),且錯(cuò)幀被漏檢時(shí),就意味著錯(cuò)誤的數(shù)據(jù)被送到應(yīng)用層,除非應(yīng)用層有額外的數(shù)據(jù)識(shí)別措施,這個(gè)數(shù)據(jù)就可能引起不可預(yù)測(cè)的結(jié)果。CAN協(xié)議聲稱有很低的錯(cuò)幀漏檢率(4.7×10-11×出錯(cuò)率)[1],有的宣傳材料在一定條件下推出要1000年才有1次漏檢,這是不正確的。錯(cuò)幀漏檢率是一個(gè)十分重要的指標(biāo),很多應(yīng)用就是看到Bosch CAN2.0規(guī)范上的說(shuō)明才選用CAN的。但是對(duì)這個(gè)指標(biāo)的來(lái)源僅有極少的公開(kāi)資料[2],以及很少的討論[3],使用戶很難對(duì)它確認(rèn)或驗(yàn)證,這給用戶帶來(lái)風(fēng)險(xiǎn)。本文采用了重構(gòu)出錯(cuò)漏檢實(shí)例的方法,導(dǎo)出了CAN的漏檢錯(cuò)幀概率下限,它比CAN聲稱的要大幾個(gè)數(shù)量級(jí)。在許多應(yīng)用中,CAN已是可靠性和價(jià)格平衡下的不二選擇,或者已被長(zhǎng)期生產(chǎn)和使用,面對(duì)這個(gè)新發(fā)現(xiàn)的問(wèn)題,在CAN本身未作改進(jìn)之前,迫切需要一種“補(bǔ)丁”來(lái)加以改善。由于篇幅有限,所以只能摘要介紹錯(cuò)幀漏檢率的推導(dǎo)過(guò)程,重點(diǎn)在提供解決方案。
1 關(guān)于CAN漏檢錯(cuò)幀概率文獻(xiàn)的討論
Bosch CAN2.0規(guī)范[1]說(shuō)它的漏檢錯(cuò)幀概率小于錯(cuò)幀率(message error rate)×4.7×10-11。它的來(lái)源見(jiàn)參考文獻(xiàn)[2],其中沒(méi)有提供產(chǎn)生漏檢的分析算法,僅提到用大量仿真得到了公式。要判斷一個(gè)幀出錯(cuò)后是否會(huì)漏檢,至少要計(jì)算2次CRC,對(duì)每一bit僅就匯編語(yǔ)言也需要幾條指令,以該文考慮的80~90 bit的幀,CRC覆蓋58~66 bit就要循環(huán)58~66次,以1989年時(shí)常用的PDP11或VAX機(jī),一條機(jī)器指令要0.1 μs左右,一幀的判斷要0.07 ms,即使不停機(jī)做一年,能作2.20×1011幀,考慮58 bit可構(gòu)成258=2.88×1017種不同的幀,再加有58×57種不同的加入2位bit錯(cuò)的位置組合,所以能作的仿真只是可能情況的微乎其微的一部分(百萬(wàn)分之一)。由于樣本太小,歸納的公式也就很難把影響因素考慮完整。
1999年Tran[3]對(duì)錯(cuò)幀漏檢率也作了研究,鑒于分析困難,他也采用計(jì)算機(jī)大量仿真的辦法,針對(duì)11位ID 、8字節(jié)數(shù)據(jù)幀,他用的是600 MB的Alpha服務(wù)器。與上述討論一樣,雖然仿真量很大,仍然是可能情況的極小部分。
CAN有關(guān)的另一個(gè)標(biāo)準(zhǔn)CANopen Draft Standard 304 (2005)給出的錯(cuò)幀漏檢率是(7.2×10-9)[4]。同樣來(lái)自CAN自動(dòng)化協(xié)會(huì)的不同數(shù)據(jù),使人無(wú)可適從。
2 新錯(cuò)幀漏檢率的導(dǎo)出
本文的研究方法是構(gòu)造出漏檢的實(shí)例,確定該種實(shí)例占可能的幀的概率,乘以與該實(shí)例相應(yīng)的出多位錯(cuò)的概率,然后求出所有可能的實(shí)例,得到CAN的錯(cuò)幀漏檢率。本文對(duì)最有可能造成漏檢的二位錯(cuò)情況進(jìn)行分析,然后擴(kuò)大為有多位錯(cuò)。數(shù)據(jù)域取8字節(jié),并假定錯(cuò)都發(fā)生在數(shù)據(jù)域內(nèi)。它并沒(méi)有將超過(guò)CRC校驗(yàn)?zāi)芰r(shí)的分散的多bit錯(cuò)漏檢率考慮進(jìn)去,所以得到的是漏檢錯(cuò)幀概率的下界。
2.1 CAN位填充中有錯(cuò)時(shí)的位序錯(cuò)開(kāi)
在有可能產(chǎn)生填充的位流中有bit錯(cuò)時(shí),就有可能造成發(fā)送方與接收方只有一方執(zhí)行填充規(guī)則,造成填充位與信息位理解的錯(cuò)亂。圖1(a)的第3位傳送中出錯(cuò),結(jié)果發(fā)送方的填充位1被接收方誤讀為數(shù)據(jù)1,整個(gè)接收數(shù)據(jù)比發(fā)送數(shù)據(jù)長(zhǎng)了1位。圖1(b)的第3位傳送中的錯(cuò)使接收方產(chǎn)生了刪除填充位的條件,因此它把發(fā)送的數(shù)據(jù)1刪去,接收數(shù)據(jù)流短了1位。

圖1 CAN的位填充規(guī)則使出錯(cuò)后接收位流變化
從位流變化可以知道,如果發(fā)生的2個(gè)bit錯(cuò)正好一次是圖1(a)的類型,一次是圖1(b)的類型,那么發(fā)送數(shù)據(jù)流和接收數(shù)據(jù)流的長(zhǎng)度將仍然相等,如果2個(gè)錯(cuò)都發(fā)生在數(shù)據(jù)域,CAN的其他檢驗(yàn)是發(fā)現(xiàn)不了它們的。
2.2 發(fā)生漏檢的條件
發(fā)送的位流與接收的位流可寫(xiě)為多項(xiàng)式形式Tx(x)和Rx(x),CRC檢驗(yàn)就是用CAN的生成多項(xiàng)式G(x)除這2個(gè)式子,得到的余數(shù)稱為CRC值,如果2個(gè)余數(shù)相同,CRC檢驗(yàn)通過(guò)。當(dāng)發(fā)生傳送錯(cuò)誤,Rx (x)= Tx(x)+U(x)×G(x)時(shí),對(duì)Tx(x)和Rx(x)求到的余數(shù)是相同的,這時(shí)就發(fā)生了錯(cuò)幀的漏檢。因此只要找到U(x),就可以構(gòu)造出漏檢的實(shí)例。
2.3 由Ec(x)尾部確定漏錯(cuò)多項(xiàng)式U(x)
為了使讀者了解推導(dǎo)過(guò)程的合理性,以下是舉例。在前面已經(jīng)發(fā)生過(guò)圖1(b)的錯(cuò)后,Tx的i位被Rx收到為第i-1位。尾部發(fā)生的錯(cuò)對(duì)應(yīng)圖1(a)的情況如圖2所示。圖中Tx的這6位構(gòu)成漏檢實(shí)例的尾部,第1位1用于隔離前面位值的影響,使后面5位0后一定產(chǎn)生填充位。由于傳送中有錯(cuò),Rx不再有連續(xù)5位0。Tx的填充位被Rx視為數(shù)據(jù)位,Rx和Tx就對(duì)齊,在此以后的傳送不再有位序錯(cuò)。由bit錯(cuò)發(fā)生位置的不同,Rx也不同,錯(cuò)誤序列Ec也不同。這個(gè)Ec也是整個(gè)錯(cuò)誤序列的尾部,用Ec,t表示。由圖2可以看到,共有5種不同的錯(cuò)誤序列尾部。顯然,將Tx中的0/1取反并不改變錯(cuò)誤序列尾部Ec,t的形式。

圖2 第2個(gè)傳送錯(cuò)造成填充位誤讀為信息位的5種漏檢錯(cuò)序列尾部形式
在已知錯(cuò)誤序列尾部形式Ec,t后便可以求出滿足它的漏錯(cuò)多項(xiàng)式尾部Ut。將各多項(xiàng)式的系數(shù)表示為:

為滿足Ec,t=G×Ut的尾部,那么系數(shù)有如下關(guān)系:
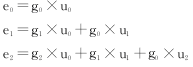
實(shí)際上將Ec,t、G均作逆序排列:
![]()
類似于求CRC值時(shí)的方法,將Ec,tR×x5除以GR就可以得到Ut的逆序系數(shù),也就得到了Ut。由CAN生成多項(xiàng)式G的系數(shù)(1100,0101,1001,1001)以及Ec,t系數(shù)便得到了滿足錯(cuò)誤序列尾部形式的漏錯(cuò)多項(xiàng)式Ut,如表1所列。

表1 錯(cuò)誤序列尾部形式和漏錯(cuò)多項(xiàng)式Ut(x)
2.4 Ut的擴(kuò)充形成Ec頭部
在Ut中增加高于x5的項(xiàng)成為U,它不會(huì)影響Ec尾部的形式,但是它會(huì)增加錯(cuò)誤序列的長(zhǎng)度。由此U生成的Ec與Tx序列也將被漏檢。Tx在數(shù)據(jù)域內(nèi)不同位置的集合就構(gòu)成了所有漏檢實(shí)例。發(fā)生第一次bit錯(cuò)后并不立即開(kāi)始TxRx位序的錯(cuò)位,要等到有填充位發(fā)生時(shí)才會(huì)有位序錯(cuò)。
2.5 構(gòu)造出錯(cuò)實(shí)例Tx
以Ut= x4+x3+1為例,對(duì)應(yīng)尾部第1位處出了傳送錯(cuò),Ut加上x(chóng)6后有U=x6+x4+x3+1,計(jì)算得Ec=U×G=(1110,1111,0101,1010,0000,01),整個(gè)錯(cuò)誤序列的長(zhǎng)度為22位。該Ec確定頭部出第1個(gè)傳送錯(cuò)的位置是6,假定為漏刪填充位錯(cuò),則在尾部應(yīng)取誤刪信息位錯(cuò)。假定在頭部出現(xiàn)的是Tx送100000,在第6位處Rx收到的是1,出了第1個(gè)bit錯(cuò),第7位Rx得到填充位1而未刪去,Tx第7位可由Ec及Rx求得為0,然后逐位反推,得到Tx發(fā)生漏檢錯(cuò)的實(shí)例,如圖3所示。

圖3 構(gòu)造的會(huì)出漏檢錯(cuò)的Tx實(shí)例
這個(gè)例子中Tx序列的長(zhǎng)度為27 bit。此種長(zhǎng)度的Tx可以有227種,每一種都可能出錯(cuò),但重構(gòu)出的這一種在特定位發(fā)生2個(gè)bit錯(cuò)時(shí)會(huì)漏檢。這個(gè)Tx在別的位置發(fā)生bit錯(cuò)時(shí),將可以檢出錯(cuò),因此它是一個(gè)可能被漏檢的可疑實(shí)例。Tx頭部共有4種可能:Tx=10000(0),10000(1),01111(1),01111(0)。(括號(hào)中的位在傳送中出了錯(cuò))。因此這幾種可疑實(shí)例占可能Tx的2-25。可疑Tx在64 bit的數(shù)據(jù)域中會(huì)有64-27+1=38種位置。對(duì)頭部Tx=100000和100001,其高4位可以與CAN的DLC重合,對(duì)Tx=011111和011110,其最高位可和DLC0重合,因此此種Tx實(shí)例在8字節(jié)數(shù)據(jù)域的幀中出現(xiàn)的可能數(shù)目是39種。于是這一種漏檢實(shí)例有概率39×2-25=1.16×10-6。當(dāng)誤碼率為0.02時(shí),64 bit內(nèi)出2個(gè)bit錯(cuò)的概率是(1-0.02)62×0.022=1.14×10-4,由這一個(gè)實(shí)例引起的CAN錯(cuò)幀漏檢率就是1.32×10-10,已經(jīng)大于Bosch的指標(biāo)。考慮U中可增加的xk中k可由6一直到43,各種xk項(xiàng)有237=1.37×1011種組合,需要對(duì)每一種U進(jìn)行計(jì)算,雖然它們的漏檢實(shí)例概率不同,其增量還是很大的。還要考慮不同Ut的貢獻(xiàn),可見(jiàn)CAN錯(cuò)幀漏檢率是非常大的。
2.6 計(jì)算結(jié)果
根據(jù)上述分析編制了在MATLAB中運(yùn)行的程序pcan.m,在MATLAB中設(shè)置format long e格式,運(yùn)行pcan(ber)即可得到不同誤碼率ber時(shí)的結(jié)果,如表2所列。
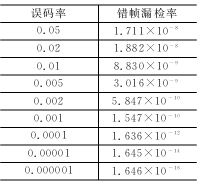
表2 典型的CAN漏檢錯(cuò)幀概率
表中ber=0.02的錯(cuò)幀漏檢率為1.882×10-8,而參考文獻(xiàn)[2]在同樣誤碼率下給出的漏檢率是:低速系統(tǒng)4.7×10-14和高速系統(tǒng)8.5×10-14。可見(jiàn)差別極大。對(duì)500 kbps的系統(tǒng),假定總線利用率為40%,幀長(zhǎng)為135 bit,那么按這個(gè)結(jié)果,CAN系統(tǒng)將在9.96小時(shí)出1個(gè)漏檢錯(cuò)幀。
3 改善錯(cuò)幀漏檢率的方法
在本文的分析中可以見(jiàn)到,由于填充位規(guī)則需要收發(fā)同步執(zhí)行,不同步時(shí)會(huì)極大干擾CRC校驗(yàn),例如CRC校驗(yàn)本來(lái)可以將所有奇數(shù)個(gè)錯(cuò)檢測(cè)出的,小于5位的多bit錯(cuò)是可以檢測(cè)出的,但只要有了成對(duì)的填充位錯(cuò)位,增加的奇數(shù)個(gè)錯(cuò)也可以是漏檢的,增加的多bit錯(cuò)也可以是漏檢的,如圖4所示。

圖4 有多位錯(cuò)的例子
漏檢錯(cuò)的根源是CAN的CRC在執(zhí)行填充位規(guī)則前生成,最根本的解決辦法是像參考文獻(xiàn)[3]指出的那樣,要把CRC校驗(yàn)放在執(zhí)行填充位規(guī)則之后。但是這樣作就會(huì)根本修改CAN協(xié)議,在已經(jīng)大量應(yīng)用的情況下如何作到的改進(jìn)前后的兼容性是個(gè)艱難的課題。作為局部的改正,參考文獻(xiàn)[3]建議加附加的檢驗(yàn)。在數(shù)據(jù)域添加一個(gè)新的不同的CRC檢驗(yàn)時(shí),根據(jù)本文的分析方法,當(dāng)誤差多項(xiàng)式Ec是這個(gè)新CRC和CAN的CRC的公倍數(shù)時(shí),仍然可以構(gòu)造出漏檢的實(shí)例,并計(jì)算出新條件下的漏檢錯(cuò)幀概率。例如采用8位的DARC8生成多項(xiàng)式x8+x5+x4+x3+1,它不含x+1因子,所以與CAN生成多項(xiàng)式的最小公倍數(shù)構(gòu)成的漏錯(cuò)多項(xiàng)式Ec將有24階,此時(shí)如2.5節(jié)所分析的那樣,總幀數(shù)將增大28倍,而漏檢幀數(shù)不變,漏檢率就減少28。但是這種方法的缺點(diǎn)是不能實(shí)現(xiàn)自動(dòng)報(bào)錯(cuò),無(wú)法使節(jié)點(diǎn)間取得數(shù)據(jù)的一致性:有局部錯(cuò)的節(jié)點(diǎn)在添加上述措施后在收完幀后才能發(fā)現(xiàn)錯(cuò),已無(wú)法要其他節(jié)點(diǎn)也丟棄該幀并要求自動(dòng)重發(fā)。
本文建議采用7b/8b的編碼辦法,犧牲一些帶寬,換取錯(cuò)幀漏檢的避免。具體做法是在8b代碼中選取不會(huì)發(fā)生填充位條件的部分,供原來(lái)7b編碼使用。
其他的編碼辦法也是可行的,類似7b/8b的還有6b/7b、5b/6b、4b/5b,它們的區(qū)別是軟件實(shí)現(xiàn)時(shí)的復(fù)雜程度以及開(kāi)銷占用數(shù)據(jù)域的多少,當(dāng)用7b/8b時(shí)CAN可以每幀送7字節(jié)數(shù)據(jù),而用4b/5b時(shí)每幀只能送6字節(jié)數(shù)據(jù)。
在附加數(shù)據(jù)域的軟件補(bǔ)丁后,若發(fā)生在ID域和CRC域的填充位規(guī)則只有單邊執(zhí)行情況時(shí),夾在它們中間的控制域就會(huì)左移或右移,幀長(zhǎng)就會(huì)變大或變小。幀長(zhǎng)的單位是1字節(jié),它會(huì)使CRC域移入EOF域,CRC最多連續(xù)5位相同,就破壞了EOF的格式,或者EOF域移入CRC域,EOF的連續(xù)8位破壞了CRC的填充格式,所以此時(shí)單邊執(zhí)行填充位規(guī)則的錯(cuò)的后果是能被發(fā)現(xiàn)的。也就是說(shuō)加軟件補(bǔ)丁后不再有錯(cuò)幀漏檢可能。
如果可疑Tx只發(fā)生在ID域,由于Tx有一個(gè)最短長(zhǎng)度,相應(yīng)于Ec,t= x3+x+1,這個(gè)長(zhǎng)度是3+15+6=24位,所以對(duì)CAN2.0B的29位ID可能會(huì)出錯(cuò),那么產(chǎn)生的后果就是接收節(jié)點(diǎn)收到的ID有錯(cuò),這是一種假冒錯(cuò)(Masquerade)。在參考文獻(xiàn)[6]中提到了CAN防止假冒錯(cuò)的方法,實(shí)際上將ID分為二部分,一部分是一個(gè)附加的CRC,只要這個(gè)CRC生成多項(xiàng)式與CAN的不同,就不會(huì)產(chǎn)生假冒ID通過(guò)接收濾的可能。
4 小結(jié)
CAN的錯(cuò)幀漏檢率對(duì)應(yīng)用的可靠性有非常大的影響,本文發(fā)現(xiàn)了可能出錯(cuò)漏檢的可疑幀重構(gòu)的方法,從而求出的錯(cuò)幀漏檢率高于Bosch提供的數(shù)據(jù)幾個(gè)數(shù)量級(jí)。對(duì)于已經(jīng)在應(yīng)用的大量可靠性要求高的系統(tǒng),迫且需要應(yīng)對(duì)的方案,2007年CAN芯片1年的出貨量為6億[7],可見(jiàn)影響之廣。本文提出了對(duì)數(shù)據(jù)添加7b/8b編碼/譯碼的中間軟件補(bǔ)丁的方法。這種方法在犧牲部分帶寬,增加一些個(gè)復(fù)雜性的付出后,根本上解決了填充規(guī)則對(duì)CRC檢驗(yàn)的干擾,使CAN的錯(cuò)幀漏檢率回到與一般通信協(xié)議中CRC檢驗(yàn)同等的水平。數(shù)據(jù)域犧牲的帶寬為8 bit,相對(duì)可能出現(xiàn)16 bit填充位而言,這算不了什么,而且減少了送達(dá)時(shí)間的抖動(dòng),可說(shuō)是有好處的。不利之處是編碼/譯碼需要的時(shí)間與空間。
這個(gè)方法也可以在將來(lái)加入到芯片中去,利用CAN的保留位,識(shí)別有無(wú)7b/8b編碼/譯碼功能,從而實(shí)現(xiàn)與原有CAN2.0的兼容。有7b/8b編碼/譯碼功能時(shí),需要的7b/8b編碼/譯碼、字長(zhǎng)圓整以及幀長(zhǎng)修正均可由硬件自動(dòng)完成。