
摘 要: 根據(jù)人類的聽覺感知機理,提出了一種改進的基于多子帶連續(xù)隱馬爾科夫模型和BP神經(jīng)網(wǎng)絡(luò)融合" title="網(wǎng)絡(luò)融合">網(wǎng)絡(luò)融合的識別算法。
關(guān)鍵詞: 語音識別" title="語音識別">語音識別? 多子帶連續(xù)隱馬爾科夫模型? BP神經(jīng)網(wǎng)絡(luò)
?
??? 連續(xù)隱馬爾可夫模型CHMM(Continuous Hidden Markov Models)是語音識別中的主要技術(shù)之一。CHMM的優(yōu)點是對動態(tài)時間序列有極強的建模能力,是一種基于時序累積概率的動態(tài)信息處理方法。在訓(xùn)練中,一個CHMM的參數(shù)由同類模式的訓(xùn)練樣本集得到,每一類模式對應(yīng)一個CHMM。CHMM的缺點是由于僅考慮了特征的類內(nèi)變化,而忽略了類間重疊性;僅用到各個模型中的累積概率最大" title="最大">最大的狀態(tài),而忽略了各個模式間的相似特征,因而影響了CHMM識別語音的性能。
??? 人工神經(jīng)網(wǎng)絡(luò)ANN(Artificial Neural Network)是基于模仿人腦神經(jīng)網(wǎng)絡(luò)結(jié)構(gòu)和功能而建立的一種信息處理系統(tǒng),具有高度的非線性處理能力,能夠進行復(fù)雜的邏輯操作和分類識別。雖然ANN有很強的分類決策能力和對不確定信息的描述能力,但它對時間序列的處理能力尚不盡人意。
??? 將CHMM的動態(tài)建模能力和ANN的模式分類能力有機地結(jié)合起來是語音識別的一個研究熱點。由于在最大似然估計中,CHMM基于嚴格的公式推導(dǎo),很難進行修改,而ANN作為估計器其性能要比傳統(tǒng)的統(tǒng)計識別系統(tǒng)" title="識別系統(tǒng)">識別系統(tǒng)強,不僅可通過訓(xùn)練用來產(chǎn)生后驗概率,而且可根據(jù)需要進行合理的改善。因此,研究人員將ANN和CHMM結(jié)合,構(gòu)成了多種性能較好的CHMM/ANN混合模型[1]。
??? 不同語音在訓(xùn)練好的各CHMM 下的概率分布有不同的規(guī)律,不同的語音不同人發(fā)音和同一人發(fā)音有一定的相似性。如選擇合適的CHMM輸出作為ANN的輸入矢量對ANN進行訓(xùn)練,利用ANN的非線性分類能力,能提高語音識別率。在大多數(shù)語音識別系統(tǒng)中,短時語音特征參數(shù)的提取是在語音的全頻帶" title="全頻帶">全頻帶進行的。然而,對人類的聽覺感知機理的研究表明,人類的聽覺解碼首先是從相互獨立的子頻帶中提取信息,然后再對不同子帶的信息進行綜合判決的。此外,對于訓(xùn)練與測試時的信道失配,由于各個信道的頻率響應(yīng)不一致,所以在不同子頻帶也表現(xiàn)出差異[2]。本文提出了一種改進的基于多帶CHMM和ANN的語音識別算法,有效地提高了識別率。
1 基于多帶CHMM和神經(jīng)網(wǎng)絡(luò)融合的語音識別
1.1 多帶識別子系統(tǒng)的理論依據(jù)
??? 由于背景噪聲和信道畸變的干擾,語音信號通常并不是純凈的,不僅記錄了語音的特征,還反映了訓(xùn)練環(huán)境的特征,并且這些特征被記錄到模型中。而在語音識別系統(tǒng)的測試中,其測試語音與訓(xùn)練環(huán)境通常是在不同環(huán)境下采集的,由此語音信息是不同的。這時模型和測試數(shù)據(jù)之間的匹配就會受到干擾,稱為失配。失配問題的解決決定了語音識別系統(tǒng)的應(yīng)用效果[3]。
??? 針對失配的問題,利用倒譜均值規(guī)整(CMN)[4]、人耳的聽覺感知機理的相對譜(RASTA)參數(shù)[5]、并行模型組合(PMC)等方法,都有一定的效果,其中CMN因原理簡單和易于實現(xiàn)而被廣泛應(yīng)用。但是,以上方法的效果都不理想。
??? 通常,語音特征參數(shù)的提取都是利用語音的全頻帶進行的。然而,如上所述,根據(jù)聽覺感知機理,子頻帶的研究和使用也有重要的意義,同時還有以下工程理由來考慮某種形式的子帶策略[6]。
??? (1)噪聲可能僅僅破壞某一部分的頻率。如果采用幾個獨立的子帶,其他未受影響的子帶就保持了純凈的音頻信號,可以做出可靠的訓(xùn)練和識別。
??? (2)某些子帶可能擁有相比其他子帶更良好的性能,比如語音信號就主要集中在低頻段。
??? (3)子帶之間相互獨立,分別進行訓(xùn)練,系統(tǒng)處理更加健壯,更加靈活。
??? (4)不同的訓(xùn)練和識別策略可以應(yīng)用于不同的子帶。
??? 此外,語音能量也是一個很重要的參數(shù),可以用來作為語音識別的一個特征[7]。因此改進的算法是將多個子帶以及全頻帶特征和幀平均能量作為ANN的輸入,利用ANN對各子帶CHMM系統(tǒng)以及幀平均能量的信息進行融合判決,以提高語音識別系統(tǒng)在信道失配和噪聲失配時的識別性能。
1.2 多帶CHMM/BP神經(jīng)網(wǎng)絡(luò)識別系統(tǒng)
??? 多帶CHMM/BP神經(jīng)網(wǎng)絡(luò)識別系統(tǒng)如圖1所示,系統(tǒng)由CHMM識別子系統(tǒng)和BP神經(jīng)網(wǎng)絡(luò)(BPNN)識別子系統(tǒng)構(gòu)成。將CHMM和BPNN結(jié)合起來,利用CHMM組成的多子帶系統(tǒng)輸出矢量在矢量空間上用BPNN進行非線性映射,并從中提取新的識別信息,再利用BP神經(jīng)網(wǎng)絡(luò)的非線性映射能力,對輸入矢量的分量加以提取,利用模式間的相關(guān)性對模式進行分類。由于利用了兩種識別模式的綜合信息和能力,多帶CHMM/BPNN識別系統(tǒng)能有效地提高系統(tǒng)對噪聲的魯棒性。
?
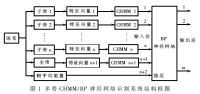
?
??? 如圖1所示,在語音頻率范圍內(nèi)劃分若干個子頻帶,在每個子頻帶內(nèi)分別提取特征參數(shù)并建立CHMM子系統(tǒng),與幀平均能量一起作為BPNN的輸入,進行融合判決。由于全頻帶能反映各種頻率信息之間的關(guān)聯(lián)性,因此圖1還有一個全頻帶的子系統(tǒng)。幀平均能量為語音數(shù)據(jù)能量的幀平均值。
2 實驗結(jié)果和分析
2.1 系統(tǒng)的訓(xùn)練過程
??? 系統(tǒng)的訓(xùn)練分為CHMM和BPNN的訓(xùn)練。語音數(shù)據(jù)采樣頻率為8kHz,提取其MFCC特征,即12階的MFCC參數(shù)和1階差分參數(shù)。在CHMM的訓(xùn)練中,每個數(shù)據(jù)逐一進行訓(xùn)練。由于3個或4個子帶的識別效果優(yōu)于其他子帶劃分方法[3]、[6],因此,系統(tǒng)分別劃分為3個和4個子帶進行實驗比較, 3個子帶劃分為100~1 100Hz、1 000~2 200Hz、2 000~4 000Hz,4個子帶劃分為100~1 000Hz、800~2 000Hz、 1 400~2 600Hz、2 000~4 000Hz。每個數(shù)據(jù)訓(xùn)練時分別產(chǎn)生不同的子帶和全帶的CHMM模型,模型之間互相獨立。即每個頻帶的數(shù)據(jù)在CHMM訓(xùn)練是由同一個頻帶的不同樣本訓(xùn)練的,當(dāng)需要學(xué)習(xí)新的樣本時,只需對相應(yīng)的CHMM模型進行修正即可,而無須改變其他的CHMM模型。
??? 而BP神經(jīng)網(wǎng)絡(luò)的訓(xùn)練采用的是多語音模式訓(xùn)練,這是由于網(wǎng)絡(luò)的引入目的是對于不同的輸入特征進行模式分類的。因為不同的模式類,其CHMM模型是不同的,但是對于BP神經(jīng)網(wǎng)絡(luò)則是公用的。這種訓(xùn)練方式保證了不同模式樣本之間的相關(guān)性和干擾性,利用模式間的這些信息對于BP網(wǎng)絡(luò)進行訓(xùn)練,可有效地增強整個系統(tǒng)的模式分類能力,提高系統(tǒng)在各種條件下的魯棒性。
多帶CHMM/BP神經(jīng)網(wǎng)絡(luò)識別系統(tǒng)的訓(xùn)練過程如下:
??? (1)運用CHMM訓(xùn)練算法建立和訓(xùn)練每個CHMM模型。在3個子帶實驗中,共4個模型,分別對應(yīng)3個子帶和1個全帶;在4個子帶實驗中,共5個模型,分別對應(yīng)4個子帶和1個全帶。
??? (2)輸入訓(xùn)練語音xi(i為語音在字庫的序號),用CHMM對語音數(shù)據(jù)進行時序處理,通過Viterbi算法得到相對應(yīng)的各CHMM模型的參數(shù)。把每個模型中的最大輸出概率的狀態(tài)序號取出來并同輸入語音的幀平均能量組成輸入矢量Vi,Vi=[qi1,qi2,…,qi,Ei],其中qi1,qi2,…,qi分別代表語音xi子帶和一個全帶的最大輸出概率的狀態(tài)序號,Ei代表語音xi的幀平均能量。
??? (3)對輸入矢量進行歸一化后作為BP神經(jīng)網(wǎng)絡(luò)的輸入矢量,輸出矢量為輸入語音數(shù)據(jù)的對應(yīng)矩陣R,R=[r1,r2,…,ri,…,r10],其中只有元素ri=1(i為語音在字庫中的序號),而其他均為0。
??? (4)運用BP神經(jīng)網(wǎng)絡(luò)的學(xué)習(xí)算法對網(wǎng)絡(luò)進行訓(xùn)練,直到BP神經(jīng)網(wǎng)絡(luò)的收斂精度達到要求為止。
2.2 系統(tǒng)的識別過程
??? 先讓待識別語音數(shù)據(jù)經(jīng)過不同的CHMM子系統(tǒng)和幀平均能量計算模塊,然后把每個CHMM模型中最大輸出概率的狀態(tài)序號取出來并同輸入語音的幀平均能量保存在輸入矢量V中,最后使用BP神經(jīng)網(wǎng)絡(luò)對輸入矢量進行非線性映射,得到識別結(jié)果。具體做法類似訓(xùn)練過程。
2.3 實驗過程
??? 以采樣頻率為8kHz,16位數(shù)據(jù),幀長32ms(對應(yīng)256點),幀移10ms(對應(yīng)86點),識別對象為漢語的十個數(shù)字(0~9),發(fā)音者共20人,每人每個詞采樣三遍,其中10個人每人抽取一組語音作為訓(xùn)練數(shù)據(jù),其余的作為識別數(shù)據(jù)。另外使用了與訓(xùn)練環(huán)境不同情況下采集的12組語音作為帶噪語音。
??? CHMM模型中的狀態(tài)數(shù)和混合度,BP神經(jīng)網(wǎng)絡(luò)的節(jié)點數(shù)對系統(tǒng)性能均有影響。通過實驗,狀態(tài)數(shù)為4和混合度為3時,對于單字識別效果很好,但提高狀態(tài)數(shù)和混合度時,不會有明顯的性能提升反而增加了運算量。而BP網(wǎng)絡(luò)的層數(shù)通常在實際運用中決定,對于本次實驗中,三層網(wǎng)絡(luò)(輸入層為5個節(jié)點,中間層為20個節(jié)點,輸出層為10個節(jié)點)可以達到很好的識別效果。
為測試CHMM/BPNN混合模型的實驗?zāi)芰Γ謩e對純凈語音和帶噪語音進行了實驗,3個子帶的實驗結(jié)果如表1所示,4個子帶的實驗結(jié)果如表2所示。本系統(tǒng)實現(xiàn)的三子帶模型和四子帶模型(CHMM/BPNN+Ei)同傳統(tǒng)的CHMM模型(CHMM)以及不加入幀平均能量Ei的CHMM/BPNN模型(CHMM/BPNN)進行了比較,得到的實驗結(jié)果如表3所示。
?

??? 從表1、表2、表3可以看出:
??? (1)4個子帶的識別效果不如3個子帶好。這是因為使用較多的子帶時,由于子帶劃分太細,每一個子帶攜帶的信息量太少,導(dǎo)致子帶的識別率下降,從而使融合的識別效果受到影響。
??? (2)語音信號的主要特征集中在低頻段,尤其是1000Hz以下,子帶1的識別率在幾個子帶中最高,子帶頻率段越高,識別能力越低,可分別從3個子帶和4個子帶的子帶1看出。
??? (3)傳統(tǒng)的CHMM模型對于非特定人、關(guān)鍵詞的純凈語音識別能力比較高,但在信噪比逐漸降低的時候,識別率明顯下降。
??? (4)CHMM/BPNN模型在純凈語音環(huán)境下,識別率不如CHMM模型,但是在噪聲背景下,其識別率由于子帶的影響也低于CHMM模型。不過實驗中也發(fā)現(xiàn),當(dāng)噪聲或者失配比較低情況下,融合模型識別率可能低于CHMM模型。
??? (5)CHMM/BPNN+Ei模型優(yōu)缺點:在純凈語音環(huán)境下識別能力低于CHMM模型,但是優(yōu)于CHMM/BPNN模型;對噪聲的適應(yīng)能力更強,在噪聲環(huán)境下,識別率高于CHMM模型和CHMM/BPNN模型。因此總的來說本文提出的系統(tǒng)的性能還是很好的。
??? (6)沒有能量時,由于子帶影響和神經(jīng)網(wǎng)絡(luò)的訓(xùn)練方式不同,會造成神經(jīng)網(wǎng)絡(luò)的識別率不如CHMM的情況。
????利用隱馬爾科夫模型優(yōu)異的動態(tài)時間序列建模能力及神經(jīng)網(wǎng)絡(luò)的模式分類能力,構(gòu)造了混合語音識別模型,同時引入了多子帶系統(tǒng),降低了系統(tǒng)的失配效應(yīng)和提高了語音識別的正確率。實驗表明,這種方法是有效的。
參考文獻
[1] ?YNOGUTI C A, MORAIS E da S. Violaro F. A comparison between HMM and hybrid ANN-HMM based?systems for continuous speech Recognition. Telecommunications Symposium,1998,(1):135-140.
[2]?BOURLARD H, DUPONT S. Subband-based speech?recognition.IEEE International Conference on Acoustics,Speech, and Signal Processing. 1997,(2):1251-1254.
[3] ?姚志強,戴蓓倩,李輝.基于多帶HMM和神經(jīng)網(wǎng)絡(luò)融合的語音識別方法的信道魯棒性.計算機工程與應(yīng)用,2004,(1):71-73.
[4]?ROSENBERG A, LEE C H, SOONG F. Cepstral channel normalization technique for HMM-based speaker?verification. Proceedings of the International Conference?on Spoken Language Processing, 1994.
[5] ?HERMANSKY H, MORGAN N. RASTA processing of?speech. IEEE Transactions on Speech and Audio Processing, 1994,2(4):578-589.
[6]?BOURLARD H, DUPONT S. A new ASR approach?based on independent processing and recombination of?partial frequency bands. Proceedings of the international?conference on Spoken Language Processing,1996,(1):
?426-429.
[7]?黃湘松,趙春暉,陳立偉.基于CDHMM/SOFMNN噪聲背景下的語音識別方法.應(yīng)用科技,2005,32(9):4-6.?