
摘 要: 通過定義本體中概念之間的語義距離來計(jì)算本體概念之間的相似度,提出一種基于該相似度的Web服務(wù)的精確匹配算法,新的算法與傳統(tǒng)的經(jīng)典匹配算法(OWL-S/UDDI算法)比較,不僅在等級(jí)上保持一致,而且使同一等級(jí)或不同等級(jí)之間的服務(wù)匹配都達(dá)到精確的程度。
關(guān)鍵詞: 語義Web服務(wù);服務(wù)匹配;語義距離;本體概念相似度
?
隨著Internet技術(shù)與Web技術(shù)的快速發(fā)展,Web服務(wù)(Web Service)應(yīng)用越來越廣。在高度動(dòng)態(tài)和依賴上下文的要求下,服務(wù)的自動(dòng)發(fā)現(xiàn)是多知識(shí)分布式環(huán)境下服務(wù)的有效集成與協(xié)作關(guān)鍵的一步。現(xiàn)有的Web服務(wù)描述文件WSDL主要描述了Web服務(wù)的調(diào)用操作方式,但缺少對Web服務(wù)功能的描述。服務(wù)注冊機(jī)制UDDI[1]通過對服務(wù)注冊信息(如服務(wù)名稱、分類、公司名稱等)進(jìn)行關(guān)鍵詞的精確匹配來發(fā)現(xiàn)服務(wù),這種語法級(jí)的服務(wù)匹配在服務(wù)的查全率和查準(zhǔn)率方面都無法達(dá)到令人滿意的效果。如何在現(xiàn)有服務(wù)描述中加入服務(wù)的功能描述,即語義信息,并通過服務(wù)語義的匹配準(zhǔn)確地查找服務(wù)成為關(guān)注的焦點(diǎn)。
在W3C組織提出語義Web服務(wù)描述語言O(shè)WL-S[2]之后,卡內(nèi)基梅隆大學(xué)的Massimo Paolucci等人提出了語義Web服務(wù)的OWL-S/UDDI匹配算法[3],該算法通過對本體中概念的包含關(guān)系的推理將Web服務(wù)匹配分為4個(gè)不同等級(jí),成為語義Web服務(wù)匹配的經(jīng)典算法,經(jīng)常被其他Web服務(wù)匹配算法引用或作為不同算法比較的基礎(chǔ)。
??? 本文針對該算法匹配不精確的問題,提出一種基于本體概念的相似度Web服務(wù)匹配方法來匹配服務(wù)的語義信息,利用本文提出的兩種語義權(quán)重分配方法和一種語義距離計(jì)算算法來計(jì)算本體概念之間的相似度。
1 Web服務(wù)匹配經(jīng)典算法
1.1 OWL-S本體及分類樹
??? 在OWL-S中,服務(wù)的功能用服務(wù)的輸入、輸出、前提和結(jié)果表示[2],服務(wù)的功能匹配表現(xiàn)為服務(wù)請求方和服務(wù)發(fā)布方的輸入、輸出、前提和結(jié)果的匹配。表示機(jī)器分類關(guān)系的本體如圖1所示。
?
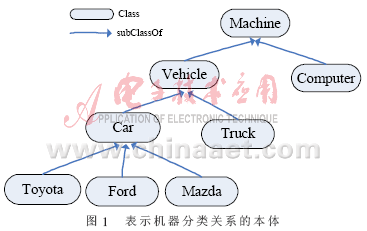
??? 在語義Web服務(wù)中,服務(wù)需求和發(fā)布雙方一般采用共同的領(lǐng)域本體準(zhǔn)確表示服務(wù)的輸入、輸出、前提和結(jié)果中的信息。通過對本體中概念關(guān)系的推理和分析,可知服務(wù)需求和發(fā)布方的匹配程度。本體中最主要的關(guān)系是概念之間的子類關(guān)系(subClassOf),也稱繼承關(guān)系[4]。由子類關(guān)系可以定義概念之間的包含關(guān)系。如果概念A(yù)是概念B的子類(subClass),概念B包含(Subsume)概念A(yù),包含關(guān)系是可傳遞的。考慮概念之間的單繼承關(guān)系,本體可以表示成1棵分類樹。
1.2 經(jīng)典匹配算法及其結(jié)果分析
??? 經(jīng)典匹配算法利用描述邏輯和本體語言O(shè)WL來實(shí)現(xiàn)對Web服務(wù)的匹配,匹配對象主要是ServiceProfile中的IOPEs參數(shù)。對兩個(gè)服務(wù)之間的匹配程度分成了Exact,Plug-In,Subsume,F(xiàn)ail 4個(gè)級(jí)別:
??? (1)Exact:當(dāng)發(fā)布服務(wù)的輸出與請求的輸出描述完全等價(jià)或當(dāng)請求服務(wù)的輸出是發(fā)布服務(wù)輸出的直接子類時(shí),稱為Exact精確匹配。
??? (2)Plug-In:當(dāng)發(fā)布服務(wù)的輸出包含請求服務(wù)的輸出時(shí),稱為Plug-In插入匹配。
??? (3)Subsume:當(dāng)請求服務(wù)的輸出包含發(fā)布服務(wù)的輸出時(shí),稱為Subsume包含匹配。
??? (4)其他情況,稱為Fail,匹配失敗。
??? 設(shè)請求服務(wù)的某個(gè)輸出為outR,發(fā)布服務(wù)的某個(gè)輸出為outA,則每一對輸出的匹配算法可描述為如下[4]:
??? Match(outR,outA)
??? { if outA=outA return Exact;
????? if outR subclassOf outA return Exact;
????? if outA subsume outR return Plug-In;
????? if outA subsume outA return Subsume;
????? else return Fail;
??? }
??? 每一對輸入匹配結(jié)果與輸出匹配結(jié)果的包含關(guān)系是相反的,即Match(outR,outA)應(yīng)用到每一對輸入的匹配為Match(inA,inR)。
??? 在匹配算法中,不存在包含關(guān)系的概念之間認(rèn)為其沒有語義聯(lián)系,返回結(jié)果為“匹配失敗(Fail)”。這一點(diǎn)符合Web服務(wù)的匹配要求。比如在圖1中如果請求服務(wù)查詢的是“Car”,而發(fā)布的服務(wù)是“Truck”,雖然2個(gè)概念都是“Vehicle”的子類,但因?yàn)榘l(fā)布的服務(wù)不能滿足請求,則認(rèn)為兩者之間是不匹配的。
??? 對于插入匹配由于發(fā)布的服務(wù)輸出包含了請求服務(wù)的輸出(或請求服務(wù)的輸入包含了發(fā)布服務(wù)的輸入),而包含匹配是請求服務(wù)的輸出包含了發(fā)布服務(wù)的輸出(或發(fā)布服務(wù)的輸入包含了請求服務(wù)的輸入),因此插入匹配的匹配程度高于包含匹配。在圖1中,如果請求查詢的服務(wù)是“Ford”汽車,發(fā)布的服務(wù)是“Vehicle”,查詢的服務(wù)通常情況下是可以滿足請求的,這時(shí)返回結(jié)果為“插入”匹配。如請求查詢?nèi)我獾摹癡ehicle”,發(fā)布“Mazda”汽車服務(wù),只有少數(shù)情況能滿足請求,這時(shí)返回結(jié)果為“包含”匹配。所以,4類匹配的匹配程度由高到低的排序是:精確匹配、插入匹配、包含匹配和不匹配。
??? 該經(jīng)典匹配算法通過對本體中類的包含關(guān)系的推理,給出服務(wù)發(fā)布方和請求方之間的匹配等級(jí),通過返回不同匹配等級(jí)的服務(wù)提高服務(wù)的查準(zhǔn)率和查全率,但它最大的缺點(diǎn)在于不能給出服務(wù)之間的精確匹配,影響了服務(wù)匹配質(zhì)量。如圖1所示,如果請求方的輸出是Ford汽車,提供方的輸出不管是Car,Vehicle還是Machine,返回結(jié)果都是插入匹配,但事實(shí)三者的匹配程度相差很大,這不利于在大量的服務(wù)中準(zhǔn)確地查找所需的服務(wù)。而概念深度對匹配精度也有一定的影響,高層不同概念之間比底層概念之間的語義差別要大,因?yàn)樵礁邔哟蔚母拍钤礁爬ǎ鋮^(qū)分度越大,越底層的概括越具體,越趨近屬于同一個(gè)分支。如“機(jī)動(dòng)車”和“非機(jī)動(dòng)車”的相似度顯然要比同屬于“機(jī)動(dòng)車”概念的“汽車”和“卡車”的語義差別要大。為了解決以上問題,本文提出一種用本體概念間相似度算法來進(jìn)行服務(wù)的精確匹配,同時(shí)提出兩種語義權(quán)重分配方法用于計(jì)算本體概念間的語義距離和相似度。新算法既保持了原算法的匹配等級(jí)的合理性,又能提供精確的匹配。
2 概念相似度算法
2.1 權(quán)重分配與語義距離計(jì)算算法
??? 目前大多數(shù)基于語義距離的相似度計(jì)算方法中,用到的語義距離都是取2個(gè)本體概念之間的最短路徑,即從概念C1到概念C2所經(jīng)過的最少邊的數(shù)目。本文將權(quán)重分配在2個(gè)概念C1和C2之間的關(guān)系上,也即本體圖中的“邊”上。權(quán)重分配原則滿足概念之間的語義距離隨著本體分類樹的深度的增加而減小。
??? 本文提出兩種權(quán)重分配方法:一種為按層等分,首先給定權(quán)重a,然后按層等分a(根節(jié)點(diǎn)為第1層),假設(shè)該本體分類樹層次數(shù)為n,則第n層節(jié)點(diǎn)所在的每條分支的權(quán)重計(jì)算公式為式(1)(因?yàn)閚層的本體分類樹,深度為n-1,關(guān)系sub(c1,c2)為繼承關(guān)系)。
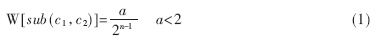
??? 另一種稱為歸一法,給定整個(gè)本體分類樹的權(quán)值為1,假如該樹根節(jié)點(diǎn)有n個(gè)分支,則每個(gè)分支總權(quán)重為1/n,如果該分支節(jié)點(diǎn)又有m個(gè)子分支,那么該分支節(jié)點(diǎn)所在分支的權(quán)重為該分支總權(quán)重的1/t(t的值在系統(tǒng)設(shè)計(jì)時(shí)指定,一般取2或3),而該分支節(jié)點(diǎn)的所有子分支的總權(quán)重為該分支節(jié)點(diǎn)所在分支權(quán)重的1/t,每條分支計(jì)算公式如式(2)所示(關(guān)系sub(c1,c2)為繼承關(guān)系):

??? 例如,對于圖1根據(jù)本文提出的權(quán)重分配方法按式(1)有:W[sub(Machine,Computer)]=a/2=0.5a;W[sub(Vehicle,Truck)]=a/4=0.25a;W[sub(Machine,Toyota)]=0.125a。
??? 對于圖1根據(jù)本文提出的權(quán)重分配方法按式(2)有(t=2):W[sub(Machine,Computer)]=1/2=0.5;W[sub(Machine,Vehicle)]=1/4=0.25;W[sub(Car,Toyota)]=1/48。
??? 定義1:定義概念c1和c2之間的語義距離為distance(c1,c2)。
??? 定義2:定義概念節(jié)點(diǎn)c1和c2之間的路徑長度為Lengthc1,c2)。
??? 定義3:定義概念節(jié)點(diǎn)c1和c2之間的語義距離為負(fù)值,即distance(c1,c2)。<0。
??? 對于表示本體的分類樹,可以用2個(gè)不同概念節(jié)點(diǎn)之間的距離來衡量概念之間的相似度。為了滿足服務(wù)匹配的要求與計(jì)算方便,在計(jì)算任意兩點(diǎn)之間的語義距離時(shí)選取公式(1)來計(jì)算(a=1),可以通過如下算法得到:
??? (1)查看c1和c2是否是同一個(gè)概念。
??? 如果是,則distance(c1,c2)=0;如果否,轉(zhuǎn)入(2)。
??? (2)查看c1和c2之間是否存在直接繼承關(guān)系。
??? 如果是,則distance(c1,c2)=W[sub(c1,c2)]×1,而distance(c2,c1)=-[W[sub(c1,c2)]×1];如果否,轉(zhuǎn)入(3)。
??? (3)查看c1和c2之間是否存在間接的繼承關(guān)系。
??? 如果是,則distance(c1,c2)=Length(c1,c2)×∑[W[sub(c1,c2)],其中∑[W[sub(c1,c2)]為該路徑上的權(quán)重之和;distance(c2,c1)=-Length(c1,c2)×∑[W[sub(c1,c2)],如果否,轉(zhuǎn)入(4)。
??? (4)c1和c2之間無繼承關(guān)系,語義距離distance(c1,c2)=∞。
??? 根據(jù)以上算法對于圖1,Machine與Machine滿足算法的第1種情況,所以distance(Machine,Machine)=0,Truck到Vehicle滿足算法的第2種情況,所以distance(Vehicle,Truck)=0.125,Machine到Car滿足算法的第3種情況,此時(shí)語義距離為負(fù)數(shù),所以distance(Machine,Car)=-0.75,Computer到Truck滿足算法的第4種情況,所以distance(Computer,Truck)=∞;
2.2 相似度計(jì)算
??? 得到2個(gè)概念c1和c2之間的語義距離distance(c1,c2)之后,需要構(gòu)造合理的相似度函數(shù),將語義距離轉(zhuǎn)化成相似度。相似度函數(shù)需要滿足以下幾個(gè)主要特性[5]:
??? (1)當(dāng)語義距離為0時(shí),相似度為l。即當(dāng)2個(gè)概念相同時(shí),相似度為1。
??? (2)此函數(shù)隨語義距離的增加而減小。即語義距離大的概念間的相似度小于語義距離小的概念間的相似度。
??? (3)函數(shù)的輸出必須保證在[0,1]區(qū)間內(nèi)。?
??? 根據(jù)以上3個(gè)特性,得到2個(gè)概念c1、c2之間的相似度函數(shù)SimF(c1,c2)定義如下:
??? 
??? 通過以上定義,分類樹中2個(gè)概念的匹配程度就是[0,1]中的1個(gè)具體實(shí)數(shù),數(shù)值越大,節(jié)點(diǎn)之間的距離越短,節(jié)點(diǎn)所對應(yīng)的概念的相似度越高。按以上定義,傳統(tǒng)算法中的“精確匹配”的相似度為1,“匹配失敗”的相似度為0,“插入匹配”的相似度為1個(gè)(0.5,1)的實(shí)數(shù),“包含匹配”的相似度為1個(gè)(0,0.5)之間的實(shí)數(shù)。
??? α,β分別為影響因子,α,β的取值決定了語義距離影響相似度取值的大小,α,β的取值越大,同樣距離下得出的相似度就越小。直觀看來,合理的α,β取值需要保證在語義距離為l時(shí)(即非常相近的2個(gè)概念如具有父子關(guān)系的概念),相似度在0.5以上。根據(jù)上面提出的計(jì)算相似度算法公式(3)(α=0.9,β=0.8)得到圖1中個(gè)本體概念之間的相似度,如表1所示。

??? 通過上表分析可以看出,根據(jù)本文提出的算法,既提高了服務(wù)的匹配精度,還保持了傳統(tǒng)算法的匹配等級(jí)的合理性。例如,如果按照經(jīng)典的匹配算法,如果請求服務(wù)的輸出為Mazda,則服務(wù)輸出為Machine,Vehicle和Car的服務(wù)都能滿足要求(相似度都≥0.5),而利用本文提出的算法(相似度≥0.5),則只有輸出為Mazda的服務(wù)滿足要求。如果發(fā)布的服務(wù)與請求的服務(wù)中有多個(gè)輸入?yún)?shù)和輸出參數(shù),則可以取匹配度最高的參數(shù)來匹配某一個(gè)請求的輸入或輸出,最終的匹配結(jié)果可以是請求服務(wù)所有輸入輸出參數(shù)的加權(quán)平均值。
3 實(shí)驗(yàn)結(jié)果與分析
??? 在服務(wù)匹配中,通常用查準(zhǔn)率和查全率來衡量一個(gè)Web服務(wù)匹配算法的好壞。查準(zhǔn)率是指查詢返回符合查詢條件的Web服務(wù)數(shù)量與查詢返回Web服務(wù)總數(shù)量的比率;查全率是指查詢返回符合查詢條件的Web服務(wù)與測試樣本集中符合查詢條件的Web服務(wù)的比率。查準(zhǔn)率和查全率越高,服務(wù)匹配算法越好。為了驗(yàn)證本文匹配算法的有效性,開發(fā)了1個(gè)原型系統(tǒng)WSMS(Web服務(wù)匹配系統(tǒng),本文精確匹配算法實(shí)現(xiàn)),參考OWLS-TC V2服務(wù)測試數(shù)據(jù)集[6],制定了測試數(shù)據(jù)集WSMS-TC(該測試集來自3個(gè)知識(shí)領(lǐng)域,每個(gè)領(lǐng)域抽取50個(gè)服務(wù)描述,共150個(gè)),對WSMS和經(jīng)典的OWL-S/UDDI匹配算法進(jìn)行了仿真性能測試,對于要求返回精確度為0.2以上或0.4以上的服務(wù),OWL-S/U DDI匹配取包含匹配的結(jié)果;對于要求返回精確度為0.5以上、0.6以上或0.8以上的服務(wù),OWL-S/UDDI匹配取插入匹配的結(jié)果,統(tǒng)計(jì)結(jié)果如表2所示(圖中用OUDDIS代替OWL-S/UDDI算法實(shí)現(xiàn)的系統(tǒng))。

??? 分析可知,試驗(yàn)結(jié)果得出本文提出的相似度匹配算法的平均查準(zhǔn)率和平均查全率比OWL-S/UDDI算法的平均查準(zhǔn)率和查全率高得多,在相似度等于等級(jí)的劃分界線時(shí),如0.5,1時(shí),兩者的匹配程度是接近的。
??? 本文提出了一種基于本體概念相似度的Web服務(wù)匹配方法,該方法能精確匹配用本體概念描述服務(wù)請求方和發(fā)布方的功能,且匹配結(jié)果與OWL-S/UDDI匹配的等級(jí)保持一致。實(shí)驗(yàn)結(jié)果證明,該算法比經(jīng)典的OWL-S/UDDI匹配算法具有更高的查準(zhǔn)率與查全率。
參考文獻(xiàn)
[1] Web service description language[EB/OL], 2007, 6. http://www.w3.org/TR/2007/REC-wsdl20-20070626.
[2] Universal description, discovery and integration(UDDI)[EB/IL],2007,5. http://www.uddi.org/specification.html.
[3] The OWL services conlition. OWL-S: semantic markup for Web service[EB/OL],2004,05. http://www.w3.org/Submission/OWL-S/.
[4] PAOLUCCI M, KAWAMURA T, PAYNE T R,et al. Semantic mathcing of Web services capabilities[C]//Proceedings of the 1st International Semantic Web Service. Las Veges, Nevada, USA: [s.n],2003.
[5] 張釙.基于語義的網(wǎng)絡(luò)服務(wù)匹配機(jī)制的研究與實(shí)現(xiàn)[D].北京:清華大學(xué),2005.
[6] WL-S[EB/OL], 2007, 12.http://projecs.semwebcentral.org/fra/download.php/255/owls-tc2.zip.