
摘 要: 對Web文檔進行分類可以較好地解決網(wǎng)上信息雜亂的現(xiàn)象,介紹了Web文檔分類的相關(guān)知識以及關(guān)鍵技術(shù),并對目前的分類方法進行了總結(jié),對Web文檔分類中關(guān)聯(lián)規(guī)則挖掘研究現(xiàn)狀和主要技術(shù)進行了論述,指出了負關(guān)聯(lián)規(guī)則在Web文檔分類中的發(fā)展趨勢。
??? 關(guān)鍵詞: 數(shù)據(jù)挖掘;Web文檔分類技術(shù);負關(guān)聯(lián)規(guī)則
?
隨著科學(xué)技術(shù)的發(fā)展,Internet正在以令人難以置信的速度迅速發(fā)展,使得萬維網(wǎng)成為一個擁有大量資源的數(shù)據(jù)庫。這個蘊含著豐富資源的信息空間為數(shù)據(jù)挖掘研究提出了新的挑戰(zhàn),存放的這些信息絕大多數(shù)都是以文本的形式存在的,如何在浩瀚的文本信息中挖掘到潛在的知識是一個有待解決的問題。為了幫助人們有效地組織和管理海量的Web信息,Web文檔分類技術(shù)應(yīng)運而生。
1 Web文檔分類的概念及分類方法
1.1 Web文檔分類的概念
??? Web挖掘[1]是指從大量Web文檔的集合C中發(fā)現(xiàn)隱含的模式P。如果將C看作輸入,將P看作輸出,那么Web挖掘的過程就是從輸入到輸出的一個映射ζ:C→P。一般地,Web挖掘可以簡單的分為三類[2]:Web內(nèi)容挖掘(Web content mining),Web結(jié)構(gòu)挖掘(Web structure mining)和Web使用記錄的挖掘(Web usage mining)。
??? 文檔分類是Web內(nèi)容挖掘中一項非常重要的任務(wù),它是根據(jù)頁面的不同特征,將其劃分為事先建立起來的不同類,屬于有指導(dǎo)的機器學(xué)習(xí)問題。其目的是讓機器學(xué)會一個分類函數(shù)或分類模型,該模型能把Web文本映射到已存在的多個類別中的某一類,使檢索或查詢的速度更快,準(zhǔn)確率更高。這樣,用戶在瀏覽Web文檔時,就不會因為縱橫交錯的超級鏈接而“迷路”。
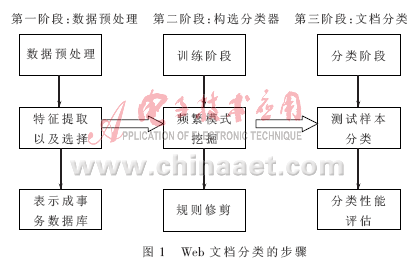
??? Web文本分類是一個典型的有教師的機器學(xué)習(xí)問題,一般的可分為數(shù)據(jù)預(yù)處理、構(gòu)選分類器和文檔分類3個階段。數(shù)據(jù)挖掘主要是針對結(jié)構(gòu)數(shù)據(jù)庫,如數(shù)據(jù)倉庫中的數(shù)據(jù),然而,在網(wǎng)絡(luò)中大部分的信息是存儲在文本數(shù)據(jù)庫當(dāng)中,即所謂的半結(jié)構(gòu)化數(shù)據(jù)(semi-structure data),它既不是完全無結(jié)構(gòu)的,也不是完全結(jié)構(gòu)的,因此需要對文本進行預(yù)處理,抽取代表其特征的元數(shù)據(jù),這些特征可以用結(jié)構(gòu)化的形式保存。
??? 訓(xùn)練算法的工作是對訓(xùn)練文檔集合中每篇文本對應(yīng)的詞表進行統(tǒng)計,計算出類別向量矩陣,同時進行歸一化,最后保存訓(xùn)練得到的向量表,即得到了分類知識庫。分類算法(也可稱為識別算法)則依據(jù)訓(xùn)練得到的分類知識庫,并用一定的算法對待分類文本進行分類。Web文檔分類的步驟如圖1所示。
?
1.2 Web文檔分類方法
目前關(guān)于Web文檔分類的研究已經(jīng)取得了很大的進展,并提出了一系列的分類法。常見的文檔分類方法可以分為三類[3]:一類是基于TFIDF方法,包括TFIDF算法、K近鄰算法等;另一類則是基于統(tǒng)計學(xué)分類方法,如貝葉斯算法、最大熵算法等;第三類是基于知識學(xué)習(xí)的方法,如決策樹(Decision Tree)C4.5等算法。
近年來,Web文檔分類已成為眾多領(lǐng)域研究者的熱門研究課題,研究者們從不同的角度把越來越多的知識引入該領(lǐng)域。
向量空間模型VSM(Vector Space Model)將所有文本都表示成具有某種相同結(jié)構(gòu)的數(shù)據(jù),它是Salton等人于上世紀(jì)60年代末首先提出的,最早應(yīng)用于信息檢索領(lǐng)域。而Joachims最早將SVM方法用于文本分類[4]。饒文碧等人[5]提出了一種擴展的基于VSM的Web文本分類,在傳統(tǒng)的訓(xùn)練和分類算法的基礎(chǔ)上,加入了一個反饋判定的算法,這種方式更加貼近真正意義上的機器學(xué)習(xí),使得該算法具有一定程度上的認知自主性和不斷學(xué)習(xí)的能力。由于Web文檔往往具有不確定的特征,使得利用模糊集合理論對信息檢索過程的不確定性建立模型成為可能,雷景生在參考文獻[6]中提出了一種基于模糊相關(guān)技術(shù)的Web文檔分類方法。張志強、鄭家恒提出基于加權(quán)類軸的方法[7],利用了Web文本的標(biāo)記信息在文檔中的重要程度不同,使用了Web標(biāo)記的三級加權(quán)處理,使向量的維數(shù)有所下降。胡和平、易高翔提出了基于容錯粗糙集的方法[8],利用容錯關(guān)系來表示文檔,利用特征詞協(xié)同出現(xiàn)的價值,豐富特征詞對Web文檔的描述。
2 關(guān)聯(lián)規(guī)則在Web文檔分類中的研究
2.1 文本預(yù)處理
由于Web上的內(nèi)容大都是半結(jié)構(gòu)化的,通常要進行結(jié)構(gòu)化的表示。表示方法為:一篇文檔有類標(biāo)簽C,詞條為T(T={t1,t2,…,tm}),用事務(wù)D={C,t1,t2,…,tm}來表示該文檔模型,則Web文檔集可表示成事務(wù)集,其項集由文檔詞條和文檔所屬類別組成。
在數(shù)據(jù)清理階段,采用移除停用詞和計算TF/IDF的方式對文本文檔進行清理。需要移除對構(gòu)造關(guān)聯(lián)分類器價值不大的詞條,形成清潔文檔,包括一些副詞、連詞、某些代詞等對分類意義不大的詞。其中TF/IDF的公式如下:
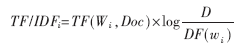
其中,TF(Wi,Doc)指單字Wi在文檔Doc中出現(xiàn)頻度,D為文檔總數(shù),DF(Wi)為單字Wi在其中出現(xiàn)至少一次的文檔數(shù)目。
2.2 關(guān)聯(lián)規(guī)則的產(chǎn)生
經(jīng)過文本預(yù)處理后,就要尋找頻繁項集,借鑒了傳統(tǒng)的Apriori算法,找到了一種很適合處理文本文檔事務(wù)集的方法:對每個候選項集定義一個tidlist的結(jié)構(gòu),項集Ii的tidlist由包含事務(wù)的tid組成。1-itemset通過搜索文檔事務(wù)集D得到,候選k項集的tidlist可由該候選k項集的那2個(k-1)項集的tidlist求交集產(chǎn)生。
在文檔分類中產(chǎn)生的關(guān)聯(lián)規(guī)則數(shù)量可能是巨大的,為了減少噪音信息和分類時間,所以要對文本關(guān)聯(lián)規(guī)則進行剪枝,馬光志等人定義了正負相關(guān)的定義:
定義 規(guī)則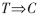 (T為詞條項集,C為類標(biāo)簽)的作用度(lift)定義為可信度對期望可信度的比值,即I(
(T為詞條項集,C為類標(biāo)簽)的作用度(lift)定義為可信度對期望可信度的比值,即I( )=P(C|T)/P(C)。如果,I(
)=P(C|T)/P(C)。如果,I( )的值大于1,則說T和C正相關(guān),表明每一個的出現(xiàn)都蘊涵另一個的出現(xiàn);如果結(jié)果值等于1,則它們相互獨立,無相關(guān)性;如果小于1,表明它們負相關(guān)。
)的值大于1,則說T和C正相關(guān),表明每一個的出現(xiàn)都蘊涵另一個的出現(xiàn);如果結(jié)果值等于1,則它們相互獨立,無相關(guān)性;如果小于1,表明它們負相關(guān)。
所以在剪枝的時候就根據(jù)定義選擇正相關(guān)的規(guī)則,去掉獨立和負相關(guān)的規(guī)則。然后剔除那些特殊并且置信度較低的規(guī)則,最后應(yīng)用數(shù)據(jù)庫候選覆蓋來選取最顯著規(guī)則子集。
2.3 利用文本關(guān)聯(lián)規(guī)則進行文本分類
??? 常見的方法是將新文檔分配到與之規(guī)則匹配最多的類或是分配給與第一個規(guī)則匹配的類別。參考文獻[9]提出了一種折中方法,綜合考慮匹配規(guī)則數(shù)和置信度的影響。將規(guī)則表按類標(biāo)簽分組,設(shè)定一個置信度閾值,將低于該閾值的匹配規(guī)則從分組中剔除,接著將分組按置信度的和排序。
在進行類識別時,遵循以下兩條規(guī)則:(1)優(yōu)先選擇置信度和最大分組的標(biāo)簽作為該文檔的類標(biāo)簽;(2)在置信度和相等的情況下,選擇匹配規(guī)則最多組的標(biāo)簽作為該文檔的類標(biāo)簽。
3 負關(guān)聯(lián)規(guī)則的研究現(xiàn)狀及主要技術(shù)
關(guān)聯(lián)規(guī)則挖掘是數(shù)據(jù)挖掘研究的一個重要的、高度活躍的領(lǐng)域。傳統(tǒng)的關(guān)聯(lián)規(guī)則AR(association rule)是 的形式,用于挖掘顧客事務(wù)數(shù)據(jù)庫中項集間的關(guān)聯(lián)關(guān)系,最初由R.Agrawal等人于1993年首先在參考文獻[11]中提出,以后諸多研究人員對此進行了大量研究,其工作主要是對原有的算法進行改進,以提高算法挖掘規(guī)則的效率。關(guān)聯(lián)規(guī)則挖掘?qū)嵸|(zhì)上就是在滿足用戶給定的最小支持度的頻繁項集中,找出所有滿足最小置信度的關(guān)聯(lián)規(guī)則,具體分為兩步:(1)找出所有的頻繁項集;(2)用頻繁項集產(chǎn)生關(guān)聯(lián)規(guī)則。
的形式,用于挖掘顧客事務(wù)數(shù)據(jù)庫中項集間的關(guān)聯(lián)關(guān)系,最初由R.Agrawal等人于1993年首先在參考文獻[11]中提出,以后諸多研究人員對此進行了大量研究,其工作主要是對原有的算法進行改進,以提高算法挖掘規(guī)則的效率。關(guān)聯(lián)規(guī)則挖掘?qū)嵸|(zhì)上就是在滿足用戶給定的最小支持度的頻繁項集中,找出所有滿足最小置信度的關(guān)聯(lián)規(guī)則,具體分為兩步:(1)找出所有的頻繁項集;(2)用頻繁項集產(chǎn)生關(guān)聯(lián)規(guī)則。
Zhu等人在參考文獻[14]中提出了一種快速有效的基于FP-tree的負關(guān)聯(lián)規(guī)則挖掘算法MNARA,該算法不但可以發(fā)現(xiàn)所有的負關(guān)聯(lián)規(guī)則,而且由于整個過程只需掃描事務(wù)數(shù)據(jù)庫兩次,算法是有效和可行的。
? Dong等人提出了一種PNARC模型[15],利用了支持度-置信度框架,采用相關(guān)性檢驗方法,不僅能夠同時挖掘出頻繁項集中的正、負關(guān)聯(lián)規(guī)則,而且能夠檢測并刪除相互矛盾的規(guī)則;隨后又給出一種基于多置信度和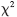 檢驗的挖掘正負關(guān)聯(lián)規(guī)則的方法,并且提出了一種PNARMC算法[16],該算法不僅能夠正確地產(chǎn)生正負關(guān)聯(lián)規(guī)則,而且能靈活地控制關(guān)聯(lián)規(guī)則的數(shù)量。在PNARC模型中給出了正、負關(guān)聯(lián)規(guī)則的定義。
檢驗的挖掘正負關(guān)聯(lián)規(guī)則的方法,并且提出了一種PNARMC算法[16],該算法不僅能夠正確地產(chǎn)生正負關(guān)聯(lián)規(guī)則,而且能靈活地控制關(guān)聯(lián)規(guī)則的數(shù)量。在PNARC模型中給出了正、負關(guān)聯(lián)規(guī)則的定義。
4 負關(guān)聯(lián)在Web文檔分類中的發(fā)展趨勢
負關(guān)聯(lián)規(guī)則的研究為傳統(tǒng)關(guān)聯(lián)規(guī)則開辟了一個嶄新的領(lǐng)域。研究表明,負關(guān)聯(lián)規(guī)則同樣起著非常重要的作用,一方面可以進一步完善項集間的關(guān)聯(lián)規(guī)則分析,另一方面可以為決策支持提供更多有用的信息。
在進行Web文檔分類的時候,文檔集產(chǎn)生的關(guān)聯(lián)規(guī)則數(shù)往往是巨大的,所以就需要進行剪枝處理,目前在剪枝的時候直接把負相關(guān)的規(guī)則剪掉,但是在負相關(guān)中也包含著有用的信息,所以本文提出了基于負關(guān)聯(lián)規(guī)則的Web文檔分類技術(shù)。
基于負關(guān)聯(lián)規(guī)則的Web文檔分類策略,是在基于關(guān)聯(lián)規(guī)則分類的基礎(chǔ)上,為了更有效地體現(xiàn)現(xiàn)實事件直接的關(guān)聯(lián)而采取的分類策略,這種分類方法和正關(guān)聯(lián)規(guī)則分類相結(jié)合能夠更加有效和準(zhǔn)確地進行分類,可以更加全面地分析各種因素之間隱藏的內(nèi)在聯(lián)系。運用負關(guān)聯(lián)的研究方法來完善文檔集產(chǎn)生關(guān)聯(lián)規(guī)則的正確度,從而提高Web文檔分類的精確度。
現(xiàn)有的WEB文檔的分類方法中,基于負關(guān)聯(lián)的Web文檔分類研究的比較少,在以后的研究中應(yīng)該結(jié)合負關(guān)聯(lián)規(guī)則將支持度和置信度結(jié)合起來考慮,這將是一個新的研究趨勢。
參考文獻
[1] QUEK C Y. Classification of World Wide Web documents Senior Honors dissertation. School of Computer Science Camegie Mellon University, 1997.
[2] MADRIA S K. Research Issues in Web Data Miming[C]. Proc. of Data Ware housing and Knowledge Discovery, First Inte1.Conf.DaWak 99.1999:303-312.
[3] 符發(fā).中文文本分類中特征選擇方法的比較[J].現(xiàn)代計算機,2008(6):43-45.
[4] JOACHIMS T. Text categorization with support vector machines: learning with many relevant features. In: Proceedings of 10th European Conference on Machine Learning(ECML-98), Chemnitz, DE.1998:137-142.
[5] 饒文碧,柯慧燕,張麗.一種擴展的基于VSM的Web文本分類算法[J].計算機應(yīng)用與軟件,2006,23(10).
[6] 雷景生.基于模糊相關(guān)的Web文檔分類方法[J].計算機工程,2005,31(24).
[7] 張志強,鄭家恒.基于加權(quán)類軸的Web文本分類方法研究[J].計算機應(yīng)用,2004,24(2).
[8] 胡和平,易高翔.一種基于容錯粗糙集的Web文檔分類方法[J].小型微型計算機系統(tǒng),2006,27(2).
[9] 馬光志,張生庭.基于關(guān)聯(lián)規(guī)則的Web文檔分類[J].計算機工程與設(shè)計,2005(9).
[10] AOKI P M. Generalizing search in generalized search trees. In Proc.1998 Int .Conf. Data Engineering(ICDE’98),April 1998.
[11] AGRAWAL R, IMIELINSKI T,SWAMI A. Mining association rules between sets of items in large database[A].Proceeding of the 1993 ACM SIGMOD International Conference on Management of Data[C]. New York: ACM Press, 1993:207-216.
[12] WU Xin Dong, ZHANG Cheng Qi, ZHANG Shi Chao. Mining both positive and negative association rules[A]. Proceedings of the 19th International Conference on Machine Learning (ICML-2002)[C]. San Francisco: Morgan Kaufmann Publishers, 2002: 658-665.
[13] ZHANG W X, ZHANG C, ZHANG S. Efficient Mining of both Positive and Negative Association Rules, ACM Transactions on Information Systems[J]. 2004,22:381-405.
[14] ZHU Y, SUN L, YANG H. Algorithm for Mining Negative Association Rules Based on Frequent Pattern Tree[J]. Computer Engineering,Vol.32, No.22.
[15] WANG D X, SONG S H. Study of Negative Association Rules[J]. Beijing Institute of Technology Journal,2004,24(11): 978-981.
[16] DONG X, SUN F, HAN X, et al. Study of Positive and Negative Association Rules Based on Multi-confidence and Chi-Squared Test[J]. LNAI 4093, Springer-Verlag Berlin Heidelberg, 2006:100-109.