
??? 摘 要:關聯規(guī)則是數據挖掘的主要技術之一,是描述數據庫中一組數據項之間的某種潛在關系的規(guī)則。以學生CET4成績數據為研究對象,運用關聯規(guī)則挖掘算法Apriori算法,找出學生CET4成績中聽力、閱讀、寫作、綜合測試四部分成績之間的關系,以及這四部分成績與總分之間的關系。
??? 關鍵詞:關聯規(guī)則;Apriori算法;頻繁項集;數據挖掘;CET4
?
??? 數據挖掘技術應用于教學管理中的主要方法是根據現有信息系統中的數據,挖掘高校教學管理工作中平常看不見、也無從知道的規(guī)律,以此來提高管理效率,幫助教師改進現有的教學方式和方法,從而增強高校的競爭優(yōu)勢。關聯規(guī)則形式簡潔,易于解釋和理解,并可以有效地捕捉數據間的重要關系。
1 關聯規(guī)則的原理
??? 一般地,關聯規(guī)則挖掘是指從一個大型的數據集中發(fā)現有趣的關聯或相關關系,即從數據集中識別出頻繁出現的屬性值集,也稱為頻繁項集(簡稱頻繁集),然后再利用這些頻繁集創(chuàng)建描述關聯規(guī)則的過程[1]。
??? 關聯規(guī)則可形式化定義為:
??? 設I={i1,i2,…,im}是由m個不同的項組成的集合。給定一個事務數據庫D,其中每一個事務T是I中一組項的集合,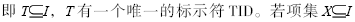
 則事務T包含項集X。
則事務T包含項集X。
??? 關聯規(guī)則是形如 并且X∩Y=Ф,如果D中事務包含X∪Y的百分比為S,則稱S為關聯規(guī)則X=>Y的支持度,它是概率P(X∪Y) ;如果D中包含X的事務同時也包含Y的百分比為C,則稱C為關聯規(guī)則X=>Y的置信度,它是條件概率P(Y/X)。習慣上將關聯規(guī)則表示為X=>Y(S%,C%)。
并且X∩Y=Ф,如果D中事務包含X∪Y的百分比為S,則稱S為關聯規(guī)則X=>Y的支持度,它是概率P(X∪Y) ;如果D中包含X的事務同時也包含Y的百分比為C,則稱C為關聯規(guī)則X=>Y的置信度,它是條件概率P(Y/X)。習慣上將關聯規(guī)則表示為X=>Y(S%,C%)。
??? 關聯規(guī)則的發(fā)現任務或問題就是在事務數據庫D中找出所具有用戶給定的最小支持度閾值(min_ sup)和最小置信度閾值(min_cof)的關聯規(guī)則,即這些關聯規(guī)則的支持度和置信度分別不小于最小支持度和最小置信度,這樣,每條被挖掘出來的關聯規(guī)則就可以用一個蘊涵式(X=>Y)和兩個閾值(最小支持度min_sup和最小置信度min_cof)表示[1]。
2 關聯規(guī)則挖掘算法
2.1 Apriori算法:使用候選項集找頻繁項集
??? Apriori算法通過對數據庫D的多次掃描來發(fā)現所有的頻繁項目集。在第一次掃描數據庫時,對項集I中的每一個數據項計算其支持度,確定出滿足最小支持度的頻繁1項集的集合L1,然后,L1用于找頻繁2項集的集合L2,如此下去……在后續(xù)的第k次掃描中,首先以k-1次掃描中所發(fā)現的含k-1個元素的頻繁項集的集合Lk-1為基礎,生成所有新的候選項目集CK(Candidate Itemsets),即潛在的頻繁項目集,然后掃描數據庫D,計算這些候選項目集的支持度,最后從候選集CK中確定出滿足最小支持度的頻繁k項集的集合Lk,并將Lk作為下一次掃描的基礎。重復上述過程直到再也發(fā)現不了新的頻繁項目集為止。
2.2 由頻繁項集產生關聯規(guī)則
??? 找出了所有的頻繁項集,由它們產生強關聯規(guī)則就很方便了(強關聯規(guī)則滿足最小支持度和最小置信度)。對于置信度,公式為:confidence(X=>Y)=P(Y|X)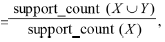 ,其中support_count(X∪Y)是包含項集X∪Y的事務數。support_count(X)是包含項集X的事務數。關聯規(guī)則產生如下:
,其中support_count(X∪Y)是包含項集X∪Y的事務數。support_count(X)是包含項集X的事務數。關聯規(guī)則產生如下:
??? 對于任意一個頻繁項集L和L的任何非空子集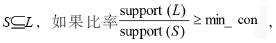 則生成關聯規(guī)則
則生成關聯規(guī)則 且該規(guī)則的置信度和支持度分別為:
且該規(guī)則的置信度和支持度分別為: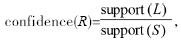 support(R)=support(L)[2]。
support(R)=support(L)[2]。
3 關聯規(guī)則的應用
??? 以下以Visual Foxpro6.0為工具進行討論。
3.1 數據預處理
??? 對現有的學生CET4成績進行數據預處理(Data preprocessing),包括2個步驟:數據清理(Data Clearing)和數據變換(Data Transformation)。
??? (1)數據清理:對表中的原始數據進行數據清理,消除一些冗余數據,消除噪聲數據,消除重復記錄。很多學生的CET4成績數據都為0,通過調查知道這些數據缺失的原因是學生未參加考試,把這些數據都從數據庫表中刪除。數據清理后的如圖1所示。
?
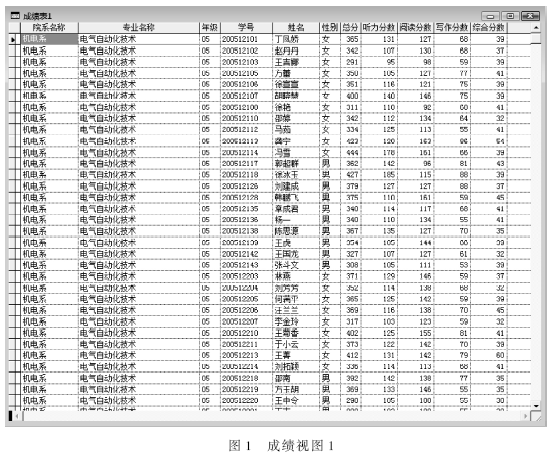
??? (2)數據變換:將數據轉換成適合于挖掘的形式。由于學生CET4成績是以數字的形式給出的,不利于數據挖掘的進行,因此需對聽力、閱讀、寫作、綜合測試4項的連續(xù)屬性值進行離散化處理,即轉換為優(yōu)秀、良好、中、及格、不及格5個等級。因為CET4的分值分配為:總分710,聽力249,閱讀249,寫作142,綜合測試70,所以要把分數換算為百分制。如分數高于85為“優(yōu)”,介于80~85之間為“良”,70~80之間為“中”,60~70之間為“及格”,60分以下為“不及格”。“不及格”、“及格”、“中”、“良”、“優(yōu)”設定為1、2、3、4、5;用“A”代表總分,“B”代表聽力分數,“C”代表閱讀分數,“D”代表寫作分數,“E”代表綜合測試分數;將除了學號的所有字段都改為字符型。數據變換后如圖2所示,總計1 814條記錄。
?

3.2 設計思路
3.2.1求解頻繁項集
??? 圖2中的學生成績表.DBF為本文要研究的事務數據庫,它有6個字段,均為字符型。求解頻繁項集步驟如下:
??? (1) 建立一個項目數據表ITEM.DBF,該表中有1個字段,字段名為A,數據類型為字符型,用于存放CET4成績中每個組成部分的所有分數段的表達值,該表中每條記錄代表一種表達值,表中的記錄數就是表達值形式的數目。該數據表中的記錄升序排列,分別為a1、a2、a3、b1、b2、b3、c1、c2、c3、d1、d2、d3、d4、e1、e2、e3、e4、e5。
??? (2) 建立6個空數據表FRENQ1、FRENQ2、FRENQ3、FRENQ4、FRENQ5、FRENQ6,分別用來存放1、2、3、4、5、6頻繁項集和它們的支持度計數。其中FRENQ1中有2個字段A、SUP,FRENQ2有3個字段A、B、SUP,FRENQ3有4個字段A、B、C、SUP,FRENQ4有5個字段A、B、C、D、SUP,FRENQ5有6個字段A、B、C、D、E、SUP,FRENQ6有7個字段A、B、C、D、E、F、SUP,只有SUP為數值型,其余的數據類型均為字符型。
??? (3) 利用成績表產生一個輔助數據表ITEM1,該表中只有一個字段ITEMSET ,數據類型為字符型,記錄數與成績數據表相同,數據為成績表中的A+B+C+D+E的值。
??? (4) 在求每個頻繁項目集時,分2步進行:第1步產生候選項,第2步生成頻繁項目集。具體過程如下:首先,掃描ITEM表中每一條記錄,對應在ITEM1.DBF求出所有的長度為1的該候選項的支持度,如果支持度大于給定的最小支持度,就把它存入FRENQ1.DBF中,直至把ITEM中的記錄數掃描完為止。隨后,利用FRENQ1.DBF產生長度為2的候選項,掃描ITEM1.DBF求出所有長為2的該候選項集的支持度, 如果支持度大于給定的最小支持度,就存入FRENQ2.DBF中,直至掃描完FRENQ1.DBF中的記錄為止。其余的以此類推,直到求出所有的頻繁項目集。若發(fā)現某頻繁項集的數目為零,則停止計算。最后,輸出所有項目的頻繁集。在該程序中依然運用了Apriori算法的性質:如果一個項集是頻繁的,則它的所有子集也是頻繁的[3-6]。
??? 設定最小支持度為0.04,支持度計數為73,產生了79個頻繁項集。實驗結果如圖3所示。
?
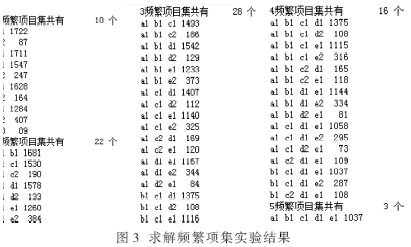
3.2.2 提取關聯規(guī)則
??? 從已經產生的頻繁項集中確定它們的子集,然后根據關聯規(guī)則的挖掘算法原理,假設最小置信度為30%,由程序得出350個關聯規(guī)則。部分試驗結果如圖4所示。
?

?
4 結果分析
??? (1) 聽力、寫作與總分之間的關系是雙向的,即聽力或寫作分較低,總分一般也較低;反之,總分較低,聽力或寫作也較低。因為對于學生而言,一般學習聽力、寫作的主動性較差,而這兩種題型也是一般學生考試中最棘手的題型。
??? (2) 閱讀、綜合測試和總分之間的關系主要表現為單向,即閱讀、綜合測試分較低,總分極有可能較低,但反之未必。這是由于CET4中的閱讀和綜合測試兩項的分值比例相對較大引起的。
??? (3) 任意兩項(或兩項以上)得分較低,總分都較低。其中,聽力和閱讀是影響總分最大的兩個因素。
??? (4) 在聽力、閱讀、寫作和綜合測試四項中,綜合測試題得分與其他三項得分的關系相對較小;而聽力和寫作則與閱讀和綜合測試的關系比較緊密。
??? (5) 從與總分的關系,以及與其余單項的關系來看,聽力、閱讀、寫作和綜合測試四項中,聽力是最突出的。
??? 最后得出這樣一個結論:在日常教學中應進一步強調聽力題的重要地位,進一步加強聽力的訓練。
??? 關聯規(guī)則的應用很廣泛。本文根據關聯規(guī)則的挖掘過程,對學生CET4成績的各個部分進行了分析。利用Apriori算法,借助于計算機,可以對于海量數據進行分析,從而可以進行更為全面和客觀的預測與決策。分析的結果將會對某門課程的教學提供大量有用的信息,從而指導我們的教學。
參考文獻
[1] 陳文偉,黃金才. 數據倉庫與數據挖掘[M]. 北京:人民郵電出版社,2004.
[2]?韓家煒. 數據挖掘概念與技術[M]. 北京:機械工業(yè)出版社,2000.
[3]?齊曉峰. 數據挖掘技術在學生成績管理中的應用研究[D]. 阜新:遼寧工程技術大學,2006.
[4]?趙輝. 數據挖掘技術在學生成績分析中的研究及應用[D].大連: 大連海事大學,2007.
[5]?陸楠. 關聯規(guī)則的挖掘及其算法的研究[D]. 長春:吉林大學,2007
[6]?羅可,吳建華,吳杰. 一種用Visual Foxpro求頻繁項目集的方法[J]. 計算機工程,2001(5).