
1993年Berrou C. 等學者提出的Turbo碼將卷積編碼和隨機交織結(jié)合在一起實現(xiàn)了隨機編碼的思想[1],并且采用了軟輸入軟輸出(SISO)迭代譯碼的最大似然譯碼算法,從而使其譯碼性能接近于Shannon理論的極限。目前,Turbo碼的應(yīng)用已推廣到深空通信、衛(wèi)星通信和移動通信等領(lǐng)域,并被確定為第三代移動通信的信道編碼方案之一。
在不同的應(yīng)用環(huán)境中,出于對譯碼性能和譯碼復雜度的考慮,通常選用不同的譯碼參數(shù)。其中直接影響到譯碼性能的關(guān)鍵參數(shù)有幀長、交織表和迭代次數(shù)等。本文介紹的基于KCPSM的Turbo譯碼器在設(shè)計中引入嵌入式處理器單元,通過存儲于外部RAM中的程序控制譯碼過程,可根據(jù)不同的使用需求修改程序代碼以適用于各種不同的譯碼情況。
1 Turbo譯碼原理
Turbo碼的特點:編碼器中引入了交織器,減弱了信息序列的相關(guān)性,有效地實現(xiàn)了隨機性編碼;在譯碼時采取了迭代譯碼的思想,使其性能可以接近香農(nóng)理論的極限。
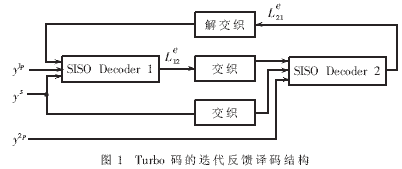
Turbo碼的迭代反饋譯碼結(jié)構(gòu)如圖1所示[2]。圖中,SISO Decoder 1和SISO Decoder 2是分別對應(yīng)于編碼產(chǎn)生的兩組分量碼的軟輸入軟輸出譯碼器。兩個SISO譯碼器通過反復的交錯重復譯碼計算完成對輸入信息序列的譯碼。SISO Decoder 1的軟輸出信息交織后作為SISO Decoder 2譯碼的先驗信息。如果迭代結(jié)束,SISO Decoder 2的譯碼結(jié)果硬判決輸出;否則,SISO Decoder 2的軟輸出信息反交織后作為SISO Decoder 1下一次迭代譯碼的先驗信息。
在Turbo碼的譯碼算法中,MAP算法的性能最好,但計算量巨大,硬件實現(xiàn)的復雜度高,譯碼時延大。所以在硬件設(shè)計中采用的是在對數(shù)域上簡化的Log-MAP算法,這樣可以有效地降低硬件設(shè)計的復雜度。在Log-MAP譯碼算法中,需要先從數(shù)據(jù)序列末端向始端做反向狀態(tài)概率β的遞推計算,之后再從序列的始端向末端開始遞推計算前向狀態(tài)概率α并得到對數(shù)概率似然比。為了減少譯碼的等待延時,在譯碼時可將原先的一幀數(shù)據(jù)序列按特定的分組長度分解為數(shù)段,分別計算每段的軟輸出。在每段序列的計算中,仍然是先反向遞推計算β值,再正向遞推計算α值。其中,α值遞推的初始值由上一段的計算結(jié)果給出。對于β值的遞推,則需由下一段序列提供部分軟信息。
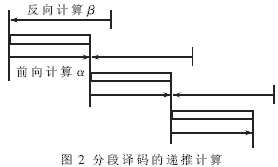
圖2表述了分段譯碼的思想。采用分段譯碼時,用于存放中間結(jié)果的存儲器規(guī)模取決于分組長度,不再與幀長成正比。對于不同幀長的譯碼只需改變交織表的大小,而譯碼單元不用改變。這樣的譯碼器可以更方便地用于各種碼長的譯碼。
2 Turbo譯碼器的設(shè)計
基于KCPSM的Turbo譯碼器基本可分為兩個部分:TurboDec譯碼模塊和KCPSM主控模塊。
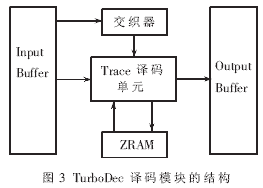
TurboDec譯碼模塊的結(jié)構(gòu)如圖3所示。它由Trace譯碼單元、存儲單元和交織器組成。Trace譯碼單元的作用是根據(jù)Log-MAP算法,對分組后的每段序列做前向或反向的遞推計算。存儲單元包括ZRAM(用于存放在運算過程中需要交換的外信息)、Input Buffer和Output Buffer(分別用于輸入輸出的緩存)。交織器的作用是實現(xiàn)對數(shù)據(jù)序列的交織和反交織,它主要是一塊存有交織表的RAM,而交織表內(nèi)存放有每位數(shù)據(jù)交織后對應(yīng)的地址。Trace譯碼單元通過查找該交織表得到的地址作為以交織順序讀取或?qū)懭霐?shù)據(jù)的地址。這塊RAM中的交織表可在譯碼前由外部改寫,以滿足不同的譯碼需求。
KCPSM主控模塊采用的是Xilinx公司提供的PicoBlaze嵌入式處理器設(shè)計方案[3]。該模塊中主要有兩部分:負責數(shù)據(jù)信號處理及對外信號輸入輸出的PicoBlaze處理器單元和用于儲存程序指令代碼的Block Memory。PicoBlaze設(shè)計方案的結(jié)構(gòu)如圖4所示。
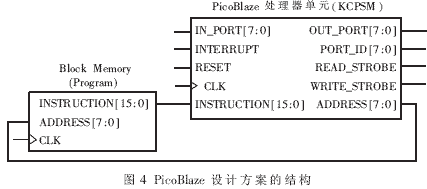
在時鐘信號的驅(qū)動下,PicoBlaze處理器單元根據(jù)當前的8位地址從Block Memory中讀取對應(yīng)的16位指令代碼,再根據(jù)此指令代碼完成運算操作,同時產(chǎn)生下一步指令的地址。根據(jù)不同指令的要求,在IN_PORT端和OUT_PORT端分別讀入或輸出計算的數(shù)據(jù),并在PORT_ID端指明對應(yīng)的I/O端口地址。READ_STROBE端和WRITE_STROBE端則在執(zhí)行讀寫操作時輸出脈沖信號,該脈沖信號通常用于控制外圍電路的讀寫。
3 KCPSM控制系統(tǒng)的設(shè)計
3.1KCPSM設(shè)計的特點
KCPSM是常變量可編程狀態(tài)機的簡稱,其主要組成部分為嵌入式處理器單元,用于實現(xiàn)基于常量的狀態(tài)機主控單元。與傳統(tǒng)的基于時序電路的狀態(tài)機控制設(shè)計相比,使用KCPSM作為主控單元有以下特點:
(1)結(jié)構(gòu)簡單,占用資源少。以Xilinx公司推出的8位嵌入式微處理器IP核PicoBlaze為例,其邏輯模塊僅占用Spartan-IIE的76個slice,相當于最小的XC2S50E器件可用資源的9%,或XC2S300E器件可用資源的2.5%。對于較大規(guī)模的設(shè)計幾乎可以忽略這樣的資源占用。雖然該IP核占用的硬件資源很少,但它的運算性能可以達到40MIPS。因其占用資源少,在實際設(shè)計中可以同時使用多個KCPSM以完成復雜的控制功能。
(2)使用靈活,易于調(diào)試。對于KCPSM單元,控制狀態(tài)的轉(zhuǎn)換及相關(guān)信號的處理都是以程序指令的形式存儲于Block RAM單元中,不涉及到IP核的邏輯模塊單元。使用時只需要根據(jù)不同的目的編寫相應(yīng)的指令代碼就可實現(xiàn)不同的功能。特別是在對電路進行調(diào)試時,易于實現(xiàn)特定的非正常運行狀態(tài)。
(3)指令周期相對較長。KCPSM采用的是從Block RAM單元讀取指令的操作模式,每步操作的完成包括確定RAM地址和讀取指令兩步,需要花費兩個時鐘周期。與由時序電路組成的狀態(tài)機相比,KCPSM的運行效率較低,不適合用于對時鐘沿敏感情況下的控制需要。
由上面幾點可以看出,KCPSM作為可編程的控制單元,適合用于情況比較復雜但對時間要求不高的系統(tǒng)級控制,特別是有大量控制參數(shù)需要計算調(diào)整的情況。相對于由時序單元組成的控制電路,它在節(jié)省硬件開銷的同時,降低了設(shè)計的復雜性,增強了設(shè)計的靈活性。
3.2Turbo譯碼的控制設(shè)計
根據(jù)Turbo碼的迭代譯碼原理,KCPSM控制系統(tǒng)的基本流程如圖5所示。從圖中可以看出,該控制系統(tǒng)根據(jù)Turbo譯碼器當前的工作狀態(tài)檢測對應(yīng)的控制信號并改變輸出參數(shù)。當譯碼器沒有處于譯碼狀態(tài)時,KCPSM會周期性地檢測譯碼啟動信號。該信號有效后,Turbo譯碼器進入譯碼狀態(tài),KCPSM向TurboDec譯碼模塊輸出第一次反向遞推譯碼計算的起始地址、譯碼段長度等參數(shù)和控制信號,同時準備下一次前向遞推的相關(guān)參數(shù)。譯碼器進入譯碼狀態(tài)后,KCPSM改為檢測TurboDec譯碼模塊的譯碼完成信號。當TurboDec完成遞推譯碼計算后,KCPSM根據(jù)迭代次數(shù)決定是否還需要進行下一次的遞推計算。若迭代譯碼過程尚未結(jié)束,KCPSM會控制TurboDec譯碼模塊開始新一次的遞推計算,并為下次的遞推計算相關(guān)參數(shù)。迭代譯碼結(jié)束后,KCPSM使TurboDec譯碼模塊輸出譯碼結(jié)果,并控制Turbo譯碼器退出譯碼狀態(tài)。
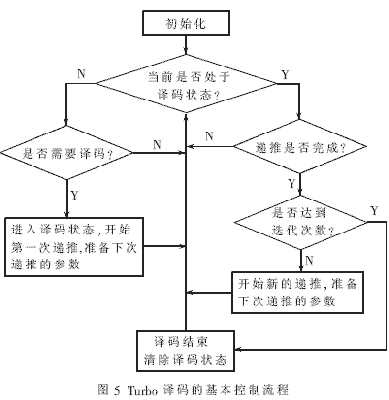
在整個譯碼過程中,KCPSM將Turbo譯碼器的狀態(tài)以編碼的形式存儲在內(nèi)部的寄存器中,并根據(jù)譯碼的要求和遞推計算的次數(shù)確定下次遞推譯碼的參數(shù)。TraceDec譯碼單元對前向狀態(tài)概率的計算與對反向狀態(tài)概率的計算是交替進行的,在每次譯碼操作后都要改變下次譯碼遞推的方向。譯碼的起始地址和譯碼段的長度由譯碼方向和已完成的譯碼長度確定。對位于幀尾的最后一段序列,譯碼的起始地址和譯碼段的長度需根據(jù)剩余的序列長度進行調(diào)整。由于只有一個TurboDec譯碼模塊作為SISO譯碼器,在結(jié)束一次MAP譯碼后,下一次的MAP譯碼需采用不同的校驗序列,以實現(xiàn)對兩組校驗信息的充分利用。
在Turbo譯碼過程中,KCPSM要將多個參數(shù)傳遞給TurboDec譯碼模塊,為此需要同時使用OUT_PORT和PORT_ID兩個輸出端口。將這些參數(shù)分別看作KCPSM的不同“虛擬端口”,為每個輸出參數(shù)設(shè)定一個特定的PORT_ID。KCPSM輸出數(shù)據(jù)后,TurboDec譯碼模塊根據(jù)PORT_ID的數(shù)值判斷當前OUT_PORT端輸出的是什么參數(shù)。
4 性能分析
本設(shè)計采用Xilinx公司的Spartan-IIE系列作為目標器件,采用Xilinx ISE作為開發(fā)環(huán)境。根據(jù)設(shè)計的綜合情況,在硬件資源方面,該Turbo碼譯碼器的邏輯模塊占用了829個slice,而存儲模塊則占用了56Kbit的BlockRAM,最高時鐘頻率約達到50MHz。根據(jù)RAM單元的使用情況,該譯碼器可完成對最大幀長為3 084位的輸入序列的譯碼。
從以上數(shù)據(jù)可以看出,在使用相對較少硬件資源的情況下,基于KCPSM的Turbo譯碼器提供了很好的譯碼性能,同時因在設(shè)計時就考慮了靈活性的問題,使其可以很方便地根據(jù)實際使用調(diào)整譯碼參數(shù),擴大了應(yīng)用范圍。
本文介紹了基于KCPSM的Turbo譯碼器設(shè)計,并結(jié)合該設(shè)計說明了基于嵌入式處理器單元的系統(tǒng)設(shè)計方法。通過引用Xilinx公司提供的嵌入式處理器IP核,該設(shè)計在提供良好譯碼性能的同時,在使用上也具有很好的靈活性。
隨著通信技術(shù)的發(fā)展,對譯碼電路的性能要求也將不斷提高。本文提出的設(shè)計方案也可作為實用ASIC芯片設(shè)計方案的參考。基于嵌入式處理器的設(shè)計思想可使ASIC設(shè)計芯片具有很好的通用性。