
摘 要: 針對模糊c-均值(FCM)聚類算法受初始聚類中心影響,易陷入局部最優(yōu),以及算法對孤立點數(shù)據(jù)敏感的問題,提出了解決方案:采用快速減法聚類算法初始化聚類中心,為每個樣本點賦予一個定量的權(quán)值,用來區(qū)分不同的樣本點對最終的聚類結(jié)果的不同作用,為提高聚類速度采用修正隸屬度矩陣的方法,并將算法與傳統(tǒng)的FCM相比。實驗結(jié)果表明,該算法較好地解決了初值問題,與隨機初始化方法相比,迭代次數(shù)少、收斂速度快、具有較好的聚類結(jié)果。
關(guān)鍵詞: 模糊c-均值; 減法聚類; 權(quán)值
模糊聚類作為無監(jiān)督機器學(xué)習(xí)的主要技術(shù)之一,廣泛應(yīng)用于數(shù)據(jù)挖掘、矢量量化、圖像分割、模式識別、醫(yī)學(xué)診斷等領(lǐng)域。引入模糊數(shù)學(xué)方法,通過建立數(shù)據(jù)樣本類屬的不確定描述,將相似性質(zhì)的事物分開并加以分類,能比較客觀地反映現(xiàn)實世界。
模糊c-均值(FCM)算法是模糊聚類的基本方法之一,它是一種聚類不定歸屬的方法。它通過引入隸屬度函數(shù)來表示每個樣本點屬于各個類別的程度,從而決定樣本點的類屬,對數(shù)據(jù)進行軟劃分。
FCM算法就是通過搜索目標函數(shù)的最小點,反復(fù)修改聚類中心矩陣和隸屬度矩陣的分類過程。目前算法的收斂性已得到證明[1],但它是一種局部搜索算法,對初值的選取十分敏感,如果初值選取不當(dāng),它容易收斂到局部極小點。且FCM對孤立點數(shù)據(jù)、樣本分布不均衡也很敏感。鑒于此,提出基于減法聚類的改進的模糊c-均值聚類,使得算法的收斂速度和準確性都得以改善。
1 模糊c-均值算法分析


2 基于減法聚類的改進的模糊c-均值算法
2.1初始聚類中心的選擇
減法聚類是一種爬山法,它把所有的樣本點作為聚類中心的候選點,其基本思想是計算每個樣本點的密度指標,如果該樣本點周圍的點多,則密度指標就大,就選取密度指標最大的樣本點作為聚類中心。減法聚類是一種快速獨立的近似的聚類方法,用它計算,計算量由樣本數(shù)目決定且與樣本點的數(shù)目成簡單的線性關(guān)系,而且與所考慮問題的維數(shù)無關(guān)。


(2) 修正隸屬度矩陣
FCM算法的思想是:迭代調(diào)整隸屬矩陣和聚類中心使目標函數(shù)值最小,為保證FCM算法每次的迭代都朝著全局最優(yōu)的方向逼近,其關(guān)鍵就在于保證確定V的下一次迭代值,加快收斂于全局最優(yōu)點的速度。在此采用修正隸屬矩陣來計算下一次迭代的聚類中心,使得到的V更靠近聚類中心,更合理,從而提高FCM算法的收斂速度。因此修正隸屬度矩陣[5]可以提高聚類速度,使聚類效果更好。
樣本離聚類中心距離越遠屬于該聚類中心的程度越小,反之越大,樣本對類中心的影響即稱為樣本對類中心施加的吸引力,在這里設(shè)定了一個抑制因子,由它來控制對離樣本點次最近的類中心的抑制作用。
當(dāng)α=1時,算法退化為FCM算法,對離樣本點次最近的類中心沒有任何抑制作用。
當(dāng)α=0時,算法完全抑制了樣本對離它次最近類中心的吸引力,對離樣本最近類中心的吸引力的增強力度最大。
當(dāng)1<α<0時,算法對離樣本次最近類中心的吸引力有一定的抑制作用,對離樣本最近類中心的吸引力有一定的增加作用。
修正隸屬度矩陣的過程如下:

(5) 判斷是否終止迭代。終止而退出,否則,L=L+1,返回步驟(2),繼續(xù)迭代。
經(jīng)過對隸屬度矩陣的修正可知:改進后的算法,樣本點增大了對離它最近的類中心的吸引力強度;樣本點減小了對離它次最近的類中心的吸引力強度,從而減弱了離樣本次最近類中心對離樣本最近的類中心收斂速度的延緩作用。對其余類中心的吸引力強度不變,從而提升了FCM算法的收斂速度。
2.3 基于減法聚類改進的模糊c-均值算法過程
為保證改進的FCM聚類結(jié)果為全局最優(yōu)解,采用減法聚類的聚類中心作為改進的FCM聚類的初始聚類中心。算法步驟如下:
(1) 設(shè)定聚類參數(shù):領(lǐng)域的半徑ra、rb,比例參數(shù)δ,F(xiàn)CM聚類數(shù)c,模糊指數(shù)m和最小誤差ε,迭代次數(shù)L,吸引力抑制因子α。
(2) 應(yīng)用式(4)計算所有樣本點的密度指標,將密度指標最高的一個作為第一個聚類中心點xc1。
(3) 依據(jù)公式(5)利用減法步驟(2)中的xc1進一步計算余下的n-1個數(shù)據(jù)點的密度指標,找出最高的作為第二個聚類中心xc2,依此類推,找到p個聚類中心,從中選取前c個作為FCM的初始聚類中心v(0)。
減法聚類中心中,密度指標越大的聚類中心出現(xiàn)得越早,越有可能成為改進的FCM初始聚類中心。所以,當(dāng)聚類數(shù)為c時,取減法聚類產(chǎn)生的前c個聚類中心作為改進的FCM的初始中心,無須再重新初始化,從而提高了聚類的效率。
(4) 求式(10)的最小值
(5) 按式(11)和式(12)計算出隸屬度U(L)
(6) 依據(jù)式(13)和式(14)修正隸屬度矩陣U(L)。
(7) 依據(jù)式(15),用修正后的U(L)計算下一次的迭代中心V(L+1)。
(8) 判斷是否滿足終止迭代條件。對給定的閾值,
‖U(L+1)-U(L)‖<ε如果終止而退出,否則,L=L+1,返回步驟(5),繼續(xù)迭代。
3 仿真與結(jié)果分析

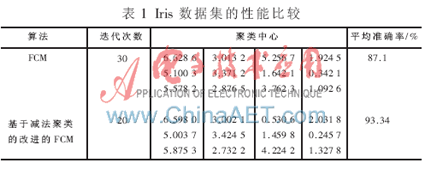
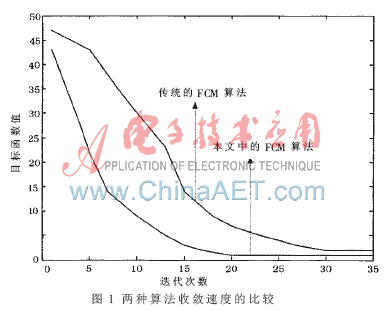
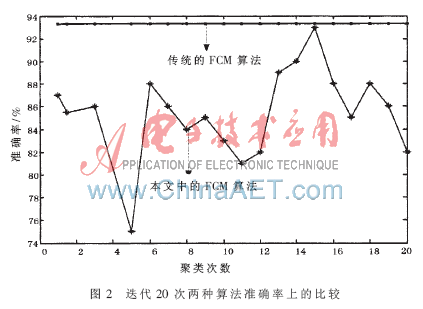
從圖1、圖2與表1中可以看出,傳統(tǒng)FCM與本文中的算法相比迭代次數(shù)少、搜索速度更快、聚類平均準確率更高。
基于減法聚類的改進的FCM算法很好地解決了FCM算法對初始值敏感及易陷入局部最優(yōu)的問題,同時也改善了FCM對孤立點敏感的問題,提高了聚類的速度,具有很高的實用價值。
參考文獻
[1] GAMES R A, CHAN A H. A fast algorithm for determining the linear complexity of a pseudorandom sequence with period 2n[J].IEEE Trans Inf Theory ,1983,IT-29(1):144-146.
[2] HAND D, MANNILA H, SMYTH P. Principles of data mining [M].Cambridge MA:MITPress,2001.
[3] PAL N R, CHAKRABORTY D. Mountain and subtractive clustering method; Improvements and Generalization. International Journal of Intelligent Systems , 2000,15 (4):329-341.
[4] 齊淼,張化祥.改進的模糊c-均值聚類算法研究[J].計算機工程與應(yīng)用,2009,45(20).
[5] 閆兆振.自適應(yīng)模糊c-均值聚類算法研究[D]. 濟南:山東科技大學(xué),2006.