
摘 要: 介紹采用聲紋識別" title="聲紋識別">聲紋識別技術(shù)、在凌陽SPCE061A[1]單片機上實現(xiàn)的一種語音電子門鎖身份認證系統(tǒng)。實驗結(jié)果表明,系統(tǒng)性能穩(wěn)定,識別效果好,可以推廣使用。
關(guān)鍵詞: 聲紋識別 基音周期 線性預測 模式匹配 DTW
生物識別技術(shù)[2]是利用人體生物特征進行身份認證的一種技術(shù),是目前公認的最為方便與安全的識別技術(shù)。由于每個人的生物特征具有與其他人不同的惟一性和在一定時期內(nèi)不變的穩(wěn)定性,不易偽造和假冒,所以利用生物識別技術(shù)進行身份認定,安全、準確、可靠。
在生物識別領(lǐng)域中,聲紋識別,也稱為說話人識別" title="說話人識別">說話人識別,以其獨特的方便性、經(jīng)濟性和準確性等優(yōu)勢受到世人矚目,并日益成為人們?nèi)粘I詈凸ぷ髦兄匾移毡榈陌踩J證方式。聲紋識別是一種根據(jù)說話人語音波形中反映說話人生理和行為特征的語音參數(shù),自動識別說話人身份的技術(shù)。
聲紋識別技術(shù)可分為兩類,即說話人辨認和說話人確認。前者用以判斷某段語音是若干人中的哪一個所說的,是多選一的問題;而后者用以確認某段語音是否是指定的某個人所說的,是一對一判別的問題。從另一方面,聲紋識別又有與文本有關(guān)和與文本無關(guān)兩種,根據(jù)特定的任務和應用,應用范圍不同。與文本有關(guān)的聲紋識別系統(tǒng)要求用戶按照規(guī)定的內(nèi)容發(fā)音,每個人的聲紋模型逐個被精確地建立,而識別時也必須按規(guī)定的內(nèi)容發(fā)音,因此可以達到較好的識別效果;而與文本無關(guān)的識別系統(tǒng)則不規(guī)定說話人的發(fā)音內(nèi)容,模型建立相對困難,但用戶使用方便,應用范圍較寬。
本文介紹的語音電子門鎖是一種在凌陽16位單片機SPCE061A上實現(xiàn)的與文本有關(guān)的說話人確認系統(tǒng)。該系統(tǒng)主要由說話人識別模塊、門鎖控制電機以及門鎖等部分組成。在訓練時,說話人的聲音通過麥克風進入說話人語音信號" title="語音信號">語音信號采集前端電路,由語音信號處理電路對采集的語音信號進行特征化和語音處理,提取說話人的個性特征參數(shù)" title="特征參數(shù)">特征參數(shù)并進行存儲,形成說話人特征參數(shù)數(shù)據(jù)庫。在識別時,將待識別語音與說話人特征參數(shù)數(shù)據(jù)庫進行匹配,通過輸出電路控制門鎖電機,最終實現(xiàn)對門鎖的控制。
1 算法原理
說話人識別算法原理框圖如圖1所示。
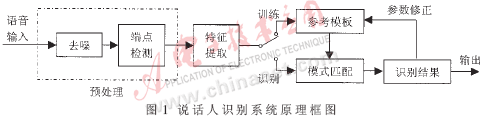
1.1 預處理
(1)去噪
對麥克風輸入的模擬語音信號進行量化和采樣,獲得數(shù)字化的語音信號;再將含噪的語音信號通過去噪處理,得到干凈的語音信號后并通過預加重技術(shù)濾除低頻干擾,尤其是50Hz或60Hz的工頻干擾,提升語音信號的高頻部分,而且它還可以起到消除直流漂移、抑制隨機噪聲和提升清音部分能量的作用。
(2)端點檢測
本系統(tǒng)采用語音信號的短時能量和短時過零率進行端點檢測。語音信號的采樣頻率為8kHz,每幀數(shù)據(jù)為20ms,共計160個采樣點。每隔20ms計算一次短時能量和短時過零率。通過對語音信號的短時能量和短時過零率檢測可以剔除掉靜默幀、白噪聲幀和清音幀,最后保留對求取基音、LPCC等特征參數(shù)非常有用的濁音信號。
1.2 特征提取
在語音信號預處理后,接著是特征參數(shù)的提取。特征提取的任務就是提取語音信號中表征人的基本特征。
1.2.1 特征參數(shù)的選取
選取的特征必須能夠有效地區(qū)分不同的說話人,且對同一說話人的變化保持相對穩(wěn)定,同時要求特征參數(shù)計算簡便,最好有高效快速算法,以保證識別的實時性。
說話人特征大體可歸為下述幾類:
(1)基于發(fā)聲器官如聲門、聲道和鼻腔的生理結(jié)構(gòu)而提取的參數(shù)。如譜包絡、基音、共振峰等。其中基音能夠很好地刻畫說話人的聲帶特性,在很大程度上反映了人的個性特征。
(2)基于聲道特征模型,通過線性預測分析得到的參數(shù)。包括線性預測系數(shù)(LPC)以及由線性預測導出的各種參數(shù),如線性預測倒譜系數(shù)(LPCC)、部分相關(guān)系數(shù)、反射系數(shù)、對數(shù)面積比、LSP線譜對、線性預測殘差等。根據(jù)前人的工作成果和實際測試比較,LPCC參數(shù)不但能較好地反映聲道的共振峰特性,具有較好地識別效果,而且可以用比較簡單的運算和較快的速度求得。
(3)基于人耳的聽覺機理,反映聽覺特性,模擬人耳對聲音頻率感知的特征參數(shù)。如美爾倒譜系數(shù)(MFCC)等。MFCC參數(shù)與基于線性預測的倒譜分析相比,突出的優(yōu)點是不依賴全極點語音產(chǎn)生模型的假定,在與文本無關(guān)的說話人識別系統(tǒng)中MFCC參數(shù)能夠比LPCC參數(shù)更好地提高系統(tǒng)的識別性能[3]。
此外,人們還通過對不同特征參量的組合來提高實際系統(tǒng)的性能。當各組合參量間相關(guān)性不大時,會有較好的效果,因為它們分別反映了語音信號的不同特征。
在計算機平臺的仿真實驗中,通過各種參數(shù)的實際比較,采用MFCC參數(shù)比采用LPCC參數(shù)有更好的識別效果。但在SPCE061A平臺上做實時處理時,與LPCC系數(shù)相比,MFCC系數(shù)計算有兩個缺點:一是計算時間長;二是精度難以保證。由于MFCC系數(shù)的計算需要FFT變換和對數(shù)操作,影響了計算的動態(tài)范圍;要保證系統(tǒng)識別的實時性,就只有犧牲參數(shù)精度。而LPCC參數(shù)的計算有遞推公式,速度和精度都可以保證,識別效果也滿足實際需要。
本系統(tǒng)采用了基音周期和線性預測倒譜系數(shù)(LPCC)共同作為說話人識別的特征參數(shù)。
1.2.2 LPCC參數(shù)的提取
基于線性預測分析的倒譜參數(shù)LPCC可以通過簡單的遞推公式由線性預測系數(shù)求得。遞推公式如下:
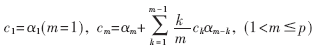
其中p為LPC模型的階數(shù),也是模型的極點個數(shù)。
(1)LPC模型階數(shù)p的確定
為使模型假定更好地符合語音產(chǎn)生模型,應該使LPC模型的階數(shù)p與共振峰個數(shù)相吻合,其次是考慮聲門脈沖形狀和口唇輻射影響的補償。通常一對極點對應一個共振峰,10kHz采樣的語音信號通常有5個共振峰,取p=10,對于8kHz采樣的語音信號可取p=8。此外為了彌補鼻音中存在的零點以及其他因素引起的偏差,通常在上述階數(shù)的基礎上再增加兩個極點,即分別是p=12和p=10。實驗表明,選擇LPC分析階數(shù)p=12,對絕大多數(shù)語音信號的聲道模型可以足夠近似地逼近。p值選得過大雖然可以略微改善逼近效果,但也帶來一些負作用,一方面是加大了計算量,另一方面有可能增添一些不必要的細節(jié)。
(2)線性預測系數(shù)的求取
自相關(guān)解法主要有杜賓(Durbin)算法、格型(Lattice)算法和舒爾(Schur)算法等幾種遞推算法。其中杜賓算法是目前最常用的算法,而且在求取LPC系數(shù)時計算量也最小,本系統(tǒng)采用該遞推算法[4]。
1.2.3 基音參數(shù)的提取
基音估計的方法很多,主要有基于短時自相關(guān)函數(shù)和基于短時平均幅度差函數(shù)(AMDF)等基音估計方法。
(1)基于短時自相關(guān)函數(shù)的基音估計[4]
短時自相關(guān)函數(shù)在基音周期的整數(shù)倍位置存在較大的峰值,只要找出第一最大" title="最大">最大峰值的位置就可以估計出基音周期。
(2)基于短時平均幅度差函數(shù)(AMDF)的基音估計[4]
基于短時平均幅度差函數(shù)(AMDF)在基音周期的整數(shù)倍位置存在較大的谷值,找到第一最大谷值的位置就可以估計出基音周期。這種方法的缺點是當語音信號的幅度快速變化時,AMDF函數(shù)的谷值深度會減小,從而影響基音估計的精度。
實際上第一最大峰(谷)值點的位置有時并不能與基音周期吻合,第一最大峰(谷)值點的位置與短時窗的長度有關(guān)且會受到共振峰的干擾。一般窗長至少應大于兩個基音周期,才可能獲得較好的估計效果。語音中最長基音周期值約為20ms,本系統(tǒng)在估計基音周期時窗長選擇40ms。為了減小共振峰的影響,首先對語音進行頻率范圍為[60,900]Hz的帶通濾波。因為最高基音頻率為450Hz,所以將上限頻率設為900Hz可以保留語音的一、二次諧波,下限頻率為60Hz是為了濾除50Hz的電源干擾。
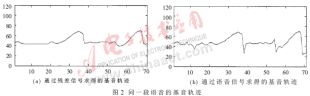
以上兩種方法都是對語音信號本身求相應的函數(shù)。本系統(tǒng)采用的基音估計方法是:首先對帶通濾波后的短時語音信號進行線性預測,求取預測殘差;再對殘差信號求自相關(guān)函數(shù),找出第一最大峰值點的位置,即得到該段語音的基音估計值。實驗表明,通過殘差求取的基音軌跡比直接通過語音求取的基音軌跡效果更好,如圖2所示。圖2中橫坐標為語音幀數(shù),縱坐標為8000/f,其中f為基音頻率。
1.3 模式匹配
目前針對各種特征參數(shù)提出的模式匹配方法的研究越來越深入。典型的方法[4]有:矢量量化方法、高斯混合模型方法、隱馬爾可夫模型方法、動態(tài)時間規(guī)整(DTW)方法和人工神經(jīng)網(wǎng)絡方法。
這些方法都有各自的優(yōu)點和缺點。其中DTW算法對于較長語音的識別,模板匹配運算量太大,但對短語音(有效語音長度低于3s)的識別既簡單又有效,而且并不比其他方法識別率低,特別適用于短語音、與文本有關(guān)的說話人識別系統(tǒng)。本系統(tǒng)采用端點松弛兩點的(DTW)算法,端點松弛引起的計算量增加并不大,還可以放松對端點檢測的精度要求。
動態(tài)時間規(guī)整(DTW)算法基于動態(tài)規(guī)劃的思想,解決了說話人不同時期發(fā)音長短、語速不一樣的匹配問題。DTW算法用于計算兩個長度不同的模板之間的相似程度,用失真距離表示。假設測試模板和參考模板分別用T和R表示,按時間順序含有N幀和M幀的語音參數(shù)(本系統(tǒng)為12維LPCC參數(shù)),失真距離越小,表示T、R越接近。把測試模板的各個幀號n=1~N在一個二維直角坐標系中的橫軸上標出,把參考模板的各幀號m=1~M在縱軸上標出,如圖3所示。通過這些表示幀號的整數(shù)坐標畫出縱橫線即形成網(wǎng)格,網(wǎng)格中的每一個交叉點(n,m)表示測試模板中某一幀與參考模式中某一幀的交會點,對應兩個向量的歐氏距離。DTW算法可以歸結(jié)為尋找一條通過此網(wǎng)格中若干交叉點的路徑,使得該路徑上節(jié)點的距離和(即失真距離)為最小[4]。對于端點松弛的情況,路徑搜索原理相同,只是增加了搜索路徑。

2 硬件系統(tǒng)
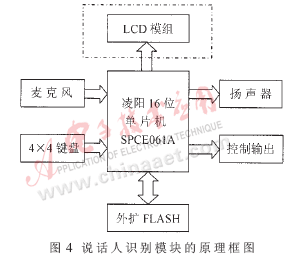
語音電子門鎖系統(tǒng)的核心是說話人識別模塊。包括按鍵輸入、語音信號采集、語音信號處理、FLASH存儲擴展、揚聲器輸出、控制輸出以及LCD模組等。說話人識別模塊的原理框圖如圖4所示。其核心為語音信號處理,本系統(tǒng)選用特別適用于數(shù)字語音識別領(lǐng)域的凌陽16位單片機SPCE061A,并通過SPCE061A實現(xiàn)對其他各組成部分的編程控制。
SPCE061A是凌陽公司開發(fā)的一種性價比非常高的16位單片機。在2.6V~3.6V工作電壓范圍內(nèi),工作頻率范圍為0.32MHz~49.152MHz,較高的處理速度使其能夠非常容易、快速地處理復雜的數(shù)字信號;中斷系統(tǒng)支持10個中斷向量以及14個可來自系統(tǒng)時鐘、定時器/計數(shù)器、時間基準發(fā)生器、外部中斷、鍵喚醒、通用異步串行通信及軟中斷的中斷源,非常適合實時應用領(lǐng)域;內(nèi)嵌2K字的SRAM和32K字的FLASH,具有32位可編程的多功能I/O端口;包含有7通道10位通用A/D轉(zhuǎn)換器和內(nèi)置麥克風放大器與自動增益控制AGC功能的單通道聲音A/D轉(zhuǎn)換器,以及具有音頻輸出功能的雙通道10位D/A轉(zhuǎn)換器;SPCE061A采用CMOS制造工藝,同時增加了軟件激發(fā)的弱振方式、空閑方式和掉電方式,系統(tǒng)處于備用狀態(tài)下(時鐘處于停止狀態(tài)),耗電僅為2μA 3.6V,極大地降低了其功耗;另外,μ’nSPTM的指令系統(tǒng)還提供具有較高運算速度的16位×16位的乘法運算指令和內(nèi)積運算指令,為其應用增添了DSP功能,在復雜的數(shù)字信號處理方面既非常便利,又比專用的DSP芯片便宜得多。
說話人識別模塊各組成部分完成的功能如下:
(1)按鍵輸入部分:共有數(shù)字鍵、訓練鍵、刪除鍵、確認鍵和取消鍵等16個按鍵,用于密碼輸入和工作模式選擇。采用4×4矩陣式鍵盤輸入,只使用具有鍵喚醒功能IOA的低8位,可以合理利用硬件資源,且編程靈活。
(2)語音信號采集部分:通過SPCE061A內(nèi)置麥克風放大器與自動增益控制AGC功能的單通道聲音A/D轉(zhuǎn)換器完成8kHz語音信號采集。
(3)FLASH存儲擴展部分:用于存儲說話人的個性特征參數(shù)參考模板。
(4)揚聲器輸出部分:通過SPCE061A具有音頻輸出功能的雙通道10位D/A轉(zhuǎn)換器完成用戶訓練、識別等各種操作的語音提示。
(5)控制輸出部分:通過SPCE061A的可編程I/O口控制門鎖控制電機。
(6)LCD模組部分:用以顯示系統(tǒng)的工作狀態(tài),該部分根據(jù)成本和實際需要可選。
(7)SPCE061A:說話人的語音信號處理以及各部分的編程控制均由SPCE061A完成。
說話人識別模塊有三種工作模式:訓練模式、認證模式和密碼模式,這三種模式都可通過工作模式按鍵選擇。
(1)訓練模式,說話人的聲音通過麥克風進入語音信號采集前端電路。第一次語音輸入時,由16位單片機SPCE061A對采集的語音信號進行處理,提取說話人的個性特征參數(shù),并存儲到外擴的FLASH內(nèi),形成說話人特征參數(shù)模板。可以進行三次訓練,第二語音輸入時,提取的個性特征參數(shù)與由第一次語音輸入形成的特征參數(shù)模板進行匹配,在匹配距離小于模板更新閾值時,將說話人特征參數(shù)模板更新為兩次特征參數(shù)的平均值。第三次語音輸入時,提取的個性特征參數(shù)與由第一、二次語音輸入形成的特征參數(shù)模板進行匹配,在匹配距離小于模板更新閾值時,將說話人特征參數(shù)模板更新為三次特征參數(shù)的平均值,形成最后的該說話人的特征參數(shù)模板。
(2)認證模式,同樣通過麥克風錄入說話人的聲音,再由SPCE061A對采集的語音信號進行處理,將提取的說話人特征參數(shù)與存儲在外擴FLASH內(nèi)的特征參數(shù)模板進行匹配,匹配距離小于認證閾值時,通過認證;然后再判斷匹配距離是否小于認證模式下的模板更新閾值,決定是否對模板進行更新。
(3)密碼工作模式,在說話人感冒或其他使其聲音發(fā)生暫時改變的情況下,可以采用長密碼方式進行認證,以免因為非常原因被拒之門外。
另外,每個用戶都有一個短密碼(用戶可自行修改),無論在訓練模式還是認證模式都要輸入此密碼,以形成或找到與該用戶相對應的特征參數(shù)模板。系統(tǒng)還設置一個具有長密碼的超級管理員用戶,可以通過鍵盤對用戶模板進行添加或刪除。
3 實驗結(jié)果
對于說話人確認系統(tǒng),表征其性能的最重要的兩個參量是拒識率和誤識率。前者是拒絕真實的說話人而造成的錯誤,后者是接受假冒者而造成的錯誤,二者與匹配閾值的設定相關(guān)。匹配閾值的設定與語音鎖系統(tǒng)的應用場合、功能側(cè)重有關(guān),對于家庭、賓館等門鎖用戶,要求誤識率盡可能低,甚至為零;若用于公司員工考勤等同類功能,就不能有太高的拒識率。表1是對以下每種情況各進行100次實時匹配的結(jié)果,其中設定的閾值適合門鎖用戶。

由以上實驗結(jié)果可知,對于同一個人相同發(fā)音的拒識率為8%;對于同一個人相似發(fā)音情況,因為系統(tǒng)是對說話的人進行判別,對于這種情況,無論拒絕或接受都是合理的;對于同一個人不同發(fā)音和不同人發(fā)音的情況,誤識率為零。使用錄音機錄音進行多次實驗,通過認證的次數(shù)為零。對于門鎖用戶,這個結(jié)果是十分理想的。若用于考勤等同類功能,可通過修改匹配閾值實現(xiàn)。
聲紋識別與其他生物識別技術(shù)相比,除具有不會遺失和忘記、不需記憶、使用方便等優(yōu)點外,還具有以下特性:用戶接受程度高,由于不涉及隱私問題,用戶無任何心理障礙;聲音輸入設備造價低廉,而其他生物識別技術(shù)的輸入設備通常造價昂貴。與利用虹膜、指紋和人臉等技術(shù)的門鎖相比,基于SPCE061A構(gòu)建的語音電子門鎖系統(tǒng)具有成本低、使用方便、保密性好等優(yōu)點。經(jīng)大量實驗測試表明,該系統(tǒng)性能穩(wěn)定、識別效果好。下一步將進行小批量的試用,以發(fā)現(xiàn)問題并加以完善。但是,在環(huán)境噪聲或干擾信號高于語音信號時,該系統(tǒng)將無法進行正確的語音識別,在背景噪聲處理及其工程實現(xiàn)上還需進一步改進。
參考文獻
1 http://www.unsp.com.cn
2 孫冬梅,裘正定.生物特征識別技術(shù)綜述.電子學報,2001;(12A)
3 S. Tsekeridou, C. Kotropoulos, A. Xafopoulos, I. Pitas.Com-parative study of speaker verification techniques based on vector quantization, sphericity models and dynamic time war-ping. in Proc. of European Conf. on Circuit Theory and De-sign, Helsinki, Finland, 2001
4 楊行峻,遲惠生.語音信號數(shù)字處理.北京:電子工業(yè)出版社,1995