
??? 摘 要: 在簡(jiǎn)單介紹算術(shù)編碼" title="算術(shù)編碼">算術(shù)編碼和自適應(yīng)算術(shù)編碼的基礎(chǔ)上,介紹了利用FPGA器件并通過(guò)VHDL語(yǔ)言描述實(shí)現(xiàn)自適應(yīng)算術(shù)編碼的過(guò)程。整個(gè)編碼系統(tǒng)在ALTERA公司的MAX+plusⅡ軟件上進(jìn)行了編譯仿真,測(cè)試結(jié)果表明:編碼器各個(gè)模塊的設(shè)計(jì)在速度和資源利用兩方面均達(dá)到了較優(yōu)的狀態(tài),可以滿足實(shí)時(shí)編碼的要求。
?? ?關(guān)鍵詞: 算術(shù)編碼? 自適應(yīng)? FPGA? VHDL? 仿真
?
??? 算術(shù)編碼是一種無(wú)失真的編碼方法,能有效地壓縮信源冗余度,屬于熵編碼的一種。算術(shù)編碼的一個(gè)重要特點(diǎn)就是可以按分?jǐn)?shù)比特逼近信源熵,突破了Haffman編碼每個(gè)符號(hào)只能按整數(shù)個(gè)比特逼近信源熵的限制。對(duì)信源進(jìn)行算術(shù)編碼,往往需要兩個(gè)過(guò)程,第一個(gè)" title="第一個(gè)">第一個(gè)過(guò)程是建立信源概率表,第二個(gè)過(guò)程是對(duì)信源發(fā)出的符號(hào)序列進(jìn)行掃描編碼。而自適應(yīng)算術(shù)編碼在對(duì)符號(hào)序列進(jìn)行掃描的過(guò)程中,可一次完成上述兩個(gè)過(guò)程,即根據(jù)恰當(dāng)?shù)母怕使烙?jì)模型和當(dāng)前符號(hào)序列中各符號(hào)出現(xiàn)的頻率,自適應(yīng)地調(diào)整各符號(hào)的概率估計(jì)值,同時(shí)完成編碼。盡管從編碼效率上看不如已知概率表的情況,但正是由于自適應(yīng)算術(shù)編碼具有實(shí)時(shí)性好、靈活性高、適應(yīng)性強(qiáng)等特點(diǎn),在圖像壓縮、視頻圖像編碼等領(lǐng)域都得到了廣泛的應(yīng)用。
??? 現(xiàn)場(chǎng)可編程門陣列(FPGA)是一種新興的可編程邏輯器件,具有更高的密度、更快的工作速度和更大的編程靈活性,被廣泛應(yīng)用于各種電子類產(chǎn)品中。而硬件描述語(yǔ)言(HDL)是一種快速的電路設(shè)計(jì)工具,其功能涵蓋了電路描述、電路合成、電路仿真等的三大電路設(shè)計(jì)工作。VHDL是HDL的一種,因其簡(jiǎn)單易懂而被廣泛使用。本文采用VHDL編程實(shí)現(xiàn)了自適應(yīng)算術(shù)編碼,為算術(shù)編碼器的硬件實(shí)現(xiàn)提供了借鑒。
1 算術(shù)編碼的基本原理[1]
??? 實(shí)現(xiàn)算術(shù)編碼首先需要知道信源發(fā)出每個(gè)符號(hào)的概率大小,然后再掃描符號(hào)序列,依次分割相應(yīng)的區(qū)間,最終得到符號(hào)序列所對(duì)應(yīng)的碼字。整個(gè)編碼需要兩個(gè)過(guò)程,即概率模型建立過(guò)程和掃描編碼過(guò)程。
??? 算術(shù)編碼的基本原理是:根據(jù)信源可能發(fā)出的不同符號(hào)序列的概率,把[0,1]區(qū)間劃分為互不重疊的子區(qū)間,子區(qū)間的寬度恰好是各符號(hào)序列的概率。這樣,信源發(fā)出的不同符號(hào)序列將與各子區(qū)間一一對(duì)應(yīng),因此每個(gè)子區(qū)間內(nèi)的任意一個(gè)實(shí)數(shù)都可以用來(lái)表示對(duì)應(yīng)的符號(hào)序列,這個(gè)數(shù)就是該符號(hào)序列所對(duì)應(yīng)的碼字。顯然,一串符號(hào)序列發(fā)生的概率越大,對(duì)應(yīng)的子區(qū)間就越寬,要表達(dá)它所用的比特?cái)?shù)就越少,因而相應(yīng)的碼字就越短。
??? 圖1給出一個(gè)實(shí)現(xiàn)算術(shù)編碼的示例。要編碼的是一個(gè)來(lái)自四符號(hào)信源{A, B, C, D}的由五個(gè)符號(hào)組成的符號(hào)序列:ABBCD。假設(shè)已知各信源符號(hào)的概率分別為:P(A)=0.2,P(B)=0.4,P(C)=0.2,P(D)=0.2。編碼時(shí),首先根據(jù)各個(gè)信源符號(hào)的概率將區(qū)間[0,1]分成四個(gè)子區(qū)間。符號(hào)A對(duì)應(yīng)[0,0.2],符號(hào)B對(duì)應(yīng)[0.2,0.6],符號(hào)C對(duì)應(yīng)[0.6,0.8],符號(hào)D對(duì)應(yīng)[0.8,1.0]。符號(hào)序列中第一個(gè)符號(hào)是A,其對(duì)應(yīng)的區(qū)間為[0,0.2],接下來(lái)將這個(gè)區(qū)間擴(kuò)展為整個(gè)高度,再根據(jù)各個(gè)信源符號(hào)的概率將這個(gè)新區(qū)間分成四段;第二個(gè)符號(hào)是B,它對(duì)應(yīng)新的子區(qū)間的第二個(gè)子區(qū)間,即對(duì)應(yīng)區(qū)間[0.04,0.12];再將該區(qū)間擴(kuò)展為整個(gè)高度,再根據(jù)各個(gè)信源符號(hào)的概率將這個(gè)新區(qū)間分成四段。繼續(xù)這個(gè)過(guò)程直到最后一個(gè)符號(hào)得到一個(gè)區(qū)間[0.08032,0.0816],這樣該區(qū)間內(nèi)的任何一個(gè)實(shí)數(shù)就可以表示整個(gè)符號(hào)序列,如0.081。
?

2 自適應(yīng)算術(shù)編碼的基本原理
??? 自適應(yīng)算術(shù)編碼在一次掃描中可完成兩個(gè)過(guò)程,即概率模型建立過(guò)程和掃描編碼過(guò)程。
??? 自適應(yīng)算術(shù)編碼在掃描符號(hào)序列前并不知道各符號(hào)的統(tǒng)計(jì)概率,這時(shí)假定每個(gè)符號(hào)的概率相等,并平均分配區(qū)間[0,1]。然后在掃描符號(hào)序列的過(guò)程中不斷調(diào)整各個(gè)符號(hào)的概率。同樣假定要編碼的是一個(gè)來(lái)自四符號(hào)信源{A, B, C, D}的由五個(gè)符號(hào)組成的符號(hào)序列:ABBCD。編碼開始前首先將區(qū)間[0,1]等分為四個(gè)子區(qū)間,分別對(duì)應(yīng)A,B,C,D四個(gè)符號(hào)。掃描符號(hào)序列,第一個(gè)符號(hào)是A,對(duì)應(yīng)區(qū)間為[0,0.25],然后改變各個(gè)符號(hào)的統(tǒng)計(jì)概率,符號(hào)A的概率為2/5,符號(hào)B的概率為1/5,符號(hào)C的概率為1/5,符號(hào)D的概率為1/5,再將區(qū)間[0,0.25]等分為五份,A占兩份,其余各占一份。接下來(lái)對(duì)第二個(gè)符號(hào)B進(jìn)行編碼,對(duì)應(yīng)的區(qū)間為[0.1,0.15],再重復(fù)前面的" title="面的">面的概率調(diào)整和區(qū)間劃分過(guò)程。具體的概率調(diào)整見表1。
?
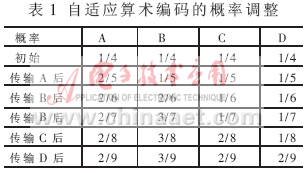
??? 隨著符號(hào)序列中符號(hào)個(gè)數(shù)的不斷增多,由自適應(yīng)算術(shù)編碼器估計(jì)得到的各符號(hào)的概率將趨于各符號(hào)的真實(shí)概率。
3 自適應(yīng)算術(shù)編碼的FPGA實(shí)現(xiàn)[2]
3.1 總體設(shè)計(jì)
??? 在利用FPGA實(shí)現(xiàn)自適應(yīng)算術(shù)編碼的過(guò)程中,首先遇到的問(wèn)題就是將浮點(diǎn)運(yùn)算轉(zhuǎn)化為定點(diǎn)運(yùn)算,即將[0,1]區(qū)間的一個(gè)小數(shù)映射為一個(gè)便于硬件實(shí)現(xiàn)的定點(diǎn)數(shù)。考慮到硬件實(shí)現(xiàn)的簡(jiǎn)便性,本文中將[0,1]之間的浮點(diǎn)數(shù)與[0,256]之間的定點(diǎn)數(shù)對(duì)應(yīng)。相應(yīng)的對(duì)應(yīng)關(guān)系如表2所示。
?

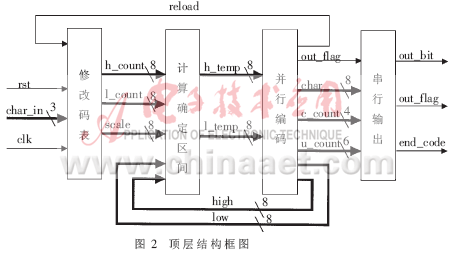
??? 編碼器在實(shí)現(xiàn)編碼的整個(gè)過(guò)程中按照耦合弱、聚合強(qiáng)的原則分為四個(gè)模塊:修改碼表、計(jì)算確定區(qū)間、并行編碼" title="并行編碼">并行編碼、串行輸出。四個(gè)模塊相對(duì)獨(dú)立,通過(guò)輸入、輸出信號(hào)使其構(gòu)成一個(gè)整體。系統(tǒng)的頂層結(jié)構(gòu)如圖2所示。
?
3.2? 碼表的設(shè)計(jì)及修改
??? 自適應(yīng)算術(shù)編碼器可以在許多場(chǎng)合中得到應(yīng)用。本文實(shí)現(xiàn)的自適應(yīng)算術(shù)編碼器應(yīng)用在采用6符號(hào)對(duì)小波變換系數(shù)進(jìn)行零樹編碼的小波域視頻編碼中[3],因此設(shè)計(jì)的碼表中含有六個(gè)符號(hào)。這樣根據(jù)自適應(yīng)算術(shù)編碼的基本原理,將區(qū)間分成六個(gè)子區(qū)間,整個(gè)區(qū)間含有七個(gè)分割點(diǎn)。所以碼表可以用七個(gè)8位寄存器表示。初始時(shí)設(shè)定為等概率,這時(shí)七個(gè)寄存器可以順序地存儲(chǔ)0到6這七個(gè)數(shù),即每個(gè)子區(qū)間的數(shù)值為1。隨著符號(hào)不斷地輸入,自適應(yīng)地修改碼表,并且在修改碼表的過(guò)程中時(shí)刻要保持寄存器中的數(shù)值是遞增的。
??? 修改碼表時(shí),首先判斷輸入符號(hào),確定其所在區(qū)間,同時(shí)為后續(xù)模塊輸出該子區(qū)間的兩個(gè)端點(diǎn)值l_count和h_count以及碼表的最后一個(gè)端點(diǎn)值scale,然后進(jìn)行碼表的修改:將當(dāng)前符號(hào)所在區(qū)間之后的所有端點(diǎn)值都加1,即當(dāng)前區(qū)間及后面所有子區(qū)間的h_count=h_count+1,這樣即完成了碼表的修改。在數(shù)值不斷累加過(guò)程中,寄存器中存儲(chǔ)的值將不斷增大。當(dāng)碼表中最后一個(gè)寄存器中的數(shù)值為255時(shí),需要對(duì)每一個(gè)寄存器中的值都取半,并同時(shí)對(duì)相鄰的兩個(gè)寄存器中的值進(jìn)行比較,時(shí)刻保持?jǐn)?shù)值是遞增的。這樣,處理前后的概率十分接近,對(duì)壓縮比影響不大。
??? 修改碼表模塊在輸出h_count、l_count和scale之后,后面的計(jì)算子區(qū)間的模塊即可進(jìn)行計(jì)算;而修改碼表模塊在輸出h_count、l_count和scale之后,亦可進(jìn)行碼表的修改。因此,這兩個(gè)操作可以采用并行處理的方法實(shí)現(xiàn),極大地節(jié)省了所用的時(shí)鐘周期,相應(yīng)地提高了速度,達(dá)到了優(yōu)化的目的。表3給出了輸入符號(hào)為3(對(duì)應(yīng)于寄存器2與寄存器3之間的區(qū)間)時(shí)碼表的修改過(guò)程。
?

?
3.3 區(qū)間計(jì)算及確定
??? 初始時(shí)符號(hào)所在的總區(qū)間為high=0xff,low=0(high和low分別表示已編碼的符號(hào)序列所在子區(qū)間的上下界)。隨著符號(hào)的不斷輸入,high和low的值也不斷地減小,用以表示輸入符號(hào)序列所對(duì)應(yīng)的子區(qū)間。通過(guò)如下的公式可確定輸入符號(hào)的區(qū)間:
??? 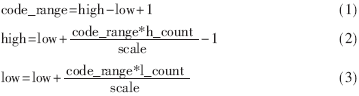
??? 計(jì)算時(shí),最耗資源的是乘法器和除法器。本方案中乘法器采用參數(shù)化模塊lpm中的lpm_mult生成,而除法器則自行編寫。雖然占用的時(shí)鐘周期較多,但與使用lpm相比,這樣做可以大大地提高工作頻率,從總體上提高性能。
3.4 并行編碼
??? 在區(qū)間計(jì)算過(guò)程中,high和low總是有限值,不可能無(wú)限制地劃分下去。為了能夠?qū)崿F(xiàn)連續(xù)的編碼,通過(guò)對(duì)high和low的處理,可以實(shí)現(xiàn)利用有限長(zhǎng)的寄存器表示無(wú)限精度的區(qū)間,即在不斷修改high和low的過(guò)程中輸出high和low中相同的高端位,形成輸出碼流。詳細(xì)過(guò)程如下:
??? 在區(qū)間確定之后,將low和high按位比較,若首位" title="首位">首位相同,則輸出首位二進(jìn)制碼,產(chǎn)生輸出碼流,同時(shí)把low和high左移,low末位補(bǔ)0,high末位補(bǔ)1。循環(huán)比較輸出,直到首位不同為止。如:
??? high?????=??? 00110110
??? low????? =??? 00100111
??? 輸出碼流為001,而high和low的結(jié)果為:
??? high???? =??? 10110111
??? low????? =??? 00111000
??? 通過(guò)這種連續(xù)地處理便可生成符號(hào)序列的自適應(yīng)算術(shù)編碼結(jié)果。但隨著待編碼符號(hào)序列的不斷輸入,可能會(huì)出現(xiàn)high和low十分接近,并且high和low的首位沒有相同位的情況,如:
??? high???? =??? 10000000
??? low????? =??? 01111111??
??? 稱這種現(xiàn)象為產(chǎn)生了下溢。產(chǎn)生下溢后,后面的編碼都失去了意義,此時(shí)需要特殊處理。
??? 對(duì)于下溢的處理方法為:保留首位,同時(shí)刪除緊接在首位后的high中連續(xù)的0和low中連續(xù)的1,并且保證對(duì)high和low刪除的位數(shù)相同,若連續(xù)0和連續(xù)1的位數(shù)不同,則取其較小者;然后把high和low左移相同的位數(shù),同時(shí)high的低位補(bǔ)1,low的低位補(bǔ)0。表4給出了下溢處理前后high和low值。
?

??? 經(jīng)過(guò)處理后,擴(kuò)大了區(qū)間,使得后面的編碼可以順利地進(jìn)行。
??? 在考慮了下溢的編碼輸出中,下溢作為輸出碼流的一部分,使得解碼時(shí)能對(duì)下溢進(jìn)行同樣的處理,達(dá)到編解碼的一致。但是下溢產(chǎn)生后并不馬上輸出,只記下下溢的個(gè)數(shù),下溢則是在下一個(gè)符號(hào)編碼時(shí)進(jìn)行輸出的。在下一個(gè)符號(hào)編碼時(shí),如果high和low比較后高端有相同位則輸出下溢,即在第一個(gè)輸出位后緊接著插入首位的反,插入首位反的個(gè)數(shù)為前面產(chǎn)生下溢的個(gè)數(shù),然后輸出相同的次高位及以后相同的各位。這樣處理既保留了下溢的信息又使得輸出碼流不偏離編碼符號(hào)所在的子區(qū)間,使得解碼時(shí)很容易處理。但是如果high和low比較后沒有相同位輸出則不輸出下溢,而是把兩次產(chǎn)生的下溢的個(gè)數(shù)進(jìn)行累加,再輸入下一個(gè)符號(hào),直到high和low有相同首位才輸出下溢。
??? 例如:在一個(gè)符號(hào)編碼計(jì)算后得到的high=11010010和low=11001101,而前一個(gè)符號(hào)編碼產(chǎn)生的下溢為1個(gè),比較后輸出為1010,同時(shí)記錄下產(chǎn)生的下溢2個(gè),如表5所示。
?

3.5 串行輸出
??? 并行編碼后產(chǎn)生的碼流存儲(chǔ)在并行數(shù)據(jù)中,但在大多的情況下只有兩、三個(gè)輸出,甚至沒有輸出,若采用并行輸出,就會(huì)產(chǎn)生極大的浪費(fèi)。為了充分利用資源,在并行編碼之后進(jìn)行并/串轉(zhuǎn)換,使其一位一位地輸出,并且這個(gè)輸出過(guò)程與下一個(gè)符號(hào)編碼的過(guò)程并行完成,因此并不占用多余的時(shí)鐘周期。
??? 在編碼過(guò)程中,當(dāng)一個(gè)符號(hào)編碼結(jié)束后,觸發(fā)reload信號(hào),通知此次編碼結(jié)束,進(jìn)行下一次編碼,讀取輸入的符號(hào)。同時(shí)需判斷輸入是否合法,如果是合法的輸入,就進(jìn)行編碼;否則停止編碼,處于等待狀態(tài),直到復(fù)位信號(hào)rst置1,重新初始化、編碼。
4 仿真結(jié)果
??? 本文算法采用VHDL硬件描述語(yǔ)言實(shí)現(xiàn),并在ALTERA公司的MAX+plusⅡ軟件上編譯仿真。設(shè)計(jì)采用全局同步時(shí)鐘,避免了毛刺的產(chǎn)生,保證了信號(hào)的穩(wěn)定性。編碼的仿真結(jié)果如圖3所示。
?
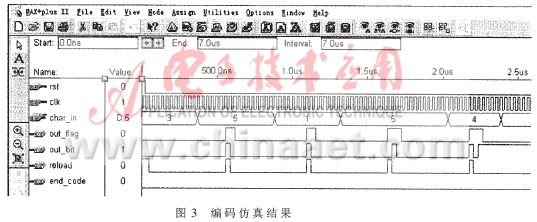
??? 其中,rst、clk、c為輸入信號(hào),rst為模塊中各寄存器的初始化信號(hào),clk為時(shí)鐘同步信號(hào),而c則為輸入的編碼信號(hào);out_flag、out_bit、reload、end_code為輸出信號(hào),out_flag和out_bit分別為輸出標(biāo)志位和輸出位(若out_falg=1,則此時(shí)out_bit為有效輸出;否則out_bit輸出無(wú)效),reload為一個(gè)符號(hào)編碼結(jié)束)下一個(gè)符號(hào)輸入的標(biāo)志位,end_code為編碼結(jié)束的標(biāo)志(若end_code=0,則繼續(xù)編碼,否則編碼結(jié)束)。
??? 在進(jìn)行性能仿真時(shí)[4],采用的器件是FLEX1K系列的EP1K30TC144-1器件,其最大工作頻率為40MHz,消耗1533個(gè)LC,平均編碼時(shí)間為20個(gè)時(shí)鐘周期。一個(gè)符號(hào)的編碼時(shí)間不到500ns,對(duì)于QCIF格式的圖像完全可以滿足每秒鐘實(shí)時(shí)編碼30幀圖像的要求。
??? 自適應(yīng)算術(shù)編碼是一種效率很高的無(wú)失真編碼,本文通過(guò)VHDL語(yǔ)言實(shí)現(xiàn)了自適應(yīng)的算術(shù)編碼,在編碼過(guò)程中,根據(jù)硬件結(jié)構(gòu)的特點(diǎn),充分利用其并行特性。通過(guò)并行執(zhí)行,實(shí)現(xiàn)了速度的優(yōu)化。由于滿足每秒鐘編碼30幀圖像的要求,因此可以應(yīng)用于視頻圖像的實(shí)時(shí)編碼中。
參考文獻(xiàn)
1 Mark Nelson. Arithmetic Coding +?Statistical Modeling = Data Compression.Dr.Dobb’s Journal,F(xiàn)ebruary 1991
2?Uwe Meyer-baese著,劉 凌,胡永生譯. 數(shù)字信號(hào)處理的FPGA實(shí)現(xiàn). 北京:清華大學(xué)出版社, 2003
3 Arturo San Emeterio Campos. http://www.arturocampos.com/ac_arithmetic.html, 1999
4 潘 松,黃繼業(yè).EDA技術(shù)實(shí)用教程.北京:科學(xué)出版社,2002