
??? 通過熟悉器件架構(gòu),選擇合適的硬件平臺(tái)和硅片特性,并借助配置恰當(dāng)且性能優(yōu)良的實(shí)現(xiàn)工具,設(shè)計(jì)人員就能獲得較高的設(shè)計(jì)性能。不過,在提高設(shè)計(jì)性能的眾多方法中最容易被忽視的也許就是為目標(biāo)器件編寫高效的HDL代碼。本文所討論的編程風(fēng)格與技巧可提高設(shè)計(jì)性能。?
使用復(fù)位對性能的影響?
??? 很少有哪種系統(tǒng)級(jí)的選擇能夠像復(fù)位選擇那樣對性能、面積和功率產(chǎn)生如此重要的影響。一些系統(tǒng)架構(gòu)師規(guī)定必須使用系統(tǒng)全局異步復(fù)位" title="異步復(fù)位">異步復(fù)位。采用賽靈思" title="賽靈思">賽靈思的FPGA架構(gòu),復(fù)位的使用和類型將對代碼性能產(chǎn)生重要影響。?
?
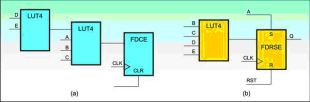
圖a:綜合工具" title="綜合工具">綜合工具選用2個(gè)LUT。圖b:更靈活的LUT接口。?
???
??? 在目前所有的賽靈思FPGA架構(gòu)中,查找表(LUT)單元就像邏輯、ROM/RAM或移位寄存器" title="移位寄存器">移位寄存器(SRL或移位寄存器LUT)那樣是可配置的。綜合工具可以根據(jù)RTL代碼推斷出采用某一種結(jié)構(gòu)。不過,為了將LUT用作移位寄存器,代碼中不能描述復(fù)位功能,因?yàn)?SPAN lang=EN-US>SRL本身沒有復(fù)位功能。這也意味著具有復(fù)位功能的移位寄存器代碼不能獲得最佳實(shí)現(xiàn)(移位寄存器之間需要多個(gè)觸發(fā)器和相關(guān)路徑),而沒有復(fù)位功能的代碼則可以獲得快速而緊湊的實(shí)現(xiàn)結(jié)果(使用SRL)。?
??? 這兩種情況對面積和功率的影響更明顯一些,但對性能的影響不很明顯。一般而言,采用觸發(fā)器生成的移位寄存器不會(huì)成為設(shè)計(jì)中的關(guān)鍵路徑,因?yàn)榧拇嫫髦g的時(shí)序路徑通常沒有足夠的長度成為設(shè)計(jì)中最長的路徑。而資源(觸發(fā)器和布線)的額外消耗會(huì)對其它設(shè)計(jì)部分的布局和布線選擇產(chǎn)生負(fù)面影響,因而可能導(dǎo)致更長的布線路徑。?
專用乘法器" title="乘法器">乘法器和RAM模塊?
??? 乘法器通常用于DSP設(shè)計(jì)。但由于賽靈思的FPGA架構(gòu)中包含有乘法專用資源,因此在許多設(shè)計(jì)中都有乘法器的應(yīng)用。這些乘法器除了執(zhí)行乘法操作外,還提供其它功能。同樣地,實(shí)際上不管哪種應(yīng)用,每個(gè)FPGA設(shè)計(jì)都會(huì)用到大小不一的RAM。?
??? 賽靈思FPGA包含幾個(gè)RAM模塊,在設(shè)計(jì)中可以用作RAM、ROM、大型LUT甚至通用邏輯。使用乘法器和RAM資源可獲得更加緊湊、具有更高性能的設(shè)計(jì),不過復(fù)位選擇對性能既有正面的,也有負(fù)面的影響,具體取決于使用的復(fù)位類型。RAM和乘法器模塊只包含同步復(fù)位,因此如果這些功能的代碼用異步復(fù)位編寫,那么這些模塊中的寄存器就無法使用了。這對性能的影響是非常嚴(yán)重的。例如,Virtex-4器件的全管線式乘法器采用異步復(fù)位設(shè)計(jì)時(shí),頻率最高只能達(dá)到200MHz,而將代碼改成同步復(fù)位后,性能可提高兩倍以上,頻率可達(dá)500MHz。
?
?
??? 要從兩個(gè)方面看待與RAM有關(guān)的問題。與乘法器類似,Virtex-4塊RAM具有可選的輸出寄存器,使用它們可以減少RAM的時(shí)鐘到輸出時(shí)間,提高整體設(shè)計(jì)速度。但這些寄存器只提供同步復(fù)位,不提供異步復(fù)位,因此當(dāng)代碼中的寄存器采用異步復(fù)位描述時(shí)就無法使用這些寄存器。?
??? 第二個(gè)問題來自RAM被用作LUT或通用邏輯時(shí)。有時(shí)基于面積和性能方面的考慮,將配置為ROM或通用邏輯的多個(gè)LUT壓縮進(jìn)單個(gè)塊RAM是非常有益的。這可通過人工設(shè)定結(jié)構(gòu),或以自動(dòng)方式將部分邏輯設(shè)計(jì)映射到未用的RAM存儲(chǔ)區(qū)來實(shí)現(xiàn)。因?yàn)閴KRAM具有同步復(fù)位功能,因此當(dāng)使用同步復(fù)位(或沒有復(fù)位)時(shí),無需改變已經(jīng)定義好的設(shè)計(jì)功能就可實(shí)現(xiàn)通用邏輯的映射。但當(dāng)采用異步復(fù)位描述時(shí),這就不可能實(shí)現(xiàn)。?
通用邏輯?
??? 異步復(fù)位對通用邏輯結(jié)構(gòu)也會(huì)產(chǎn)生影響。由于所有的賽靈思FPGA通用寄存器都具有將復(fù)位/置位編程為異步或同步的能力,因此設(shè)計(jì)人員可能認(rèn)為使用異步復(fù)位沒什么不妥。但這種假設(shè)通常是錯(cuò)誤的。如果沒有使用異步復(fù)位,那么置位/復(fù)位邏輯就可以被置為同步邏輯。這樣一來,就可釋放額外的資源用于邏輯優(yōu)化。?
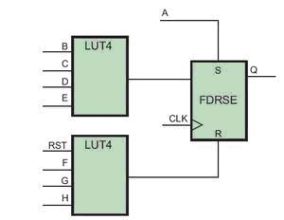
?????????? 圖d:選用同步復(fù)位。?
??? 為了更好地理解異步復(fù)位如何影響優(yōu)化結(jié)果,我們來看看以下一些不夠理想的代碼例子:?
VHDL例子#1?
process?(CLK,?RST)?
begin?
if?(RST?=?'1')?then?
Q?<=?'0';?
elsif?(CLK'event?and?CLK?=?'1')?then?
Q?<=?A?or?(B?and?C?and?D?and?E);?
end?if;?
end?process;?
Verilog例子#1?
always?@(posedge?CLK,?posedge?RST)?
if?(RESET)?
Q?<=?1'b0;?
else?
Q?<=?A?|?(B?&?C?&?D?&?E);?
??? 為實(shí)現(xiàn)這些代碼,綜合工具只能為數(shù)據(jù)路徑選擇兩個(gè)LUT,因?yàn)榭偣灿?SPAN lang=EN-US>5個(gè)信號(hào)與實(shí)現(xiàn)上述邏輯功能相關(guān)。上述代碼的一種可能性的實(shí)現(xiàn)方案如圖a所示。?
??? 不過,如果采用同樣的代碼重新編寫同步復(fù)位,則能進(jìn)一步減少面積、提高性能,獲得如下修正過的代碼。?
VHDL?例子#2?
process?(CLK)?
begin?
if?(CLK'event?and?CLK?=?'1')?then?
if?(RST?=?'1')?then?
Q?<=?'0';?
else?
Q?<=?A?or?(B?and?C?and?D?and?E);?
end?if;?
end?if;?
end?process;?
Verilog?例子#2?
always?@(posedge?CLK)?
if?(RESET)?
Q?<=?1'b0;?
else?
Q?<=?A?|?(B&C&D&E);?
??? 如今的綜合工具在實(shí)現(xiàn)這種功能時(shí)具有了更大的靈活性。上述代碼的一種可能性的實(shí)現(xiàn)方案如圖b所示。?
??? 在該實(shí)現(xiàn)中,綜合工具能夠確定無論何時(shí)只要A是有效高電平,則Q總是邏輯1。其中寄存器與復(fù)位/置位一起被配置為同步操作,因此可以將置位功能自由地用作同步數(shù)據(jù)路徑的一部分。這樣可以減少實(shí)現(xiàn)該功能所必需的邏輯數(shù)量,并能減少來自前面例子的D和E信號(hào)的數(shù)據(jù)路徑延時(shí)。如果代碼能以更利于實(shí)現(xiàn)的方式編寫,那么邏輯部分還可以轉(zhuǎn)移到復(fù)位側(cè)。?
??? 以下是對這些例子的補(bǔ)充:?
VHDL例子#3?
process?(CLK,?RST)?
begin?
if?(RST?=?'1')?then?
Q?<=?'0';?
elsif?(CLK'event?and?CLK?=?'1')?then?
Q?<=?(F?or?G?or?H)?and?(A?or?(B?and?C?
and?D?and?E));?
end?if;?
end?process;?
Verilog?例子#3?
always?@(posedge?CLK,?posedge?RST)?
if?(RESET)?
Q?<=?1'b0;?
else?
Q?<=?(F|G|H)?&?(A?|?(B&C&D&E));?
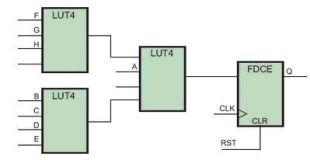
??? 現(xiàn)在總共有8個(gè)信號(hào)與邏輯功能相關(guān),因此實(shí)現(xiàn)該功能至少需要3個(gè)LUT。以上代碼的一種可能性的實(shí)現(xiàn)方案如圖c所示。?
??? 如果采用同樣的代碼編寫同步復(fù)位,則有:?
VHDL例子#4?
process?(CLK)?
begin?
if?(CLK'event?and?CLK?=?'1')?then?
if?(RST?=?'1')?then?
Q?<=?'0';?
else?
Q?<=?(F?or?G?or?H)?and?(A?or?(B?and?C?
and?D?and?E));?
end?if;?
end?if;?
end?process;?
Verilog?例子#4?
always?@(posedge?CLK)?
if?(RESET)?
Q?<=?1'b0;?
else?
Q?<=?(F|G|H)?&?(A?|?(B&C&D&E));?
??? 以上代碼的一種可能性的實(shí)現(xiàn)方案如圖d所示。其結(jié)果不僅是能夠使用更少的LUT實(shí)現(xiàn)同樣的邏輯功能,而且能夠?qū)崿F(xiàn)更快的設(shè)計(jì),因?yàn)闇p少了實(shí)際創(chuàng)建該功能的每個(gè)信號(hào)的邏輯級(jí)數(shù)。?
??? 雖然這些例子非常簡單,但它們能夠很好地闡明我們的觀點(diǎn),即異步復(fù)位如何將所有的同步數(shù)據(jù)信號(hào)加載到寄存器的輸入端,從而導(dǎo)致可能更多的邏輯級(jí)數(shù)以及不夠完善的實(shí)現(xiàn)結(jié)果。一般而言,扇入邏輯功能的信號(hào)越多,同步復(fù)位/置位在減少邏輯資源或提高設(shè)計(jì)性能方面越有效。?
用加法器鏈代替加法器樹??
??? 許多信號(hào)處理算法都是對輸入的采樣數(shù)據(jù)流進(jìn)行某種算術(shù)運(yùn)算,然后將這種算術(shù)運(yùn)算的所有輸出進(jìn)行累加。加法樹結(jié)構(gòu)一般是用來實(shí)現(xiàn)并行結(jié)構(gòu)(如FPGA)中的這種累加運(yùn)算。??
????加法器樹概念的一個(gè)難點(diǎn)在于其數(shù)量會(huì)經(jīng)常變化。加法器的數(shù)量取決于加法器樹的輸入信號(hào)數(shù)量。加法器樹中的輸入越多,需要的加法器數(shù)量也越多,需要的邏輯資源和功耗也就越多。樹越大意味著樹的最后一級(jí)加法器也越大,因而會(huì)進(jìn)一步降低系統(tǒng)性能。?
??? 為了減少功耗,保持較高的系統(tǒng)性能,加法器樹應(yīng)作為專門的硅資源加以實(shí)現(xiàn)。但在硅片中放置大量固定尺寸的加法器樹元件并不很有效,因?yàn)楫?dāng)加法超過一定數(shù)量時(shí)必須使用邏輯資源,甚至采用更大的FPGA,因而會(huì)增加器件的成本。?
??? 采用DSP48系列專用硅片組的Virtex-4系列器件則采用不同的方法實(shí)現(xiàn)累加。它采用鏈狀加法器代替加法器樹進(jìn)行增量式累加運(yùn)算。這種方法有別于任何現(xiàn)有的FPGA,是提升器件性能、降低DSP算法所需功耗的關(guān)鍵,因?yàn)檫壿嬇c互連功能被完全集成進(jìn)專用硅片中。?
??? 采用管線形式的DSP48模塊頻率可達(dá)500MHz,而與加法器數(shù)量無關(guān)。如圖5所示,級(jí)聯(lián)端口以及48位分辨率的加法器/累加器完全能夠勝任目前的采樣值計(jì)算,并完成迄今為止所有計(jì)算采樣值的累加。?
??? 為了充分利用RTL中的Virtex-4加法器鏈結(jié)構(gòu),只需簡單地用加法器鏈描述替代加法器樹描述。這種將將直接型濾波器轉(zhuǎn)換成轉(zhuǎn)置型或脈動(dòng)型濾波器的過程在XtremeDSP設(shè)計(jì)用戶指南中有詳細(xì)介紹。?
??? 一旦轉(zhuǎn)換完成后,你會(huì)發(fā)現(xiàn)算法的運(yùn)行速度要比應(yīng)用所需的快得多。在這種情況下,可以使用合并或多信道技術(shù)進(jìn)一步減少器件使用率和功耗。這兩種技術(shù)都可以采用更小的器件實(shí)現(xiàn)設(shè)計(jì),或者使用空余資源增加設(shè)計(jì)功能。?
??? 多信道技術(shù)可以將非常快的運(yùn)算單元作用于多個(gè)采樣速率很慢的輸入流(信道)上。這種技術(shù)對硅片效率的提高幅度幾乎等于信道數(shù)量。多信道濾波器可以看作是時(shí)間復(fù)接的單信道濾波器。例如,在一個(gè)典型的多信道濾波環(huán)境中,對多個(gè)輸入信道中的每個(gè)信道都使用獨(dú)立的數(shù)字濾波器進(jìn)行濾波。為了充分發(fā)揮Virtex-4?DSP48模塊的性能優(yōu)勢,只需為單濾波器提供8倍的時(shí)鐘,設(shè)計(jì)人員即可使用一個(gè)單數(shù)字濾波器完成對所有8個(gè)輸入信道的濾波,而所需的FPGA資源數(shù)量幾乎可以減少8倍。?
提高塊RAM性能?
??? 在選用存儲(chǔ)器單元時(shí),影響性能的因素有:使用專用模塊還是分布式模塊;RAM;使用輸出管線寄存器;不使用異步復(fù)位。此外,還有兩個(gè)不大為人所知的因素,即HDL編程風(fēng)格和綜合工具設(shè)置,這些也會(huì)極大地影響存儲(chǔ)器性能。?
HDL編程風(fēng)格?
??? 當(dāng)選用雙端口模塊存儲(chǔ)器時(shí),很可能兩個(gè)端口同時(shí)訪問同一存儲(chǔ)器單元。當(dāng)兩個(gè)端口同時(shí)向相同存儲(chǔ)器單元寫入不同的值時(shí)就會(huì)產(chǎn)生沖突,此時(shí)存儲(chǔ)器單元的內(nèi)容是無法得到保證的。不過,當(dāng)一個(gè)端口在讀,同時(shí)另一個(gè)端口在寫相同地址時(shí)又會(huì)發(fā)生什么情況呢?這要取決于目標(biāo)器件。最新的Virtex和Spartan系列器件有三種可編程操作模式可以控制寫操作進(jìn)行時(shí)存儲(chǔ)器的輸出。有關(guān)這三種操作模式的詳細(xì)信息請參閱器件的用戶指南。?
圖5:鏈狀加法器能提供可預(yù)測的性能。
?
??? 需要注意的是,不同模式會(huì)影響存儲(chǔ)器的輸出行為,也會(huì)影響存儲(chǔ)器的性能。如同下面所舉的例子,編程風(fēng)格決定了存儲(chǔ)器工作在何種工作模式下:?
//先寫或透明模式(transparent?mode)?
always?@(posedge?clk)?begin?
if(we)?begin?
do?<=?data;?
mem[address]?<=?data;?
end?else?
do?<=?mem[address];?
end?
//先讀或?qū)懬白x模式?
always?@(posedge?clk)?begin?
if?(we)?
mem[address]?<=?data;?
do?<=?mem[address];?
end?
//不變模式?
always?@(posedge?clk)?
if?(we)?
mem[address]?<=?data;?
else?
do?<=?mem[address];?
end?
增加管線級(jí)數(shù)?
??? 另外一種提高性能的方法是重新構(gòu)建由多級(jí)邏輯組成的長數(shù)據(jù)路徑,將它們分解成多個(gè)時(shí)鐘周期進(jìn)行處理。這種方法允許使用更快的時(shí)鐘周期,并可提高數(shù)據(jù)吞吐量,其代價(jià)是時(shí)延和管線管理開銷邏輯。因?yàn)?SPAN lang=EN-US>FPGA中的寄存器非常多,因此額外的寄存器和開銷邏輯一般不成問題。?
??? 由于數(shù)據(jù)目前處于多周期路徑上,因此設(shè)計(jì)人員必須采用特殊方法才能解決額外的時(shí)延問題。下面的例子采用在32x32乘法器輸出端增加5級(jí)寄存器的編程風(fēng)格。綜合工具將把這些寄存器以管線形式關(guān)聯(lián)到Virtex-4?DSP48模塊中可用的寄存器,從而極大地提高了數(shù)據(jù)吞吐量。?
//?帶有4個(gè)DSP48模塊的32x32乘法器?
always?@(posedge?clk)?begin?
prod[0]?<=?a?*?b;?
for?(i=1;?i<=PIPE-1;?i=i+1)?
prod[i]?<=?prod[i-1];?
end?
代碼中的嵌套?
??? 代碼中盡量不要設(shè)置太多的嵌套,例如嵌套的if和case語句。若在某條if語句中有太多的if語句,則不利于實(shí)現(xiàn)綜合優(yōu)化。如果遵循以下指導(dǎo)原則,代碼的可讀性會(huì)更強(qiáng)。當(dāng)在HDL中描述“for-loops”語句時(shí),最好在數(shù)據(jù)路徑中放置至少一個(gè)寄存器,特別是有算術(shù)或其它邏輯多的操作時(shí)。在編譯時(shí),綜合工具會(huì)解開環(huán)路。如果沒有這些同步單元,它會(huì)級(jí)聯(lián)環(huán)路每次反復(fù)時(shí)創(chuàng)建的邏輯,從而導(dǎo)致組合路徑過長,降低設(shè)計(jì)性能。?
本文小結(jié)?
??? 綜合、布局和布線算法中的最新發(fā)展可使我們更直接地從特殊器件中獲得最佳性能。綜合工具可以選用復(fù)雜的算術(shù)和存儲(chǔ)器描述并映射到專門的硬件模塊上。它們也能執(zhí)行再定時(shí)、邏輯和寄存器復(fù)制等優(yōu)化操作。布局布線工具可以在時(shí)序約束的基礎(chǔ)上重建網(wǎng)表,執(zhí)行以時(shí)序?yàn)橹鲗?dǎo)的封裝和布局,從而減少布局布線擁塞。?
??? 不過,目前的工具在提高性能方面只能做到這么多。如果需要更高性能的設(shè)計(jì),最有效的方法莫過于更好地理解目標(biāo)器件、綜合工具,并采用本文提供的編碼指南。