
摘 要:語音編碼方案的選取對移動通信系統(tǒng)的通話質(zhì)量、信道容量等有重要影響。討論了TD-SCDMA系統(tǒng)中AMR語音編碼的自適應(yīng)機制,分析了AMR中代數(shù)碼本線性預(yù)測(ACELP)算法及實現(xiàn)過程。該方案可以在一塊TMS320C5510上實現(xiàn),通過在TD-SCDMA系統(tǒng)的硬件平臺上自環(huán)測試,結(jié)果是理想的。
0 引 言
在語音編碼領(lǐng)域中,隨著傳輸、處理、存儲等各種信息量的巨增,信息的壓縮處理已成為迫切的要求,基于新的網(wǎng)絡(luò)和新的要求,無論是從節(jié)省傳輸頻帶資源,還是保持線路通信的高效率等方面來看,研究采用各種可變速率語音編碼技術(shù)的系統(tǒng)都有重要意義。目前為了適應(yīng)此需要提出了AMR(adaptivemulti-rate)概念,即自適應(yīng)話音編碼器。基于帶寬的考慮可分為AMR- NB(AMRNarrowband)和AMR-WB(AMRwideband)。對于AMR-NB,語音通道帶寬限制為3.7 MHz,采樣頻率為8 kHz,而AMR-WB為7 MHz的帶寬,采樣頻率為16 kHz,但考慮語音的短時相關(guān)性,每幀長度均為20 ms。這2種編碼器根據(jù)帶寬的要求雖然選用了不同的速率,但有異曲同工
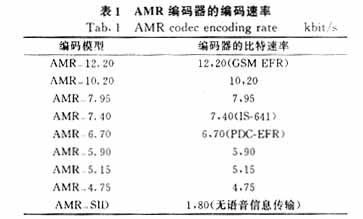
之處,以下著重介紹在TD-SCDMA中AMR-NB的實現(xiàn)。此編碼器運用了代數(shù)碼本線性預(yù)測(ACELP)混合編碼方式,也就是數(shù)字語音信號中既包括若干語音特征參數(shù)又包括部分波形編碼信息,再運用這些特征信息重新合成語音信號的過程。控制這些參數(shù)的提取數(shù)目,根據(jù)速率要求對信息進行取舍而得到了以下8種速率,混合組成如表1所示的自適應(yīng)語音編碼器。表1中模式AMR-12.20就提取出244比特的參數(shù)信息,而模式AMR-4.70卻只提取了95比特信息。根據(jù)這些比特所含的信息量可以將其分為3類比特class 0,1,2。在信道編碼時class0和1都將會使用循環(huán)冗余校驗碼進行差錯檢驗,對于class 2則根據(jù)上一幀進行恢復(fù)。
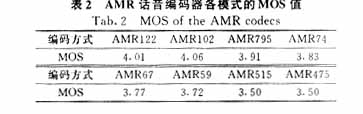
語音編碼或語音壓縮編碼研究的基本問題,就是在給定編碼速率的條件下,如何能得到盡量好的重建語音質(zhì)量。主觀評定方法符合人類聽話時對語音質(zhì)量的感覺得到了廣泛應(yīng)用。常用的方法有平均得分意見(mean opinion score,簡稱MOS)判定法,表2說明了AMR話音編碼器各模式的話音質(zhì)量。
1 AMR模式選擇的自適應(yīng)機制
自適應(yīng)的基本概念是以更加智能的方式解決信源和信道編碼的速率分配問題,使得無線資源的配置和利用更加靈活和高效。實際的語音編碼速率取決于信道的條件,它是信道質(zhì)量的函數(shù)。而這部分的工作是解碼器根據(jù)噪聲等測量參數(shù)協(xié)助基站來完成的,選擇模式,決定速率快慢。原則上在信道很差的時候采用速率比較低的編碼器,這樣就能分配給信道編碼更多的比特數(shù)來實現(xiàn)糾錯,實現(xiàn)更可靠的差錯控制,從而有效地抑制錯誤發(fā)生,提高話音質(zhì)量[1]。
在TD-SCDMA系統(tǒng)實現(xiàn)方面為了便于量化比較而采用了C/I(載干比)這一概念,取其滑動平均值,再將此值與一預(yù)先定義好的門限值進行比較,來決定速率的選擇。由于不同的特性,全速率信道和半速率信道就應(yīng)有不同的定義值。在全速率信道,當(dāng)C/I≥13時,MR122的MOS值可以達到4以上,可以提供很好的性能;9≤C/I<13時,MR122、MR102、MR795都是可以選擇的,速率越低,誤幀率越低;當(dāng)6≤C/I<9時,最好選擇MR74、 MR67、MR59;而當(dāng)C/I<6時就應(yīng)盡量選擇越低的速率,隨著信道質(zhì)量的下降,誤幀率都會增加,但相對選擇的速率低,就能提供相對較好的話音質(zhì)量。對于半速率信道,與上述類似,不再累述。下面進一步說明自適應(yīng)速率選擇的實現(xiàn)過程。圖1是完整的說明圖。自適應(yīng)要求有2類信息需要傳輸:在下行信道上,需要基站發(fā)送給移動臺1模式選擇測量命令,而在上行信道上,移動臺將信道測量信息傳送給基站。這種模式要求傳送信息準(zhǔn)確、可靠、及時,才能有效達到自適應(yīng)的目的。基站每幀發(fā)送1測量命令,得到返回信息,通過比較選擇,選擇1模式用于下一幀。這樣就可以實現(xiàn)速率間的轉(zhuǎn)換,達到自適應(yīng)的目的,在速率間的切換會有一定功率損耗,并且不同速率間的損 耗是不同的,這是在實現(xiàn)過程中應(yīng)該考慮的[2,3]。

2 AMR編碼器算法
AMR編碼器算法是基于代數(shù)碼本線性預(yù)測(ACELP)的混合編碼算法[4,5]。基本原理是原始語音按幀輸入,根據(jù)使合成語音與原始語音的加權(quán)均方誤差最小的準(zhǔn)則,從隨機碼本和固定碼本中挑選合適的碼矢以代替殘差信號,并將碼矢地址和增益及各濾波器的參數(shù)量化編碼后傳送到接收端;接收端恢復(fù)各濾波器時,采用與發(fā)送端相同的碼本,按照碼矢地址找到該碼矢乘上增益,激勵合成濾波器,得到合成語音。在編碼部分需要抽取下列典型參數(shù):線性預(yù)測濾波器系數(shù)(LP),自適應(yīng)碼本(ACB)和固定碼本(FCB)索引以及2種碼本的增益( 見圖2)。下面將分別從編碼和解碼 的角度闡述AMR編解碼方案。
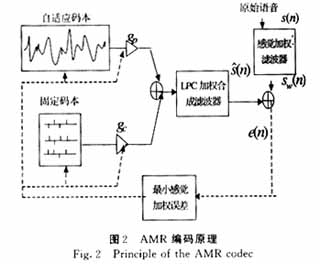
(1)線性預(yù)測計算。LPC濾波器表征語音信號發(fā)生模型中的聲道模型,圖2中
其中,A(z)為聲道傳輸函數(shù),ai隨語音幀的變化不斷改變(ai具有短時穩(wěn)定性)。因此,在每個語音幀中,需要提取LPC系數(shù)。按其預(yù)測值與實際值最小 化均方誤差原則,可得下式:
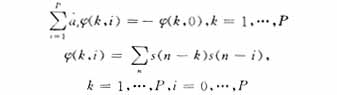
上述正則方程[6]采用Durbin算法進行線性預(yù)測便可得到參數(shù)ak。考慮到線譜頻率(LSF)誤差的相對獨立性及有序有界性質(zhì),與線性預(yù)測參數(shù)(LP)是一一對應(yīng)的,采用Chebyshev多項式估計方法是可以相互轉(zhuǎn)換的,因此在考慮傳輸時用LSF參數(shù)代替LP參數(shù),將其進行矢量量化,在解碼部分再對LP進行恢復(fù)。在12.2 kbit/s模式下采用分裂矩陣(SMQ)的方式進行矢量量化,在其它模式下采用分裂矢量(SVQ)的方式進行矢量量化。由于在12.2kbit/s中,每一幀需要進行2次線性預(yù)測編碼(LPC)分析,所以會得到2組LSF系數(shù)。AMR在TD-SCDMA系統(tǒng)的具體實現(xiàn)過程中將這2組系數(shù)進行聯(lián)合量化。也就是將矩陣(r(1),r(2))分為5個2×2的子陣,分別
進行矢量量化,維數(shù)為4,碼本容量分別為128(子陣1),64(子陣5),256(子陣 2,3,4),失真 測度選擇計算量最小也有主觀評價意義的歐式距離,在碼本搜索過程中采用了全搜索算法。同樣,對于其它的編碼速率,有相同的思路和操作步驟,最大的差別就是對LSF矢量的子陣劃分,它們的劃分方法是采用維數(shù)為3,3和4的3個子陣(子矢量)。
(2)碼本搜索[4]。TD- SCDMA系統(tǒng)中,AMR自適應(yīng)碼本搜索和代數(shù)碼本搜索是語音合成的關(guān)鍵,它們都是在子幀的基礎(chǔ)上完成的,其中,每個子幀長為5 ms,對應(yīng)4個樣點。自適應(yīng)碼本表征語音信號發(fā)生模型中的周期性結(jié)構(gòu),自適應(yīng)碼本搜索通過一個長時預(yù)測濾波器(LTP),去除信號中存在的長時相關(guān),使殘差信號頻譜更加平坦,以便于形成白噪聲激勵信號,同時提取基音延遲和對應(yīng)的基音增益。再經(jīng)過基音開環(huán)和閉環(huán)分析得到分?jǐn)?shù)基音延遲決定后,自適應(yīng)碼本矢量v (n)通過在最佳的整數(shù)延遲kopt和相位(分?jǐn)?shù)延遲)t處內(nèi)插就得到
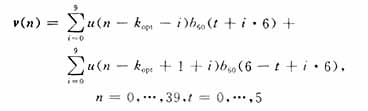
代數(shù)碼本表示語音信號發(fā)生模型中的隨機信號,根據(jù)感覺加權(quán)均方誤差最小的原則,最終獲得[2]。代數(shù)碼本結(jié)構(gòu)是基于交織單脈沖序列(ISPP)的,其脈沖幅度和位置的取值都要受到一定的限制以滿足一定的代數(shù)結(jié)構(gòu)和比特分配要求,對于不同速率,脈沖位置和個數(shù)都選擇不同。而且在系統(tǒng)中,碼本設(shè)計上改進了以前的高斯隨機碼本結(jié)構(gòu),構(gòu)造了中心削波的重疊碼本。經(jīng)稀疏后,碼本中就會產(chǎn)生90%的零值。這樣是可以簡化搜索過程的。通過最大化下式可?量,d=Htx2表示目標(biāo)信號x2(n)和沖激響應(yīng)h′w(n)之間的相關(guān)性。在得到以上參數(shù)后,AMR中系統(tǒng)總共設(shè)計了3種量化器。AMR-12.2代數(shù)碼本增益的量化是采用6比特標(biāo)量量化器,AMR -4.75是將自適應(yīng)碼本增益和代數(shù)碼本增益進行聯(lián)合量化,而對于其他速率則是按原始語音與合成語音的加權(quán)誤差最小找出目標(biāo)矢量。由于考慮多速率的公用,所以碼本容量較大,這與其他編碼器是不同的。
(3)AMR解碼原理。解碼器分為3大部分:譯碼部分、語音合成和后濾波。在解碼器輸入端,從接收的比特流中獲得LSP矢量、自適應(yīng)碼本和代數(shù)碼本參數(shù)(索引和增益)等。LSP線譜對參數(shù)還需要轉(zhuǎn)化為線性預(yù)測濾波器系數(shù),再根據(jù)LP系數(shù)內(nèi)插得到各子幀的合成濾波器系數(shù)。激勵矢量由自適應(yīng)碼本和代數(shù)碼本經(jīng)各自的增益加權(quán)后獲得,將激勵矢量輸入合成濾波器得到重建的語音信號。最后,重建的語音信號還需要經(jīng)過后濾波處理。ACELP編碼器編碼的語音可看成是包含了高斯噪聲的原始語音。使用后濾波可以減少合成語音中包含的噪聲信號,從而有效地提高合成語音的語音質(zhì)量。后處理包括兩部分功能:自適應(yīng)后濾波和信號放大。自適應(yīng)增益控制用于補償合成語音和經(jīng)過后濾波的合成語音之間的失真。將信號通過以下濾波器,就可得到修正的后濾波合成語音。
3 結(jié)束語
AMR的提出能提供高質(zhì)量的語音,增強抗信道誤差的能力,通過低編碼速率靈活配置提高了系統(tǒng)容量,編碼速率根據(jù)無線環(huán)境和本地容量需求動態(tài)選擇不同模式。筆者圍繞AMR語音編碼算法進行分析和研究。該算法已在TI公司的TMS320 C5510DSP上采用定點C語音和匯編語言的混合編程實現(xiàn),并用于TD-SCDMA系統(tǒng)中,運算量能降低到20 MIPS左右,通過在TD-SCDMA系統(tǒng)的硬件平臺上自環(huán)測試,可得到良好的通話語音質(zhì)量,結(jié)果是很理想的。