
摘 要: 為適應集群環(huán)境下數(shù)據(jù)量在100GB以下數(shù)據(jù)庫訪問頻繁和響應速度較高的需要,提出一種架構(gòu)于Linux虛擬服務器(LVS)基礎之上、應用廣泛且擴展性強的數(shù)據(jù)庫集群服務器結(jié)構(gòu),并在復制技術(shù)的基礎上進行改進,改變復制對象,給出了相應特定的復制算法,并且通過實驗驗證了系統(tǒng)的可行性。
關(guān)鍵詞: 復制 負載平衡 集群 數(shù)據(jù)庫
隨著Internet業(yè)務量爆炸性的增長,使得傳統(tǒng)的單一數(shù)據(jù)庫服務器不堪重負。不斷更新的硬件只會使整個系統(tǒng)的代價升高且收效甚微,并且還會造成資源的浪費。由此,基于集群的網(wǎng)絡負載平衡策略應運而生并成為有效的新對策。
本文提出了一種構(gòu)架于Linux虛擬服務器(LVS)基礎之上的數(shù)據(jù)庫集群服務器體系結(jié)構(gòu),用于解決數(shù)據(jù)量在100G以下且數(shù)據(jù)庫訪問頻繁和對響應速度要求較高的需求。重點提出了與這種體系結(jié)構(gòu)相對應的基于SQL語句分發(fā)請求的復制算法,并通過實驗來驗證算法的可行性。由于所采用的設備均是普通的PC機和交換機,所使用的系統(tǒng)平臺是源碼開放的Linux操作系統(tǒng),并且系統(tǒng)是針對Anycast型[2]任務開發(fā)的,可以應用于絕大多數(shù)的網(wǎng)站和論壇,所以具有一定的推廣價值。
1 數(shù)據(jù)復制技術(shù)
通常,服務器的數(shù)據(jù)分為兩種:一種是結(jié)構(gòu)化的數(shù)據(jù)庫數(shù)據(jù),另一種是非結(jié)構(gòu)化或半結(jié)構(gòu)化的文件[4]。這里只討論結(jié)構(gòu)化的數(shù)據(jù)庫數(shù)據(jù)。
數(shù)據(jù)庫集群的數(shù)據(jù)復制包括數(shù)據(jù)定位和數(shù)據(jù)更新。對于數(shù)據(jù)定位,目前有三種方式:
(1)采用分區(qū)方式,即對數(shù)據(jù)庫中的數(shù)據(jù)進行劃分操作,其保證了數(shù)據(jù)操作的高效率,但不能保證數(shù)據(jù)的高可用性和高可靠性" title="高可靠性">高可靠性。
(2)采用不分區(qū)方式,使得數(shù)據(jù)庫在每個節(jié)點上都保存有副本,其保證了數(shù)據(jù)的高可用性和高可靠性,但數(shù)據(jù)同步困難。本文則是由此切入,提出一種新算法用以解決在保證數(shù)據(jù)的高可用性和高可靠性的情況下數(shù)據(jù)同步困難的問題。
(3)上述兩者相結(jié)合,這樣就需要動態(tài)的數(shù)據(jù)分配策略來管理這些數(shù)據(jù),當然也可以通過手動管理方式來模擬此過程。
數(shù)據(jù)更新一般使用即時更新。
對于采取不分區(qū)方式的數(shù)據(jù)定位,其數(shù)據(jù)更新常用的算法有快照復制、基于主節(jié)點的對稱復制、基于TOKEN的對稱復制和混合復制。這些算法都各有千秋,但它們有一個共同的特點,即都是在節(jié)點之間或主節(jié)點與從節(jié)點之間拷貝數(shù)據(jù)。人們知道,任何情況下,對數(shù)據(jù)庫的操作無非只有四種:增、刪、改、查。對于這種基于負載調(diào)度請求的且不能識別請求內(nèi)容而只把數(shù)據(jù)庫當作文件來操作的算法,不但不能發(fā)揮數(shù)據(jù)庫存取數(shù)據(jù)的優(yōu)勢,同時也為整個集群帶來了額外的開銷,所以不能說是真正意義上的數(shù)據(jù)庫集群。
2 系統(tǒng)設計
為了保證數(shù)據(jù)的高可用性和高可靠性,同時又能提高數(shù)據(jù)更新的效率,充分發(fā)揮數(shù)據(jù)庫本身的優(yōu)勢,本文提出一種新的思路,即在LVS基礎之上,將其內(nèi)網(wǎng)中傳送的數(shù)據(jù)包變成SQL語句,通過數(shù)據(jù)接口,在各個節(jié)點機上對其各自擁有數(shù)據(jù)庫進行讀寫操作。由于所傳送的對象不是整塊數(shù)據(jù)而是一條條的SQL語句,使得整個集群減少了更新時間并且增強了負載能力。
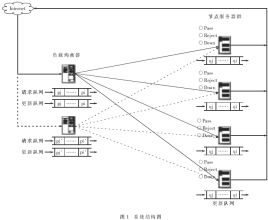
如圖1所示,本系統(tǒng)是基于LVS的直接路由模式(DR)來構(gòu)建的。其采用單工連接方式,節(jié)點服務器處理過的應答數(shù)據(jù)不再經(jīng)過均衡器" title="均衡器">均衡器,而直接返回給客戶端" title="客戶端">客戶端,這就是說,每個節(jié)點服務器都擁有能夠到達客戶端的合法IP地址,并且負載均衡器" title="負載均衡器">負載均衡器與各節(jié)點服務器必須有一塊網(wǎng)卡與內(nèi)網(wǎng)交換機相連。同時,為了使節(jié)點間負載平衡、節(jié)點內(nèi)有序執(zhí)行,在每個節(jié)點服務器上都設置有一個隊列結(jié)構(gòu),用于保證操作的順序性,并且在負載均衡器上設置有兩個對列結(jié)構(gòu)用于協(xié)調(diào)節(jié)點間查詢和更新的操作。
3 基于SQL語句分發(fā)請求的復制算法
復制算法一般包括數(shù)據(jù)的定位和數(shù)據(jù)副本的同步兩部分,本算法也是如此。
3.1 數(shù)據(jù)的定位
如上所述,基于本算法的系統(tǒng)結(jié)構(gòu)中所使用的定位技術(shù)是基于定位服務器的方式。也就是說,從客戶端發(fā)出的對數(shù)據(jù)庫操作的任何請求都必須經(jīng)過定位服務器的分發(fā)后,請求才能在節(jié)點服務器上得到響應。本系統(tǒng)中,定位服務器就是負載均衡器。
如圖2所示,當負載均衡器收到客戶端對數(shù)據(jù)庫操作的請求后,首先要進行區(qū)分,即是SELECT語句還是非SELECT語句,當請求是SELECT語句時,則通過負載平衡算法[2]選擇當前負載最輕的節(jié)點,然后將SELECT語句發(fā)送到此節(jié)點,在節(jié)點數(shù)據(jù)庫中進行查詢處理后直接將應答數(shù)據(jù)返回給客戶端,而此時的返回數(shù)據(jù)包的源IP地址仍然是負載均衡器上的VIP地址(這是由LVS的直接路由模式?jīng)Q定的)。
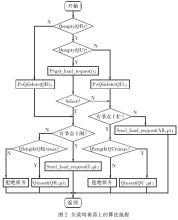
可是,當請求是非SELECT語句時,情況則有所不同,因為所有非SELECT語句均是更新語句,如INSERT、DELECT和UPDATE。此時,負載均衡器通過其所擁有的鄰接表查找各節(jié)點的MAC地址,然后復制與節(jié)點數(shù)量相同請求包,再分別封裝成幀并改寫幀上的MAC地址,使每個節(jié)點都成為目的節(jié)點,接著將這批幀發(fā)送到內(nèi)網(wǎng)。于是,每個節(jié)點服務器都將收到符合自己MAC地址的幀后,拆裝、提取SQL信息,在節(jié)點數(shù)據(jù)庫中進行數(shù)據(jù)更新,最后再將更新后的狀態(tài)信息(如更新成功或失敗)直接返回給客戶端,同樣此時的返回包的源IP地址仍然是均衡器上的VIP。
3.2 數(shù)據(jù)副本的同步
本系統(tǒng)在進行數(shù)據(jù)同步時,采用即時更新的同步技術(shù)。
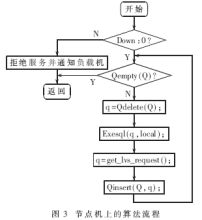
由于數(shù)據(jù)庫集群服務器的數(shù)據(jù)庫都是相對獨立的,每臺服務器都可以獨立承擔服務工作,且數(shù)據(jù)的復制度較高,不存在單點失效的問題,所以節(jié)點服務器的工作重點應是數(shù)據(jù)快速而穩(wěn)定的存取,保持各節(jié)點間數(shù)據(jù)的一致性。因此,當有請求到達時,無論是查詢語句(SELECT語句)還是更新語句(非SELECT語句),都先進入節(jié)點機上的操作隊列,如圖3所示,然后逐一順序取出執(zhí)行,這樣可以保證對數(shù)據(jù)庫操作的順序性和一致性。
3.3 復制算法的實現(xiàn)
(1)負載均衡器上鄰接狀態(tài)表,請求隊列和更新隊列
可以看出,負載均衡器是這個集群系統(tǒng)" title="集群系統(tǒng)">集群系統(tǒng)的核心。均衡器是通過鄰接狀態(tài)表來管理集群中節(jié)點服務器的。鄰接狀態(tài)表是由節(jié)點名、MAC地址和狀態(tài)構(gòu)成。節(jié)點名是管理員預先定義的,用于區(qū)分各節(jié)點機; MAC地址是指節(jié)點服務器對應于內(nèi)網(wǎng)的那塊網(wǎng)卡的地址;狀態(tài)是指當前節(jié)點機的狀態(tài)(0為可操作,1為忙,2為停機)。當有請求到達時,均衡器首先區(qū)分請求中的是SELECT語句還是非SELECT語句,若是SELECT語句,則從鄰接狀態(tài)表中查找狀態(tài)為0的節(jié)點,若為0的節(jié)點多于一個時,則通過負載平衡算法[2]選出負載最輕的節(jié)點進行分配;若是非SELECT語句,均衡器便查找狀態(tài)不為2(即停機)的節(jié)點分發(fā)請求,若其中有節(jié)點的狀態(tài)為1(即忙,也就是說此節(jié)點服務器上的操作隊列已滿),則將該語句入均衡器上的更新隊列排隊,直到所有運行節(jié)點均為不忙,才出隊分發(fā);若所有運行節(jié)點的狀態(tài)均不為0,此時若帶有SELECT語句的請求到達,均衡器便將該語句入請求隊列,直到有狀態(tài)為0的節(jié)點出現(xiàn),才出隊進行分發(fā);當均衡器上的請求隊列或更新隊列均滿時,均衡器將拒絕查詢請求或更新請求,直到隊列不滿。
圖2中,Qempty(Q)、Qinsert(Q,i)、Qdelete(Q)和Qlength(Q)是對隊列的判空、入隊、出隊和求長度的操作,get_load_request()為取請求函數(shù),send_load_request()為發(fā)送請求函數(shù)。
(2)節(jié)點服務器上的操作隊列和信號機制
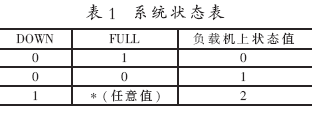
節(jié)點服務器的主要工作是對數(shù)據(jù)庫的存取。引入操作隊列就是為了保證對數(shù)據(jù)庫操作的順序性和一致性。這里,需要再引入兩個信號量DOWN和FULL,用以監(jiān)控節(jié)點機的狀態(tài)。DOWN為節(jié)點機系統(tǒng)狀態(tài)(0為正常,1為異常),F(xiàn)ULL為操作隊列狀態(tài)(0為隊列滿,1為隊列不滿),它們分別與負載均衡器上狀態(tài)值同步,其對照表如表1所示。
圖3中,Qempty(Q)、Qdelete(Q)和Qinsert(Q,q)是對隊列的判空、出隊和入隊的操作,get_lvs_request()為取請求函數(shù),Exesql(q,local)為SQL執(zhí)行函數(shù)。
4 系統(tǒng)實現(xiàn)與測試
4.1 系統(tǒng)實現(xiàn)
本集群系統(tǒng)性能測試環(huán)境如下:
(1)基于6+1臺PC的集群服務器,即一臺作負載均衡器,剩余6臺作節(jié)點服務器。PC機的基本配置為:CPU PⅢ 900MHz,內(nèi)存為384MB,硬盤為40GB。
(2)交換機為24Port 10/100Mbps Fast ethernet Switch。
(3)軟件配置:
操作系統(tǒng):Linux 7.2 內(nèi)核為2.4.18。
集群中間件(SSI):使用JAVA開發(fā)的基于SQL語句復制的數(shù)據(jù)庫集群算法。
數(shù)據(jù)庫為:MySql 3.23.49。
網(wǎng)絡協(xié)議:TCP/IP。
(4)測試軟件:WebBench。
4.2 測試與分析
為使測試更具對比性,選用兩種算法進行,一種是基于SQL語句復制的算法,另一種是基于快照復制[3]的算法。
(1)測試基于數(shù)據(jù)庫服務器集群系統(tǒng)的查詢請求的吞吐量。
(2)測試基于數(shù)據(jù)庫服務器集群系統(tǒng)的更新請求的吞吐量。
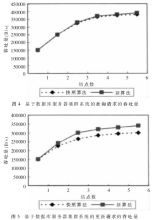
從以上結(jié)果可以看出,在測試查詢請求的情況下,雖然基于SQL語句復制的算法略高些,但兩者相差不是很大,如圖4所示。在測試更新請求的情況下,差距很明顯,如圖5所示,由于基于快照復制算法的系統(tǒng),所有的更新都在一臺主節(jié)點上進行,然后再將更新數(shù)據(jù)分發(fā)到其他備份節(jié)點。這樣,雖然能夠保證數(shù)據(jù)的一致性,但主節(jié)點很容易形成新的瓶頸,使得在節(jié)點增多的情況下,主節(jié)點負載過大。然而,基于SQL語句復制算法的系統(tǒng),由于所傳送的為一條一條的語句,并非整塊數(shù)據(jù),所以在節(jié)點服務器上對其處理的速度就比較快,并且內(nèi)部的網(wǎng)絡傳輸影響甚小,從而使集群整體的更新速度得到提高。
本文提出了一種新的基于SQL語句請求分發(fā)的數(shù)據(jù)庫集群服務器的體系結(jié)構(gòu),對于研究和開發(fā)數(shù)據(jù)庫集群服務器,特別是集群環(huán)境中的數(shù)據(jù)同步管理,具有一定的指導意義和參考價值。
目前系統(tǒng)處于測試階段,還需要不斷完善。例如在網(wǎng)絡協(xié)議方面,TCP/IP協(xié)議雖然是一種很好的協(xié)議,但在相對距離較近、且同構(gòu)的集群系統(tǒng)中,其網(wǎng)絡開銷自然不容輕視;還有,由于本集群采用的是集中式分配器作為整個上行數(shù)據(jù)的入口點,所有的負載分配工作都集中在負載均衡器上,當負載均衡器出現(xiàn)故障或負載過重時,將直接影響到整個集群系統(tǒng)的性能;另外,系統(tǒng)的容錯性和安全性等問題都需要進一步解決。
參考文獻
1 Zegura E W,Ammar M H,F(xiàn)ei Zongming et al.Application-Layer Anycasting:A Server Selection Architecture and Use in a Replicated Web Service.IEEE/ACM Transactions on Net-working,2000;8(4)455-466
2 Hui L,Qinke P,Junyi S.Node-Agents Based Clustered Database Server.Mini-Micro Systems,2003;24(2)225-229
3 邵佩英.分布式數(shù)據(jù)庫系統(tǒng)及其應用.北京:科學出版社,2005
4 Content manage 8.1,IBM.http://www-900.ibm.com/cn/soft-ware/products/db2/index_solution.shtml
5 Shah S.Linux管理員指南.北京:機械工業(yè)出版社,2001
6 毛德操,胡希明.Linux內(nèi)核源代碼情景分析.杭州:浙江大學出版社,2001