
使用網(wǎng)絡(luò)處理器來(lái)設(shè)計(jì)通信系統(tǒng),所設(shè)計(jì)的系統(tǒng)結(jié)構(gòu),和設(shè)計(jì)時(shí)所采用的設(shè)計(jì)方法,與傳統(tǒng)的方法相比都很不相同。影響最大的是設(shè)計(jì)工作的重點(diǎn),設(shè)計(jì)人員的注意力將從硬件線路和通信協(xié)議的細(xì)節(jié)的考慮中,轉(zhuǎn)向軟件、服務(wù)以及最終用戶的技術(shù)要求方面。也就是說(shuō),設(shè)計(jì)將是以軟件為中心,以通信服務(wù)為中心,和以最終用戶的技術(shù)要求為注意的集中點(diǎn)。設(shè)計(jì)公司將一改過(guò)去集中注意于硬件設(shè)計(jì)的傳統(tǒng),轉(zhuǎn)而將注意力集中于用戶所需要的服務(wù)方面,并考慮如何使用軟件來(lái)實(shí)現(xiàn)用戶所需要的服務(wù)。
這些變化與進(jìn)展在相當(dāng)大程度上應(yīng)該歸功于網(wǎng)絡(luò)處理單元(NPU, network processing unit)的推動(dòng)。在這種情況下,系統(tǒng)設(shè)計(jì)人員如果對(duì)于網(wǎng)絡(luò)處理器能夠運(yùn)用自如,那么就可以充分了解網(wǎng)絡(luò)處理器的作用,并且能夠感覺(jué)到,與使用網(wǎng)絡(luò)處理器隨之而來(lái)的潛在自由空間。系統(tǒng)設(shè)計(jì)人員也才有可能最大限度地發(fā)揮網(wǎng)絡(luò)處理器的潛能。
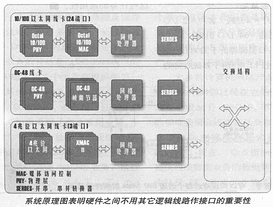
附圖是系統(tǒng)原理圖,它顯示出網(wǎng)絡(luò)處理器在系統(tǒng)設(shè)計(jì)中所處的重要位置。NPU一般位于物理層(MAC或幀調(diào)節(jié)器)線路和交換結(jié)構(gòu)之間。在圖中并串行/串并行轉(zhuǎn)換器(SERDES)在NPU和交換結(jié)構(gòu)造之間起接口作用。
NPU的運(yùn)行速度有待提高
表1給出了在不同的數(shù)據(jù)傳輸速率條件下,網(wǎng)絡(luò)處理器處理一個(gè)40字節(jié)的分組(最小的通信分組)所需要的時(shí)間。例如,在數(shù)據(jù)傳輸速率為1G位/秒時(shí),網(wǎng)絡(luò)處理器可以有360 ns 的時(shí)間來(lái)處理此分組。在這段時(shí)間內(nèi),NPU必須對(duì)分組進(jìn)行檢查,語(yǔ)法分析,以及必要的編輯和查表(有時(shí)對(duì)于分組的內(nèi)容需要按照不同的策略采取不同的處理措施,有的繼續(xù)向前傳送,有的要送去排隊(duì),有的需要作標(biāo)記;一般說(shuō)來(lái),對(duì)于一個(gè)分組可能要進(jìn)行2到3種數(shù)據(jù)庫(kù)的查表處理)。對(duì)于即使是比較低的傳輸速率1G位/秒,網(wǎng)絡(luò)處理器也只有360 ns 來(lái)完成上述作業(yè);如果傳輸速率為100G位/秒,對(duì)于每個(gè)分組就只有3.6 ns 的時(shí)間來(lái)進(jìn)行處理了。
從目前情況來(lái)看,價(jià)格適中的SRAM,存取時(shí)間為10 nsec,有望提高到5 nsec。如果將一個(gè)10 nsec的SRAM用于1G/秒的數(shù)據(jù)流,在留給處理分組的360 nsec 時(shí)間窗口內(nèi),只能對(duì)存儲(chǔ)器進(jìn)行36次的存取。如果用于10 G位/秒的數(shù)據(jù)流,存取次數(shù)將減少到只能進(jìn)行3次了;即使是采用5 nsec的SRAM,也只能進(jìn)行7次存取。
從表1所給出的數(shù)據(jù)可以看出,為了有效地提高數(shù)據(jù)處理速率,只能將處理步驟分段,并采用流水線的方式來(lái)進(jìn)行處理,或者采用多個(gè)處理機(jī)來(lái)并行處理(即多個(gè)處理機(jī)同時(shí)對(duì)不同分組進(jìn)行處理)。這種解決辦法,對(duì)于策略查表存儲(chǔ)器,和內(nèi)容尋址存儲(chǔ)器(CAM)都適用。例如,對(duì)于40 G位/秒的數(shù)據(jù)流,采用10 nsec 的存儲(chǔ)器,在允許的時(shí)間內(nèi)一次存取也進(jìn)行不了。這時(shí),設(shè)計(jì)人員必須采用許多并行的存儲(chǔ)器陳列。
網(wǎng)絡(luò)處理器可以按照它們對(duì)于數(shù)據(jù)處理的速率來(lái)進(jìn)行分類。在表1的中間部分列出了對(duì)于一定的數(shù)據(jù)速率,需要采用的網(wǎng)絡(luò)處理器種類和數(shù)量。例如,對(duì)于2.5 G位/秒的數(shù)據(jù)流,需要使用3個(gè)1G位/秒的處理器來(lái)進(jìn)行處理。而對(duì)于100 G位/秒的數(shù)據(jù)流,則需要144個(gè)這樣的處理器。對(duì)于這樣的數(shù)據(jù)流,也許改為采用12個(gè)OC-192處理器,或兩個(gè)OC-768處理器更合適一些。
表1 對(duì)網(wǎng)絡(luò)處理器處理速率的要求(以每分組40字節(jié)為例)
| 傳輸速率(G位/秒) | 可以用來(lái)處理分組的時(shí)間(nsec/分組) | 所需處理器的種類及數(shù)量 | SRAM存取次數(shù)(nsec) | |||||
| 1G位/秒 | OC-48 | OC-192 | OC-768 | 10 | 5 | 2 | ||
| 1 | 360 | 1 | - | - | - | 36 | 72 | 180 |
| 2.5 | 144 | 3 | 1 | - | - | 14 | 28 | 72 |
| 10 | 36 | 12 | 4 | 1 | - | 3 | 7 | 18 |
| 40 | 9 | 48 | 16 | 4 | 1 | 0 | 1 | 4 |
| 100 | 3.6 | 144 | 48 | 12 | 2 | 0 | 0 | 1 |
| 200 | 1.8 | 288 | 96 | 24 | 4 | 0 | 0 | 0 |
除了實(shí)際處理分組需要時(shí)間以外,將分組從網(wǎng)絡(luò)一方轉(zhuǎn)移進(jìn)來(lái),和將數(shù)據(jù)轉(zhuǎn)移到交換結(jié)構(gòu)一方去也去要花費(fèi)時(shí)間。表2給出的分?jǐn)倳r(shí)間是總時(shí)間的25%。以上數(shù)字對(duì)于MAC接口是很符合實(shí)際的假設(shè),但是對(duì)于交換結(jié)構(gòu)接口,由于分段(segmentation)的效率一般只有50%,因此在計(jì)算時(shí)需要留下100%的速度余度,才能跟得上通信線路的速度。
表2 對(duì)于網(wǎng)絡(luò)媒體/交換結(jié)構(gòu)接口的要求
| 媒體訪問(wèn)控制和交換結(jié)構(gòu)的接口 | ||||||
| 25%的分?jǐn)?/span> | 22位 | 64位 | 128位 | |||
| SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 39MHz | 20MHz | - | - | - | - |
| 2.5位/秒 | 98MHz | 49MHz | 49MHz | 24MHz | - | - |
| 10位/秒 | 391MHz | 195MHz | 195MHz | 98MHz | 98MHz | 49MHz |
| 40位/秒 | 1563MHz | 781MHz | 781MHz | 391MHz | 391MHz | 195MHz |
| 100位/秒 | 3906MHz | 1953MHz | 1953MHz | 977MHz | 977MHz | 488MHz |
| 200位/秒 | 7813MHz | 3906MHz | 3906MHz | 1953MHz | 1953MHz | 977MHz |
從表2可以看出,對(duì)于10G位/秒的傳輸速率,如果采用32位單數(shù)據(jù)速率(SDR)總線,則總線必須工作在391MHz。而對(duì)于40G位/秒的傳輸速率,假定采用64位SDR總線,總線必須工作在781MHz。表3總結(jié)了對(duì)分組緩沖存儲(chǔ)器的要求。分組緩沖存儲(chǔ)器至少必須具有3倍用通信線路的速度的傳輸速率(300%的速度余度)。表3中分門別類地給出了這一要求。例如,對(duì)于10G位/秒的傳輸速率,如果采用的是64位的雙倍數(shù)據(jù)速率(DDR)緩沖存儲(chǔ)器,則需要工作在313MHz以上的頻率。
表3 對(duì)分組緩沖存儲(chǔ)器的要求
| 分組存儲(chǔ)器的界面 | ||||||||
| 300%速度余度 | 32位(MHz) | 64位(MHz) | 128位(MHz) | 512位(MHz) | ||||
| SDR | DDR | SDR | DDR | SDR | DDR | SDR | DDR | |
| 1G位/秒 | 125MHz | 63 | - | - | - | - | - | - |
| 2.5G位/秒 | 313MHz | 156 | 156MHz | 78MHz | - | - | - | - |
| 10位/秒 | 1250MHz | 625 | 625MHz | 313MHz | 313MHz | 156MHz | - | - |
| 40位/秒 | 5000MHz | 2500 | 2500MHz | 1250MHz | 1250MHz | 625MHz | 313MHz | 156MHz |
| 100位/秒 | 12500MHz | 6250 | 6250MHz | 3125MHz | 3125MHz | 1563MHz | 781MHz | 391MHz |
| 200位/秒 | 25000MHz | 12500 | 12500MHz | 6250MHz | 6250MHz | 3125MHz | 1563MHz | 781MHz |
網(wǎng)絡(luò)處理單元(NPU)的結(jié)構(gòu)問(wèn)題
網(wǎng)絡(luò)處理器和中央處理單元(CPU)不同。網(wǎng)絡(luò)處理器需要對(duì)它所需要進(jìn)行處理自行抽象提取。它必須能夠識(shí)別字段(field),分組(packet),和數(shù)據(jù)流(flow)。它必須對(duì)于它所需要進(jìn)行的處理功能,例如:語(yǔ)法分析,編輯,搜尋,和調(diào)度等,具有特殊的運(yùn)算能力。
在程序編制模型方面,網(wǎng)絡(luò)處理器和CPU并沒(méi)有根本的不同:它也是一個(gè)可以儲(chǔ)存程序的微編碼機(jī)。但是在數(shù)據(jù)的模型方面則有很大的區(qū)別。NPU處理的是一種恒定的連續(xù)數(shù)據(jù)流(一種數(shù)據(jù)流結(jié)構(gòu)),因此不需要將數(shù)據(jù)從一個(gè)大容量存儲(chǔ)器中移進(jìn)移出。如上所述,網(wǎng)絡(luò)處理器為了滿足一定的數(shù)據(jù)速率,絕對(duì)地需要并行處理,或流水線(pipelined)結(jié)構(gòu),或者兩種方式同時(shí)都需要采用。
另一個(gè)問(wèn)題是網(wǎng)絡(luò)處理器的可編程性能。一個(gè)極端是使它具有最大的可編程性,因而使它具有最大的靈活性,也可以在最大程度上適應(yīng)未來(lái)的發(fā)展變化(即使它可以通過(guò)新開(kāi)發(fā)的軟件使系統(tǒng)改變或升級(jí),而不是當(dāng)要求改變系統(tǒng)時(shí)就更新硬件)。這種方式的缺點(diǎn)是,為了完成一項(xiàng)作業(yè)需要執(zhí)行許多個(gè)指令,因而可能導(dǎo)致缺乏凈空(headroom)。
另一種折衷方式,稱為“適當(dāng)程度的可編程性”。這種方式提供一定程度的可編程性以適應(yīng)變化的需要,或者說(shuō)使處理器具有一定的靈活性。但是它不能適應(yīng)完全的重新編程的需要。和RISC型的CPU類似(RISC采用簡(jiǎn)約的有效指令集,以提高CPU速度);而NPU則通過(guò)提供適當(dāng)?shù)目删幊绦裕沟孟到y(tǒng)設(shè)計(jì)人員能夠犧牲某些靈活性,去提高運(yùn)行速度,換取更多的性能凈空。
對(duì)于運(yùn)行在載體網(wǎng)絡(luò)核心的交換機(jī)和路由器,速度的要求高于一切。這些在網(wǎng)際間工作的裝置,不需要進(jìn)行復(fù)雜的分組處理功能,只是要求將分組以最大的線速度向前傳送。與此相反,在企業(yè)網(wǎng)的邊沿,線速度明顯地比較低,而交換機(jī)對(duì)分組的處理能力卻要求相當(dāng)?shù)母摺@纾瑢?duì)于多協(xié)議標(biāo)記交換機(jī),它處于網(wǎng)絡(luò)的邊沿,需要對(duì)某些數(shù)據(jù)流進(jìn)行識(shí)別并相應(yīng)地對(duì)某些分組予以標(biāo)記。
交換機(jī)的設(shè)計(jì)人員可以根據(jù)這些不同的要求,以及交換機(jī)所處的位置,為預(yù)計(jì)在企業(yè)網(wǎng)邊沿使用的交換機(jī)選擇可以充分編程的NPU。而對(duì)于將應(yīng)用在網(wǎng)絡(luò)核心部位的交換機(jī),則應(yīng)該選擇編程能力有限,但是具有較高速度的NPU。
網(wǎng)絡(luò)處理器的實(shí)現(xiàn)方式
網(wǎng)絡(luò)處理器的實(shí)現(xiàn)方式大體上可以分為三種。一種是采用專用的ASIC或FPGA(后者往往功能不夠完整,或者性能不夠理想)。這種方式就是依靠“硬件”的方式,它具有最高的性能,但是靈活性也最差(因?yàn)樵O(shè)計(jì)決策是熔制在硅的體內(nèi))。此外,ASIC的開(kāi)發(fā)過(guò)程比較長(zhǎng),一次性的、不可重復(fù)使用的投入的費(fèi)用也比較高。
另一種方式是將許多個(gè)RISC CPU做在一塊芯片上,采用對(duì)稱多重處理的運(yùn)行方式(使用微編碼將通用CPU轉(zhuǎn)變成為專用的網(wǎng)絡(luò)處理器)。這種實(shí)現(xiàn)方式,由于NPU的一切行為幾乎都是通過(guò)軟件實(shí)現(xiàn)的,因此靈活性最高。這種方式所需要的開(kāi)發(fā)時(shí)間比較短,它展現(xiàn)在設(shè)計(jì)人員面前的形象是設(shè)計(jì)人員十分熟悉的編程模型。然而,隨著軟件復(fù)雜性的增加,這種方式的費(fèi)用也在增長(zhǎng)。由于嚴(yán)重地依賴軟件,這種方式實(shí)現(xiàn)的系統(tǒng),與采用專用ASIC實(shí)現(xiàn)的系統(tǒng)相比性能較差,所消耗的功率也較多。
介乎上述二者之間的一種實(shí)現(xiàn)方式是流水線方式,它采用一些具有不同功能的專用處理器,組成“裝配線”型式的數(shù)據(jù)流構(gòu)造。采用流水線方式實(shí)現(xiàn)的系統(tǒng),性能接近用ASIC實(shí)現(xiàn)的系統(tǒng),而在編程的靈活性方面又和多處理器實(shí)現(xiàn)的系統(tǒng)相差不多。
衡量NPU技術(shù)水平的尺度
設(shè)計(jì)人員十分關(guān)心的一個(gè)問(wèn)題是技術(shù)水平。衡量技術(shù)水平,可以從幾個(gè)不同的層次加以分析。
* 在芯片層次,人們關(guān)心的問(wèn)題是:在一個(gè)芯片上究竟可以容納多大的處理能力?根據(jù)當(dāng)前的技術(shù)水準(zhǔn),在一個(gè)芯片上可以做成10G位/秒的NPU。
* 在線路卡(line-card)層次,問(wèn)題在于:一張線路卡可以安置多少塊芯片?同樣重要的是:使用一個(gè)小型交換結(jié)構(gòu)或一個(gè)共用的總線,究竟可以將多少塊芯片放在一個(gè)線路卡上,正常地并行運(yùn)行?現(xiàn)在看來(lái),可以在一張卡上安置足夠的處理能力,使之達(dá)到100G位/秒的傳輸要求。
* 在機(jī)架或機(jī)箱層次,問(wèn)題在于,一個(gè)機(jī)架或機(jī)箱,通過(guò)一個(gè)交換結(jié)構(gòu)可以容納多少?gòu)埦€路卡進(jìn)行信息傳遞?現(xiàn)在看來(lái)一個(gè)機(jī)架實(shí)現(xiàn)數(shù)太拉(1012)位的傳輸能力是可能的。
* 在機(jī)房層次,問(wèn)題在于,究竟多大規(guī)模的機(jī)架簇群可以連接在一起仍然能夠進(jìn)行有效的通信?目前在這個(gè)層次上,還沒(méi)有把握說(shuō)清楚,但是一些新建的機(jī)房已經(jīng)把目標(biāo)瞄準(zhǔn)在數(shù)拍它(1015)帶寬的水平。
評(píng)價(jià)一個(gè)NPU不能只看單個(gè)NPU的工作能力,還要看它的互操作性。一個(gè)10G位/秒的NPU,并不一定比一個(gè)9G位/秒的NPU優(yōu)越。它還決定于互操作性:如果9G位/秒的NPU,能夠十分容易地和其它的NPU連接在一起,實(shí)現(xiàn)更強(qiáng)得多的交換能力,那么選用它,不失為明智的選擇。
設(shè)計(jì)人員如何才能發(fā)揮多處理器的優(yōu)勢(shì)?不論是并行結(jié)構(gòu)或者是串行結(jié)構(gòu),都可以采用;也可以采用混合結(jié)構(gòu),即串-并排列的結(jié)構(gòu)。重要的問(wèn)題在于需要考慮:負(fù)荷的平衡(注意不使任何一個(gè)NPU超載);作業(yè)的劃分;保持分組流的順序不亂;維持服務(wù)質(zhì)量;以及對(duì)NPU之間通信業(yè)務(wù)量的控制。
衡量NPU性能的指標(biāo)
如何正確地評(píng)估不同的NPU?關(guān)鍵的指標(biāo)之一是:處理分組的速度(即每秒處理多少百萬(wàn)個(gè)分組或稱為Mpps)。另一個(gè)指標(biāo)是:在一定的分組傳遞速率下,處理每個(gè)分組時(shí),允許進(jìn)行的查表次數(shù)(一般每處理一個(gè)分組允許進(jìn)行2次查表)。當(dāng)然在進(jìn)行處理時(shí)可以利用的存儲(chǔ)器的規(guī)模也是一項(xiàng)重要指標(biāo)。此外,及時(shí)不斷的提高速度也是十分重要的。許多處理策略也需要進(jìn)行周期性的更新。有些NPU具有能以很高的速度向前傳送的性能,但是更新處理策略,或更改某些參數(shù)時(shí),卻需要耗用數(shù)毫秒,甚至數(shù)秒的時(shí)間才能完成。比較理想的NPU,更新策略,更改參數(shù)的時(shí)間最好在數(shù)微秒的時(shí)間范圍內(nèi);這一點(diǎn)對(duì)于用在路由頻繁跳變的場(chǎng)合特別重要。
“凈空”也是需要的。凈空可以看作是在保持線傳送速度不降低的情況下,可能增加的處理功能(或可能增加的處理復(fù)雜問(wèn)題的能力);處理復(fù)雜問(wèn)題的能力(即在一個(gè)時(shí)鐘周期內(nèi),用一個(gè)指令,包括轉(zhuǎn)移這樣的控制指令,可以完成多少處理功能)是另一重要的事項(xiàng)。
設(shè)計(jì)人員應(yīng)該考慮的其它問(wèn)題還有:等待時(shí)間,排隊(duì)和調(diào)度的效率,分組存儲(chǔ)(以及分段)的效率,在硅體內(nèi)多重熔制的效率,芯片的大小,以及這些問(wèn)題對(duì)于總體系統(tǒng)的影響(包括對(duì)于消耗功率和成本的影響)等等。
發(fā)展趨勢(shì)
隨著設(shè)計(jì)人員逐漸習(xí)慣于使用NPU進(jìn)行系統(tǒng)設(shè)計(jì),幾種時(shí)尚可能會(huì)流行。下面列出今后幾年將會(huì)出現(xiàn)的趨向。
* 今日的系統(tǒng)設(shè)計(jì)越來(lái)越趨向于從眾多的制造商那里采購(gòu)ASIC和IC。這些芯片中有許多都是各廠商自家獨(dú)有的產(chǎn)品,與它們相關(guān)聯(lián)的軟件也都是各廠商自行開(kāi)發(fā)的。它們之間往往缺乏互操作性。預(yù)計(jì)今后幾年設(shè)計(jì)人員會(huì)越來(lái)越對(duì)商品化的IC感興趣,并且NPU的發(fā)展毫無(wú)疑問(wèn)將會(huì)進(jìn)一步助長(zhǎng)這種傾向的發(fā)展。在硬件方面的發(fā)展趨勢(shì)是越來(lái)越多地采用現(xiàn)成的商品IC,軟件也在朝這個(gè)方向發(fā)展,例如一些專門的協(xié)議棧開(kāi)發(fā)商正在提供越來(lái)越多的商品軟件部件。以這些ASIC和IC,以及商品軟件部件為基礎(chǔ)的增值服務(wù)業(yè)務(wù)也將會(huì)發(fā)展,并且可能成為交換機(jī)供應(yīng)商引以為榮的特點(diǎn)和具有真正競(jìng)爭(zhēng)力的象征。
* 在市場(chǎng)范圍內(nèi),操作系統(tǒng)的供應(yīng)商將會(huì)趨向聯(lián)合和統(tǒng)一,設(shè)計(jì)人員采用標(biāo)準(zhǔn)操作系統(tǒng)的可能性會(huì)越來(lái)越大。
* 從長(zhǎng)遠(yuǎn)看,可能會(huì)出現(xiàn)一系列標(biāo)準(zhǔn)的硬件平臺(tái),例如標(biāo)準(zhǔn)的機(jī)架,標(biāo)準(zhǔn)的背板等。設(shè)計(jì)人員可能會(huì)從許多廠商中選擇一種線卡,買來(lái)插入標(biāo)準(zhǔn)機(jī)架。
* 在軟件方面,可能會(huì)出現(xiàn)一些標(biāo)準(zhǔn)的軟件集(操作系統(tǒng),協(xié)議軟件棧,管理控制軟件等)。系統(tǒng)設(shè)計(jì)人員將利用這些即插即用的部件組成系統(tǒng),并且增加一些可以提供不同服務(wù)內(nèi)容的線卡。
如果這些趨向成為現(xiàn)實(shí),標(biāo)準(zhǔn)接口問(wèn)題將會(huì)成為十分重要的課題。例如,為了開(kāi)發(fā)一種以太網(wǎng)的線卡,設(shè)計(jì)人員可能會(huì)選擇一種物理層(PHY)芯片、MAC芯片、網(wǎng)絡(luò)處理器以及并串/串并轉(zhuǎn)換器等(參看附圖)來(lái)進(jìn)行設(shè)計(jì)開(kāi)發(fā)。為了簡(jiǎn)化設(shè)計(jì)業(yè)務(wù),縮短開(kāi)發(fā)時(shí)間,這些芯片必須具有明確清晰的接口,應(yīng)該使設(shè)計(jì)人員不需要再花費(fèi)力氣提供連接的邏輯線路,就可以完成任務(wù)。
NPU時(shí)代
網(wǎng)絡(luò)處理器將成為網(wǎng)絡(luò)中各個(gè)系統(tǒng)的重要組成部分,但是目前它還不很成熟。它們將在以下幾個(gè)方面取得重大進(jìn)步:在它們能夠處理的分組的復(fù)雜程度和所具有的智能方面;在可以下載的程序規(guī)模大小方面;隨著線速度的增加在每個(gè)時(shí)鐘周期內(nèi)能夠處理的一個(gè)分組或多個(gè)分組的綜合能力方面。
NPU 的性能正在按照統(tǒng)一的性能指標(biāo)穩(wěn)步提高。經(jīng)過(guò)一段時(shí)間以后,使用網(wǎng)絡(luò)處理器來(lái)設(shè)計(jì)開(kāi)發(fā)通信系統(tǒng)的方法學(xué),估計(jì)將會(huì)和軟件的開(kāi)發(fā)一樣,也會(huì)出現(xiàn)并取得發(fā)展進(jìn)步。