
摘 要: 介紹了數(shù)據(jù)分流技術的發(fā)展狀況,著重分析了TCP粘合技術目前的實現(xiàn)方式,并指出傳統(tǒng)的TCP粘合的軟件實現(xiàn)缺陷,提出一種基于FPGA技術TCP粘合的設計與實現(xiàn),證明了其設計性能上的優(yōu)勢。
關鍵詞: TCP粘合 URL重定向 數(shù)據(jù)分流
傳統(tǒng)的數(shù)據(jù)分流一般基于三層、四層交換,不能在應用層解析數(shù)據(jù),導致數(shù)據(jù)在后端服務器解析后還要相互重新分發(fā),增加了服務器數(shù)據(jù)傳輸?shù)拈_銷。為解決該問題,可以在客戶端" title="客戶端">客戶端與服務器之間采用應用級代理服務器,利用該服務器專門對數(shù)據(jù)包進行解析分發(fā),但是該方式下,數(shù)據(jù)要進入TCP/IP協(xié)議棧,處理速度慢,同時代理服務器還需要與客戶端、服務器雙方通信,需要處理的數(shù)據(jù)量非常大,因此在集群應用中,特別是大規(guī)模負載平衡集群系統(tǒng)中很少使用應用級代理。
在應用級代理的基礎上,為進一步提高數(shù)據(jù)處理的速度,提出了TCP粘合技術[1]。該技術在通信雙方建立通信之初對雙方的握手信號以及通信原語進行分析,獲取必要的信息,決定數(shù)據(jù)的流向,一旦雙方開始通信,該代理就不再對數(shù)據(jù)進行分析,而僅起到一個透明網(wǎng)關的作用,從而提高代理的系統(tǒng)性能。
TCP粘合技術采用軟件處理方式時,由于大量數(shù)據(jù)包不需要上層解析,因此提高了系統(tǒng)性能,但是受軟件處理速度的限制,該技術仍很難應用于大規(guī)模的集群系統(tǒng)。本文提出了一種基于FPGA的TCP粘合技術的高速實現(xiàn)機制,利用硬件的高速處理特性和流水線技術來適應高速網(wǎng)絡傳輸?shù)男枰?BR>1 現(xiàn)存的TCP粘合技術
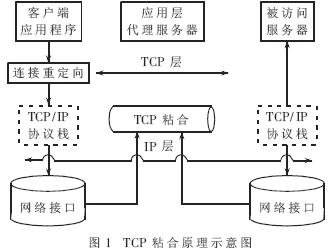
TCP粘合原理如下:(1)監(jiān)聽客戶端的連接請求,并在客戶端發(fā)出連接請求后(從SYN開始),建立客戶端到均衡器之間的連接(通過TCP的三次握手協(xié)議完成)。(2)在隨后的請求報文中分析數(shù)據(jù)并決定真正被訪問的服務節(jié)點。(3)與服務節(jié)點建立另一個連接,將兩個連接粘合在一起(Splicing)。其TCP粘合原理示意圖如圖1所示[2]。
2 TCP粘合技術的硬件實現(xiàn)
TCP粘合技術的關鍵在于,當客戶端發(fā)起連接請求時,系統(tǒng)并不是立即將該請求發(fā)給后端服務器,而是偽裝成服務器與客戶端建立連接,取得用戶的GET數(shù)據(jù)包。通過對URL的匹配來找到信息在后端服務器的位置,然后再在客戶端與服務器之間建立連接通信。
2.1 系統(tǒng)架構
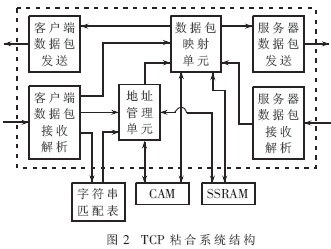
TCP粘合系統(tǒng)結構如圖2所示。
該系統(tǒng)中首先由客戶數(shù)據(jù)接收端對接收到的HTTP報文進行解析,發(fā)現(xiàn)數(shù)據(jù)包為一個發(fā)起連接的SYN數(shù)據(jù)包時,傳給地址管理單元" title="管理單元">管理單元,地址管理就為該連接分配一個地址空間,同時通過映射單元告訴客戶數(shù)據(jù)發(fā)送端與客戶端完成三次握手,建立連接。
當客戶數(shù)據(jù)接收端接收到GET數(shù)據(jù)包時,將該數(shù)據(jù)包發(fā)送給字符串匹配表,該表會將信息在后端服務器的位置返回給地址管理單元,地址管理單元將該信息送給數(shù)據(jù)包映射單元,映射單元將該信息寫入相應的SSRAM空間中,同時通知服務器發(fā)送端與后端服務器建立連接。這樣就完成了一個TCP的粘合過程。
在客戶端與服務器的通信過程中,數(shù)據(jù)包映射單元通過雙方SIP、DIP信息從SSRAM中查找出對應的替換信息,完成雙方數(shù)據(jù)包的映射。
在雙方通信結束時,由地址管理單元對雙方使用的地址空間進行回收;同時為防止通信過程中的異常中斷,地址管理單元內(nèi)部還采用了定時器機制對地址空間進行監(jiān)測,根據(jù)定時器返回結果回收過時地址,防止過時信息被查用。
2.2 設計實現(xiàn)
在該系統(tǒng)中,為完成TCP粘合并且保證TCP通信的可靠性,必須能夠正確識別接收到的數(shù)據(jù)包類型;同時由于實際網(wǎng)絡數(shù)據(jù)傳輸?shù)难訒r,在一個客戶端通信過程中可能會插入很多其他客戶端發(fā)起的新的連接請求,系統(tǒng)內(nèi)部根據(jù)對CAM查找返回的地址來區(qū)分不同的數(shù)據(jù)流,因此要對內(nèi)部地址空間進行有效的釋放回收,為處理網(wǎng)絡通信異常中斷而導致內(nèi)部地址無法回收而引入定時器機制;在數(shù)據(jù)發(fā)送部分,客戶端數(shù)據(jù)發(fā)送模塊偽裝成服務器與客戶端完成TCP三次握手協(xié)議;服務器數(shù)據(jù)發(fā)送模塊則偽裝成客戶端與服務器完成TCP三次握手協(xié)議。雙方在通信過程中轉發(fā)對方的數(shù)據(jù)包。
2.2.1 數(shù)據(jù)收發(fā)
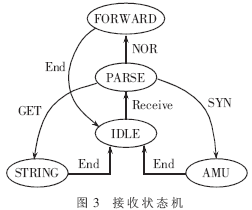
對于系統(tǒng)的發(fā)送接口來說,所有發(fā)送數(shù)據(jù)包的轉發(fā)由數(shù)據(jù)包映射單元完成,因此發(fā)送接口僅完成簡單的數(shù)據(jù)包轉發(fā)功能。而當系統(tǒng)接收到數(shù)據(jù)包時,要對數(shù)據(jù)包進行協(xié)議解析,從而決定數(shù)據(jù)包后端處理的方式。在接收部分主要對三種數(shù)據(jù)包進行區(qū)分:(1)雙方發(fā)起連接的SYN數(shù)據(jù)包。這表示一個新連接的發(fā)起,因此交給地址管理單元,為它分配一個新的地址空間,同時要求發(fā)送端返回一個ACK數(shù)據(jù)包;(2)客戶端發(fā)來的GET數(shù)據(jù)包中含有客戶端所需信息的URL地址,將該數(shù)據(jù)包送給字符串匹配表以獲得該信息所在后端服務器的位置;(3)雙方通信的普通數(shù)據(jù)包。該數(shù)據(jù)包交給數(shù)據(jù)包映射單元實現(xiàn)雙發(fā)的通信。具體接收的狀態(tài)轉換圖如圖3所示。
2.2.2 地址管理單元
在地址管理的方式上,在此處利用一個地址鏈表進行管理,如圖4所示。

每次地址管理單元接收到新的請求連接就從鏈表的頭部取出該可用地址空間,將新請求的SIP、DIP信息寫入該地址的CAM中,同時在該地址對應的SSRAM的頁面中寫入相關的信息,假設鏈表中取出地址為n,頁面大小為m,則SSRAM中對應的頁面起始地址l為:
l=n×m
當?shù)刂饭芾韱卧邮盏阶址ヅ浔矸祷氐暮蠖朔掌魑恢眯畔r,首先通過該數(shù)據(jù)包的SIP、DIP從CAM中查找該數(shù)據(jù)流對應的地址,通過上述計算公式找出SSRAM中對應的頁面,寫入返回信息。
對于地址空間的回收,為防止通信異常中斷而無法回收地址,在系統(tǒng)中采用定時器機制,即在一段時間后對SSRAM中的定時器標志位進行檢測,一旦發(fā)現(xiàn)該標志位過時則通知地址管理單元回收地址。地址管理單元收到某一地址過時的信息后,將該地址掛在地址管理鏈表尾部,同時清除該地址CAM中的SIP、DIP信息。這樣當同一IP發(fā)起新的連接時就不會查找到過時信息。
2.2.3 數(shù)據(jù)包映射單元
為完成數(shù)據(jù)包的映射,該部分需要實現(xiàn)兩個功能:ACK序列號轉換和雙方轉換信息的存儲。
在TCP粘合過程中,由于TCP粘合系統(tǒng)送給客戶端的ACK序列號和后端服務器送給客戶端的ACK序列號不相同,因此要進行ACK序列號的轉換,同時要重新計算數(shù)據(jù)包的TCP/IP校驗和。
現(xiàn)假設客戶端發(fā)送了請求連接的SYN數(shù)據(jù)包,而客戶端返回給客戶端的SYN序列號為地址管理單元分配給該連接的地址A0,而當系統(tǒng)和服務器建立鏈接時服務器端返回的SYN序列號為A1,則根據(jù)這兩個序列號可計算差值A為:A=A0-A1。
以后通信的過程中,只要將服務器發(fā)送給系統(tǒng)的序列號加上A就能夠轉換成為系統(tǒng)送給客戶端的序列號,這樣就完成了服務器端向客戶端發(fā)送數(shù)據(jù)的轉換,反之就可以完成客戶端向服務器發(fā)送數(shù)據(jù)的轉換。
對于數(shù)據(jù)包的校驗和轉換而言,由于校驗和本質上是加法運算,所以只需要在原來的校驗和基礎上加上序列號之差(或減去一個差值)即可完成校驗和的轉換。
在同一個通信過程中,ACK序列號轉換、校驗和的轉換、發(fā)起連接的SYN、GET數(shù)據(jù)包和定時器標志位等信息都需要存儲,由于每個數(shù)據(jù)流需要存儲的內(nèi)容較多,單一的地址已經(jīng)無法滿足存儲要求。此處存儲管理采用頁面式的管理方式。將整個存儲空間分為若干頁面,每個數(shù)據(jù)流信息存入一個頁面中。SSRAM的存儲格式如圖5所示。

3 性能分析
該架構已在試驗系統(tǒng)上實現(xiàn),接收端為兩個GE口。相對于采用TCP粘合的應用代理服務器來說(其中代理服務器CPU Pentium IV 2GHz),具體的性能對比如表1所示。
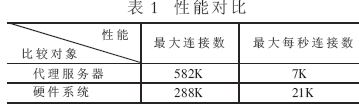
從上表可以看出在最大" title="最大">最大連接數(shù)" title="連接數(shù)">連接數(shù)方面,在本系統(tǒng)中采用一個18Mbit的CAM,它能夠提供的最大地址空間為288K×144bit,只能支持288K的連接數(shù)。對于服務器的最大連接數(shù)來說,SYN和GET數(shù)據(jù)包需要經(jīng)過軟件協(xié)議解析。因此當最大連接數(shù)達到582K時CPU的利用率將達到90%以上[3],無法再處理新的連接。從上述分析中可以看出,由于受硬件資源的限制,硬件系統(tǒng)" title="硬件系統(tǒng)">硬件系統(tǒng)可以支持的最大連接數(shù)小于代理服務器。但是在實際的網(wǎng)絡傳輸過程中,一個HTTP連接持續(xù)的時間一般為幾百個毫秒,在硬件系統(tǒng)達到每秒21K的連接數(shù)時,能夠承受的一個HTTP最大持續(xù)時間為13秒,遠遠大于實際HTTP連接的持續(xù)時間,因此硬件系統(tǒng)支持的最大連接數(shù)是夠用的。當代理服務器采用千兆網(wǎng)卡來接收數(shù)據(jù)時,由于數(shù)據(jù)需要經(jīng)過上層協(xié)議解析,因此實際能夠接收的數(shù)據(jù)量只能夠達到300Mbps。假設每次平均請求512B,則代理服務器能夠支持的最大每秒連接數(shù)大約為7K;而當硬件系統(tǒng)工作在133MHz,內(nèi)部采用32bit總線傳輸時,整個系統(tǒng)的帶寬達到4Gbit,同時系統(tǒng)內(nèi)部采用流水線方式,能夠線速處理1Gbps數(shù)據(jù)的接收,假設平均每次請求512B,則硬件系統(tǒng)能夠處理的每秒最大連接數(shù)達到21K,因此在單位時間內(nèi)能夠處理的連接數(shù)量會高于代理服務器。
隨著HTTP訪問量的不斷增大,對于訪問數(shù)據(jù)包的分流粒度要求越來越細。本文提出的基于硬件實現(xiàn)的TCP粘合系統(tǒng),在TCP粘合技術的基礎上,利用硬件的高速處理特性,可以達到2個GE口收發(fā)(2Gbps)的線速處理性能。同時能夠較好地基于內(nèi)容來區(qū)分數(shù)據(jù)流,從而避免了后端服務器數(shù)據(jù)的重新分發(fā)。
參考文獻
1 Cohen A,Rangarajan S,Slye H.On the performance of TCP splicing for URL-aware redirection.In:USENIX symposium on Internet technologies and systems,1999
2 Rosu M,Ros D.An evaluation of TCP splice benefits in web proxy servers.In:International world wide web conference,2002
3 Jacobson V.A high-Performance TCP/IP implementation gigabit per second TCP workshop.Corporation for National Research Initiatives(CNRI),1993
4 謝希仁.計算機網(wǎng)絡.北京:電子工業(yè)出版社,2003