
摘 要: 針對目前眾多計算機安全機構(gòu)所使用的計算機漏洞信息的現(xiàn)狀和存在問題,提出了開源漏洞庫批量下載、權(quán)威漏洞庫查詢、信息搜索等漏洞信息自動獲取方法,對獲取的XML、HTML和文本結(jié)果文件進行信息抽取,實現(xiàn)了漏洞信息的多源融合。
關(guān)鍵詞: 漏洞;信息抽取;信息融合
安全漏洞信息作為計算機安全研究的基礎(chǔ)數(shù)據(jù),是各種計算機安全事件處理的數(shù)據(jù)來源。目前,多個從事計算機安全研究的機構(gòu)和公司都配備了相應的計算機漏洞數(shù)據(jù)庫,但是由于采用的規(guī)范、標準等指標不同,這些漏洞數(shù)據(jù)庫結(jié)構(gòu)和內(nèi)容差異較大,對漏洞屬性的描述也存在很大差別(甚至互相矛盾),使得各個組織之間難以就漏洞信息進行交互和共享。此外,互聯(lián)網(wǎng)上發(fā)布的漏洞信息多為原始描述信息,從網(wǎng)上手工查找下載最新公布的漏洞信息,要加以提取、整理、驗證、入庫,費時費力。因此,一般情況下自建漏洞庫的數(shù)據(jù)更新速度跟不上新漏洞信息的發(fā)布速度,嚴重影響了其效能的發(fā)揮。
為了解決這些問題,信息工程大學的孫學濤等提出了通用脆弱點數(shù)據(jù)庫的構(gòu)建方法和標準[1];美國海軍研究生院的ARNOLD A D等人指出,網(wǎng)上沒有一個漏洞數(shù)據(jù)庫的信息是完善的,應當從網(wǎng)上多途徑獲取漏洞信息建立關(guān)系數(shù)據(jù)庫并進行挖掘[2];國家計算機網(wǎng)絡入侵防范中心的王曉甜描述了安全漏洞自動收集系統(tǒng)的設計與實現(xiàn)[3];西安電子科技大學楊曉彥提出了一種漏洞信息收集和發(fā)布機制[4]。
本文在進一步分析廣大用戶對漏洞信息越來越高的要求和繼承前人研究的基礎(chǔ)上,開展網(wǎng)絡化條件下通用漏洞信息獲取、處理方法和流程的研究,以期建立更加統(tǒng)一、完整、規(guī)范、可直接為計算機安全研究服務的漏洞數(shù)據(jù)來源。
1 漏洞信息的獲取策略
為了確保漏洞信息的權(quán)威性和準確性,必須慎重選擇信息來源。在本課題研究中,以國際漏洞統(tǒng)一CVE標號為標識,國際權(quán)威漏洞數(shù)據(jù)庫中的信息為主體,其他途徑獲得的信息為補充,建立漏洞信息獲取、處理、維護和使用的體系,如圖1所示。

1.1 開源漏洞數(shù)據(jù)庫批量下載
本課題對漏洞信息的獲取,主要來源于網(wǎng)絡批量下載。目前,由于各種原因,提供漏洞數(shù)據(jù)直接下載的組織只有美國國家標準與技術(shù)委員會的國家漏洞數(shù)據(jù)庫NVD和美國安全組織創(chuàng)建的開源漏洞數(shù)據(jù)庫OSVDB。
(1)NVD(National Vulnerability Database)[5]
NVD是美國國家標準與技術(shù)委員會NIST(National Institute of Standards and Technology)的計算機安全資源中心CSRC(Computer Security Resource Center)所創(chuàng)建的,提供的漏洞信息內(nèi)容比較簡練,目前收錄有CVE編號的漏洞數(shù)量達到37 301條,包含9條漏洞屬性,分別是:CVE編號、易受攻擊的系統(tǒng)號、影響的軟件列表、發(fā)布時間、最后修改時間、CVSS相關(guān)屬性、CWE編號、參考信息、漏洞摘要等。目前提供XML文件形式的漏洞信息下載,數(shù)據(jù)庫的下載頁面為:http://nvd.nist.gov/download.cfm。
(2)OSVDB(Open Source Vulnerability Database)[6]
OSVDB目標是在安全漏洞方面為全世界免費提供準確、詳細和公正的技術(shù)信息。該漏洞庫收集了在操作系統(tǒng)、軟件、協(xié)議和硬件設施以及信息技術(shù)基礎(chǔ)組織部分的幾乎所有漏洞。收錄各種漏洞數(shù)量達到54 686條,包含漏洞描述、分類信息、解決方案、影響的系統(tǒng)、相關(guān)信息、來源、博客信息、注釋信息等8條漏洞屬性。目前提供XML格式漏洞信息下載,但需要注冊。
1.2 權(quán)威漏洞數(shù)據(jù)庫查詢
國際上部分權(quán)威漏洞庫出于商業(yè)目的,對普通用戶只提供在線查詢,這些數(shù)據(jù)庫包括:美國計算機應急響應組US-CERT,安全焦點Security Focus;ISS公司的X-Force;Cerias公司的漏洞庫等。由于NVD和OSVDB中下載的漏洞屬性較少,遠遠適應不了網(wǎng)絡的需求,還需要從以上漏洞數(shù)據(jù)庫里得到補充和完善,即通過對個別漏洞信息進行在線查詢,將結(jié)果補充到相關(guān)漏洞信息。要實現(xiàn)漏洞信息的自動下載,必須解決兩個問題:查詢表單的自動填寫和提交;查詢結(jié)果的自動獲取和下載。
(1)表單的自動填寫和提交
目前,大多數(shù)漏洞網(wǎng)站提供的漏洞信息查詢采用input表單,如圖2所示。用戶填寫查詢表單發(fā)送請求,瀏覽器在后臺將數(shù)據(jù)post到目標網(wǎng)址,并獲取響應數(shù)據(jù)。因此,只要獲取瀏覽器中post的數(shù)據(jù)內(nèi)容和目標網(wǎng)址,就可以用程序?qū)崿F(xiàn)表單的自動填寫和提交。獲取post的內(nèi)容和目標網(wǎng)址通過抓包實現(xiàn)。目前常用工具有Ultra Network Snuffer等,自動提交可以通過許多編程工具中集成的網(wǎng)絡接口來實現(xiàn),如.Net Framework中的HttpWebRequest()函數(shù)等。

<form name=“Form1” method=“post” id=“Form1”>
<input name=“SearchInfo” type=“text” id=“SearchInfo”/>
<input type=“submit” name=“Submit” value=“search” id=“Submit”/>
</form>
(2)查詢結(jié)果的獲取
查詢結(jié)果的獲取是使用程序自動獲得服務器對post信息處理以后的返回結(jié)果,同樣可以通過編程工具中集成的網(wǎng)絡接口來實現(xiàn)。為了完整展示從漏洞網(wǎng)站自動化的查詢某一條漏洞信息并獲取查詢結(jié)果的過程。如,假定postData為post的信息內(nèi)容,url為post的目標地址。
byte[] data=encoding.GetBytes(postData);
HttpWebRequest request=(HttpWebRequest)WebRequest.Create(url);//準備請求…
request.Method=“POST”;//設置方法為post;
Stream outstream=request.GetRequestStream();
outstream.Write(data,0,data.Length);
HttpWebResponse response=(HttpWebResponse)request.
GetResponse();//發(fā)送請求;
Stream instream=response.GetResponseStream();
StreamReader sr=new StreamReader(instream);//返回結(jié)果
string content=sr.ReadToEnd();//結(jié)果存入content;
1.3 其他獲取途徑
除了上述漏洞信息獲取途徑以外,還可以借助于其他途徑來獲取:
(1)大型軟件廠商公司的門戶網(wǎng)站(如Microsoft、Cisco、Adobe等)會及時公布其軟件產(chǎn)品新發(fā)現(xiàn)的漏洞信息并提供解決方案,通過這些信息可以了解新漏洞部分屬性。
(2)借助于對Baidu、Google等知名搜索引擎,重點在論壇、郵件列表、新聞組等網(wǎng)站,對所要了解的漏洞進行搜索。
(3)通過購買較完備的漏洞數(shù)據(jù)庫(如國內(nèi)應用最廣泛的綠盟漏洞數(shù)據(jù)庫),直接獲取現(xiàn)有的結(jié)果,避免大量無意義的重復研究。
實踐證明,根據(jù)實際情況,靈活應用多種漏洞信息獲取手段和策略,可以取得更好的收集結(jié)果。
2 漏洞信息的處理技術(shù)
由于漏洞信息的獲取來源不同,所獲取的漏洞信息有XML文件、網(wǎng)頁文件以及其他非結(jié)構(gòu)化文本等,其結(jié)構(gòu)、內(nèi)容和所包含的信息量差別很大,對收集的原始漏洞信息的有效處理,并根據(jù)一定的屬性篩選規(guī)則自動存入漏洞數(shù)據(jù)庫中極為重要。漏洞信息處理可分為信息抽取和信息融合。
2.1 漏洞信息抽取技術(shù)
信息抽取是從大量結(jié)構(gòu)化和非結(jié)構(gòu)化的數(shù)據(jù)中,抽取出感興趣的信息內(nèi)容,形成結(jié)構(gòu)化的記錄。
2.1.1 XML文件信息抽取
XML是可擴展的(eXtensible)標記語言,它允許根據(jù)所提供的規(guī)則制定各種標記。該文檔描述了漏洞CVE-2009-0281的ID、影響軟件、發(fā)布時間等屬性。從漏洞庫下載的XML文件片段如下。
<entry id=“CVE-2009-0281”>
<vuln:cve-id>CVE-2009-0281</vuln:cve-id>
-<vuln:vulnerable-software-list>
<vuln:product>cpe:warhound:walking_club</vuln:product>
</vuln:vulnerable-software-list>
<vuln:published-datetime>2009-01-27T13:30:00.360-05:00
</vuln:published-datetime>
</entry>
對屬性信息的抽取主要用到了載入函數(shù)xmldoc.load()、讀取函數(shù)SelectSingleNode()和條目內(nèi)容屬性InnerText。
2.1.2 HTML文件信息抽取
對所獲取的HTML頁面的抽取有2種方法:(1)首先進行去噪處理,然后將網(wǎng)頁代碼格式化成XML形式的文件,用XPath提取出感興趣的漏洞信息,常用工具有Chris Lovett的SgmlReader和Simon Mourier的.NET HTML Agility Pack等,該方法最終回歸到XML抽取。(2)直接對網(wǎng)頁源代碼進行模式識別和字符串匹配。根據(jù)關(guān)鍵字和關(guān)鍵詞匹配,找出屬性名(如圖中“發(fā)布時間”);根據(jù)字體大小、顏色等不同(如圖中的粗體),對屬性名和屬性內(nèi)容進一步區(qū)分和驗證,如圖3所示。

此外,針對同一個網(wǎng)站所生成動態(tài)網(wǎng)頁具有相同結(jié)構(gòu)的特點,提前定義相對應的抽取模式,對該站所有頁面按照抽取模式進行抽取,可以有效提高識別準確度。
2.1.3 文本信息抽取
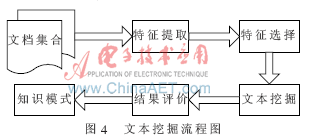
上文提到的抽取策略僅適用于結(jié)構(gòu)化和半結(jié)構(gòu)化的信息,對于經(jīng)由其他途徑獲取的信息,如黑客站點、軟件廠商網(wǎng)站、或論壇上對部分漏洞信息的描述,歸于非結(jié)構(gòu)化信息,以普通文本為主要格式,要從中獲取有價值的信息主要用到文本挖掘技術(shù)。文本挖掘?qū)儆跀?shù)據(jù)挖掘的一部分,通過對文本信息的分類、聚類采用一定的挖掘算法,自動找出文本中所蘊含的漏洞屬性,文本挖掘流程如圖4所示。
2.2 漏洞信息融合技術(shù)
數(shù)據(jù)融合技術(shù)是利用計算機對不同途徑獲取的各種信息源,在一定準則下加以自動分析、綜合,以完成所需的決策和評估任務而進行的信息處理技術(shù)。本文中使用數(shù)據(jù)融合技術(shù)來處理從網(wǎng)上獲取和抽取后存儲在本地的大量原始和多源的漏洞信息。主要流程包括結(jié)構(gòu)分析、規(guī)范化、去重、補缺、沖突處理等。
2.2.1 結(jié)構(gòu)分析
通常情況下,從原始漏洞信息中抽取的結(jié)果往往在總體結(jié)構(gòu)、數(shù)據(jù)構(gòu)成上很不統(tǒng)一。如xfocus漏洞庫描述了13條漏洞屬性,而綠盟漏洞庫只有8條。即使描述漏洞的同一屬性,采用的字段也可能不同,如NVD中對漏洞的特征描述屬性名為summary,而OSVDB中則為Description。因此,必須對所抽取的漏洞信息進行結(jié)構(gòu)分析,提煉出框架模型,自動地識別出漏洞信息描述的具體內(nèi)容,將采取不同命名的同一漏洞屬性盡可能對應起來,便于下一步的處理。
2.2.2 規(guī)范化
規(guī)范化是對采用不同標準描述的漏洞信息進行統(tǒng)一。規(guī)范化需要解決3個問題:(1)標準獲取。識別出各個組織對同一漏洞屬性描述上所采用的不同標準。(2)標準比較。根據(jù)各所采用標準的評定規(guī)則,比較各自的評定側(cè)重點和優(yōu)缺點。(3)標準選取和轉(zhuǎn)換。根據(jù)對漏洞信息的要求,選擇或者制定出最切合實際使用的標準,并對采用其他標準描述的信息進行轉(zhuǎn)換。例如,在安全漏洞的危害級別評定中,目前主要的評定方式有3種:(1)以微軟、FrSIRT等為代表的“高、中、低”等常見的評定方法;(2)以US-CERT為代表,使用數(shù)值表示漏洞級別;(3)目前正在普及的CVSS(Common Vulnerability Severity System)漏洞評級標準[4]。3種標準各有利弊,必須經(jīng)過判斷比較,確定適合研究的評定方法。
2.2.3 冗余和補缺
冗余是規(guī)范化以后的漏洞信息中包含對同一屬性的多個相同或相似描述:(1)不同漏洞庫的描述造成的冗余,合理選取所有冗余中一項即可;(2)多個漏洞庫對同一個漏洞屬性的不同命名造成實質(zhì)內(nèi)容上的冗余,需要對屬性命名的相似性做以判斷,然后進行篩選。
補缺處理是對于所有漏洞數(shù)據(jù)庫中都沒有描述或沒有確定描述的某個漏洞屬性,通過一定的方法合理補充。補缺處理通常有如下方法:(1)根據(jù)同一軟件中與該漏洞相似的漏洞的對應屬性,推測出該屬性最可能的值;(2)通過人工搜索或?qū)嶒灥玫浇Y(jié)果,進行補充;(3)暫時保留,等待別人的研究結(jié)果出來以后再進行補充。
2.2.4 沖突處理
數(shù)據(jù)沖突是對某一漏洞的同一屬性來自不同數(shù)據(jù)庫的多個描述互相矛盾。對于某些關(guān)鍵屬性,應當做出合理取舍。比如對同一條漏洞CVE-2006-1301,NVD漏洞數(shù)據(jù)庫給出的危害級別為高危級;而FrSIRT漏洞數(shù)據(jù)庫給出的危害級別為低級,因此需要做以判斷。在屬性沖突處理中,可以采取如下方案:(1)按照多條沖突信息來源漏洞庫的權(quán)威性、準確性等信息,制定各自權(quán)值,選擇權(quán)值最大、即最可能、可靠的值;(2)取多條描述的均值,即使偏離正確值,也不會太大;(3)人工參與決策,通過實際驗證或其他方法確定該屬性。
本文從計算機安全漏洞信息的需求,介紹了漏洞信息的獲取策略,從信息抽取和數(shù)據(jù)融合的角度探討了對通過不同來源獲取的原始和多源漏洞信息的處理流程。本課題的工程研究成果,可以直接應用于計算機安全研究上,為各種需求的用戶提供標準統(tǒng)一的、最新的、全面的漏洞信息,提高其對安全情況處理的能力,并提高處理結(jié)果的時效性和可信度。
參考文獻
[1] 孫學濤,李曉秋,謝余強.通用脆弱點數(shù)據(jù)庫的構(gòu)建[J].計算機應用,2002,22(9):42-44.
[2] ARNOLD A D, HYLA B M, ROWE N C. Automatically building an information-security vulnerability database[J]. US Naval Postgraduate Sch. Monterey, CA. Information Assurance Workshop[C], IEEE. 2006:376-377.
[3] 王曉甜,張玉清.安全漏洞自動收集系統(tǒng)的設計與實現(xiàn)[J].計算機工程,2006,32(20):177-179.
[4] 楊曉彥.網(wǎng)絡安全信息系統(tǒng)的研究[D].西安:西安電子科技大學,2007.
[5] National Vulnerability Database[DB/OL].http://nvd.nist.gov,2008.
[6] Open Source Vulnerability Database[DB/OL].http://www.osvdb.org,2009.