
摘 要: 為了更加智能地檢測(cè)離群點(diǎn),克服傳統(tǒng)離群點(diǎn)檢測(cè)算法的機(jī)械性,提升多維數(shù)據(jù)集合離群點(diǎn)挖掘效率,在傳統(tǒng)的離群數(shù)據(jù)挖掘算法的基礎(chǔ)上,提出了一種基于人工神經(jīng)網(wǎng)絡(luò)的多維離群點(diǎn)檢測(cè)算法。仿真實(shí)驗(yàn)結(jié)果表明,該算法具有對(duì)用戶依賴性小、檢測(cè)精度高的優(yōu)點(diǎn),為檢測(cè)離群點(diǎn)提供了一種新的路徑。
關(guān)鍵詞: 人工神經(jīng)網(wǎng)絡(luò);多維數(shù)據(jù);智能化;熵權(quán)
離群點(diǎn)(Outlier)就是明顯偏離其他數(shù)據(jù)、不滿足數(shù)據(jù)的一般模式或行為、與存在的其他數(shù)據(jù)不一致的數(shù)據(jù)[1]。離群點(diǎn)檢測(cè)的目的在于從海量數(shù)據(jù)中找出具有明顯異常行為的數(shù)據(jù)。離群點(diǎn)的檢測(cè)應(yīng)用于多個(gè)行業(yè),如通信盜用、網(wǎng)絡(luò)病毒檢測(cè)、疾病診斷等方面。目前有一些高效的離群點(diǎn)檢測(cè)挖掘算法,比如基于統(tǒng)計(jì)的、 距離的、深度的、密度的方法,參考文獻(xiàn)[2]-[6]中較為詳細(xì)地介紹了這些方法和各自的局限性。
這些傳統(tǒng)方法雖然有時(shí)針對(duì)各自的檢測(cè)對(duì)象具有良好性能,但是前提是必須對(duì)數(shù)據(jù)集有很深入的了解,比如用基于統(tǒng)計(jì)的方法,需要預(yù)先知道數(shù)據(jù)集屬于什么分布。這些傳統(tǒng)方法沒(méi)有智能挑選的能力,不會(huì)從復(fù)雜數(shù)據(jù)集中找出潛藏的規(guī)則。如有一組數(shù)據(jù)A=[1 2 4 8 15 32],如果按照基于距離的離群點(diǎn)檢測(cè)方法檢測(cè),最有異常行為的數(shù)據(jù)是32,但是如果經(jīng)過(guò)訓(xùn)練與預(yù)測(cè),可發(fā)現(xiàn)15這個(gè)點(diǎn)在這里才具有最異常的行為。因此,找出數(shù)據(jù)集中潛在的規(guī)則是很有現(xiàn)實(shí)意義的。人工神經(jīng)網(wǎng)絡(luò)使得解決這一問(wèn)題變成了一種可能。
高維空間點(diǎn)的數(shù)據(jù)特性決定了其檢測(cè)與低維數(shù)據(jù)集有很大的區(qū)別。首先,與低維空間不同的是高維空間中的數(shù)據(jù)分布比較稀疏,造成高維空間中數(shù)據(jù)之間的距離尺度及區(qū)域密度不再具有直觀的意義[7]。從一個(gè)數(shù)據(jù)點(diǎn)來(lái)看,其他點(diǎn)到它的距離落在一個(gè)范圍很小的區(qū)間內(nèi),很難給出一個(gè)合適的近似度閾值來(lái)確定哪些點(diǎn)與它相似,哪些點(diǎn)不是。另外,對(duì)高維數(shù)據(jù)的估計(jì)需要的樣本個(gè)數(shù)與維數(shù)構(gòu)成指數(shù)增加的關(guān)系,這在機(jī)器學(xué)習(xí)中稱作著名的維數(shù)災(zāi)難(Curse of Dimensionality)。大量的數(shù)據(jù)分析問(wèn)題本質(zhì)上是非線性的,甚至是高度非線性,對(duì)此不能利用已有的快速成熟的線性模型進(jìn)行研究[8]。
因此引入熵權(quán)的概念,通過(guò)它能知道每個(gè)屬性對(duì)于離群點(diǎn)的貢獻(xiàn)程度,較好地解決了非線性問(wèn)題,而且分開(kāi)對(duì)于每個(gè)屬性值進(jìn)行預(yù)測(cè),然后做一個(gè)統(tǒng)計(jì)求和,對(duì)于位于維數(shù)災(zāi)難有了較好的解決。
1 相關(guān)工作
1.1 人工神經(jīng)網(wǎng)絡(luò)
人工神經(jīng)網(wǎng)絡(luò)(ANN)是一種應(yīng)用類似于大腦神經(jīng)突觸連接的結(jié)構(gòu)進(jìn)行信息處理的數(shù)學(xué)模型[9]。ANN是一個(gè)由大量簡(jiǎn)單的處理單元組成的高度復(fù)雜的大規(guī)模非線性自適應(yīng)系統(tǒng)[10]。它是對(duì)巨量信息并行處理和大規(guī)模平行計(jì)算的基礎(chǔ),既是高度非線性的動(dòng)力學(xué)系統(tǒng),又是自適應(yīng)組織系統(tǒng),可用來(lái)描述認(rèn)知、決策及控制的智能行為。對(duì)于處理大量原始數(shù)據(jù)而不能用規(guī)則或公式描述的問(wèn)題,ANN則表現(xiàn)出極大的靈活性和自適應(yīng)性。
1.2 BP神經(jīng)網(wǎng)絡(luò)的基本結(jié)構(gòu)以及工作范式
BP網(wǎng)絡(luò)是誤差反向傳播神經(jīng)網(wǎng)絡(luò)的簡(jiǎn)稱,由輸入層、隱含層、輸出層組成。每一層由一個(gè)或多個(gè)神經(jīng)元組成。隱含層可以包括BP網(wǎng)絡(luò)的結(jié)構(gòu),如圖1所示。
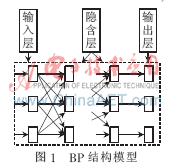
BP神經(jīng)網(wǎng)絡(luò)的輸入層接收輸入樣本信息,隱含層對(duì)輸入信息進(jìn)行處理,輸出層負(fù)責(zé)處理后的結(jié)果。如果輸出層結(jié)果與預(yù)測(cè)值有誤差或者誤差大于給定閘值,則網(wǎng)絡(luò)將誤差反向通過(guò)輸出層傳遞給隱含層,經(jīng)過(guò)隱含層處理后,傳遞給輸入層,期間相鄰網(wǎng)絡(luò)層之間的連接權(quán)值經(jīng)過(guò)多次的權(quán)值修正。由此通過(guò)多次傳輸與反向傳輸,相鄰層之間的連接權(quán)值通過(guò)不斷修正,從而將誤差控制到給定閘值范圍之內(nèi),至此,學(xué)習(xí)結(jié)束。權(quán)值不斷調(diào)整的過(guò)程就是網(wǎng)絡(luò)學(xué)習(xí)的過(guò)程。BP神經(jīng)網(wǎng)絡(luò)最直接的優(yōu)點(diǎn)就是與大腦認(rèn)知具有一定的相似性,如容錯(cuò)性、學(xué)習(xí)能力、非線性等。
1.3 相關(guān)定義與公式
定義1 rji稱為第j個(gè)對(duì)象在i個(gè)屬性上的值,且rji∈[0,1],則在n個(gè)對(duì)象d維屬性中,第i維屬性的熵定義為:


2 算法描述及偽代碼
本文算法(BAOA)將所選數(shù)據(jù)分為訓(xùn)練數(shù)據(jù)和檢測(cè)數(shù)據(jù)(預(yù)測(cè)數(shù)據(jù))。算法將訓(xùn)練數(shù)據(jù)當(dāng)做全部非離群點(diǎn)進(jìn)行訓(xùn)練而找出隱藏規(guī)則,然后將這規(guī)則應(yīng)用于檢測(cè)數(shù)據(jù)的預(yù)測(cè)。所選訓(xùn)練數(shù)據(jù)通常占全部數(shù)據(jù)比率為8.5~11.5%左右(此時(shí)數(shù)據(jù)量也比較大),這樣既可以保證訓(xùn)練的有效性(找出隱藏規(guī)則),同時(shí)又能保證丟失掉的訓(xùn)練數(shù)據(jù)中的離群點(diǎn)(如果存在)對(duì)于全部離群點(diǎn)來(lái)說(shuō)影響又不大。該算法除在訓(xùn)練點(diǎn)數(shù)據(jù)個(gè)數(shù)的選取上較為新穎且有實(shí)際意義外,而且中間加入判定有無(wú)預(yù)測(cè)值的算法,對(duì)于沒(méi)有預(yù)測(cè)值的數(shù)據(jù)點(diǎn)賦予一個(gè)經(jīng)驗(yàn)值,這樣更能維持?jǐn)?shù)據(jù)監(jiān)測(cè)的穩(wěn)定性。
該算法首先對(duì)原始數(shù)據(jù)集中每一個(gè)屬性對(duì)應(yīng)的值進(jìn)行極差變換,然后計(jì)算每一個(gè)屬性的熵權(quán),而后對(duì)數(shù)據(jù)集中的訓(xùn)練數(shù)據(jù)的每一個(gè)非空間屬性按照順序排列后經(jīng)過(guò)所選人工神經(jīng)網(wǎng)絡(luò)模型進(jìn)行訓(xùn)練,然后對(duì)于剩下的所有數(shù)據(jù)(檢測(cè)數(shù)據(jù))的每一個(gè)屬性按照順序排序后經(jīng)過(guò)所選神經(jīng)網(wǎng)絡(luò)模型進(jìn)行預(yù)測(cè),然后經(jīng)過(guò)算法的判斷函數(shù),將沒(méi)有預(yù)測(cè)值的屬性值人工賦予一個(gè)預(yù)測(cè)值(在經(jīng)驗(yàn)波動(dòng)范圍內(nèi)),保證每個(gè)待檢測(cè)的數(shù)據(jù)點(diǎn)都有預(yù)測(cè)值。而后將預(yù)測(cè)值作為標(biāo)準(zhǔn)值,通過(guò)計(jì)算每一個(gè)屬性值自身的的偏差,再結(jié)合每一個(gè)屬性熵權(quán)對(duì)它進(jìn)行處理,得出每一個(gè)數(shù)據(jù)點(diǎn)的離群程度大小,最后按照離群程度從大到小的順序進(jìn)行排序。
3 仿真
仿真操作系統(tǒng)和軟件:win7-32、Matlab
仿真對(duì)象:葡萄酒識(shí)別數(shù)據(jù)
所選數(shù)據(jù)描述:所選數(shù)據(jù)來(lái)源于由C.Blake于1998年9月21日更新的數(shù)據(jù)集,它分為低中高三種,個(gè)數(shù)分別為63,1319,27。有12屬性,分別為:酒精、蘋(píng)果酸、灰、鎂、總酚類、黃酮、Nonflavanoid酚類、原花色素、顏色強(qiáng)度、色相、0D280/0D315稀釋葡萄酒、脯氨酸。
所選ANN網(wǎng)絡(luò):BP網(wǎng)絡(luò)
輸入個(gè)數(shù)J:4
輸出個(gè)數(shù)K:1
隱含層個(gè)數(shù)Y:6
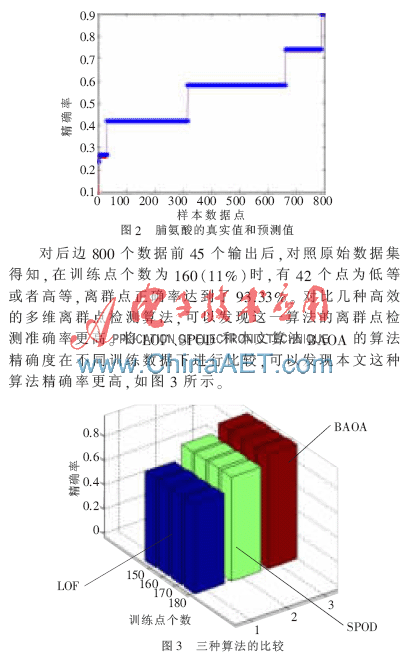
處理說(shuō)明:在訓(xùn)練和預(yù)測(cè)時(shí),每次都是對(duì)屬性值排序后進(jìn)行訓(xùn)練和預(yù)測(cè),這樣更容易找出隱藏規(guī)則,計(jì)算效率更高,預(yù)測(cè)效果更好。后s+1到n個(gè)數(shù)據(jù)點(diǎn)每個(gè)屬性預(yù)測(cè)時(shí),前J個(gè)作為輸入值時(shí),它沒(méi)有對(duì)應(yīng)的預(yù)測(cè)值。對(duì)此進(jìn)行的處理是此時(shí)賦予它一個(gè)合適的值(波動(dòng)大小在經(jīng)驗(yàn)范圍內(nèi)),此次仿真過(guò)程中是賦予一個(gè)和原始值一樣的值作為預(yù)測(cè)值。雖然后s+1到n個(gè)數(shù)據(jù)點(diǎn)每個(gè)對(duì)象按照每個(gè)屬性每次排序后對(duì)應(yīng)的前J個(gè)值id不一樣,但是因?yàn)閿?shù)據(jù)海量,且維數(shù)較多,這樣處理后對(duì)于離群點(diǎn)的預(yù)測(cè)并無(wú)大的影響。圖2為后800個(gè)葡萄酒樣本中脯氨酸的屬性值的真實(shí)值和預(yù)測(cè)值。
本文針對(duì)高維空間中數(shù)據(jù)的特點(diǎn),提出了一種智能找出隱藏規(guī)則并且自動(dòng)檢測(cè)離群點(diǎn)的算法。對(duì)于多維復(fù)雜且對(duì)離群點(diǎn)特征沒(méi)有明顯約束的數(shù)據(jù)集,ANN表現(xiàn)出了它的優(yōu)越性。仿真結(jié)果表明, 通過(guò)ANN建立的多維離群點(diǎn)檢測(cè),具有傳統(tǒng)方法無(wú)可比擬的智能性,而且檢測(cè)精度較高。為各位離群點(diǎn)檢測(cè)相關(guān)專業(yè)人員和業(yè)務(wù)愛(ài)好者提供了一種思路。
參考文獻(xiàn)
[1] HAWKINS D M. Identification of outliers[M]. London: Chapman and Hall, 1980.
[2] HAN J, KAMBER M, PEI J. Data mining: concepts and techniques[M]. Morgan kaufmann, 2006.
[3] WANG L, ZOU L. Research on algorithms for mining distance based outliers[J]. Chinese Journal of Electronics, 2005, 14(3) :384-387.
[4] SHEKHAR S, LU C T, ZHANG P. A unified approach to detecting spatial outliers[J]. GeoInformatica, 2003, 7(2): 139-166.
[5] AGGARWAL C C, YU P S. Finding generalized projected clusters in high dimensional spaces[M]. ACM, 2000.
[6] 魏藜,宮學(xué)慶,錢(qián)衛(wèi)寧,等.高維空間中的離群點(diǎn)發(fā)現(xiàn)[J].軟件學(xué)報(bào),2002,13(2):280-290.
[7] SHEKHAR S, LU C T, ZHANG P. A unified approach to detecting spatial outliers[J]. GeoInformatica, 2003, 7(2): 139-166.
[8] 傅薈璇,趙紅.MATLAB神經(jīng)網(wǎng)絡(luò)應(yīng)用設(shè)計(jì)[M].北京:機(jī)械工業(yè)出版社,2010.
[9] 鐘義信.知識(shí)理論與神經(jīng)網(wǎng)絡(luò)[M].北京:清華大學(xué)出版社,2009.
[10] 閔劍.人工神經(jīng)網(wǎng)絡(luò)在石化項(xiàng)目績(jī)效評(píng)價(jià)中的應(yīng)用研究[D].北京:清華大學(xué),2009.