
文獻標識碼: A
文章編號: 0258-7998(2013)08-0137-03
在日常生活中,人們一直都在和數(shù)據(jù)信息打交道。數(shù)據(jù)信息組織和保存的方式很多,最常用的方式就是把數(shù)據(jù)信息保存在某種文件中,然后將文件上傳到FTP服務器[1]。但是當用戶要對文件進行操作時,查找文件會顯得比較麻煩。本文提出通過數(shù)據(jù)庫直接記錄并管理這些文件中的數(shù)據(jù)信息[2],通過數(shù)據(jù)庫的SQL語句對相關的記錄進行增刪查改,操作起來非常便捷,而且在數(shù)據(jù)庫中可以采用集群的技術,為用戶提供高可靠性的服務。基于Oracle數(shù)據(jù)庫的上傳下載軟件實現(xiàn)的主要功能是將一些文件寫入到數(shù)據(jù)庫,實現(xiàn)文件的上傳;然后再將數(shù)據(jù)庫中的內(nèi)容讀出,實現(xiàn)文件的下載。
本文設計不僅實現(xiàn)了文件的上傳和下載,還針對一些較大文件的上傳提出了一種分塊上傳的思想。先指定用戶想要的文件塊的大小,這個值決定了文件要被分割的塊數(shù),較大的文件分割成若干塊,每塊都以一條記錄的形式寫到數(shù)據(jù)庫中。當某條記錄寫數(shù)據(jù)庫失敗時,只需將那些寫數(shù)據(jù)庫失敗的文件塊重新上傳,不需要將整個文件重新上傳。采用這種方式可以提高文件上傳的效率,節(jié)約重新上傳時寫數(shù)據(jù)庫的時間。但下載時,如果用戶需要完整的原始文件,原來屬于同一個文件的分塊則需要重新寫到一個文件中。本文使用邊下載、邊合并的方法,實現(xiàn)了分塊文件的合并下載。用戶可以根據(jù)自己的需要,針對性地下載其中的部分文件塊。讀取一個文件分塊相比讀一個完整的大文件要快很多,文件的分塊與合并提高了文件的上傳下載效率。值得注意的是,在設置文件分塊時,分塊的大小要適度,否則會影響軟件的運行效率[3],用戶可以根據(jù)實際要求設置文件分塊的大小。
1 大文件分塊上傳和下載軟件的實現(xiàn)
1.1 文件的分塊
將一個較大的文件上傳到數(shù)據(jù)庫時,上傳速度往往會受到網(wǎng)絡寬帶的影響。針對較大文件的保存與管理,需對其進行分塊,可以根據(jù)網(wǎng)絡的帶寬設置文件塊的大小,假設每個文件上傳的時間不超過5 s,設帶寬為k Mb/s,文件塊的大小BlockSize可以設置的范圍最好能夠滿足式(1):
(5×k/8)MB<BlockSize<(5×10×k/8)MB (1)
若文件塊的大小用BlockSize表示,則文件分成的塊數(shù)nCount與文件的大小之間的關系為:
nCount=Flength/BlockSize+1 (2)
K=Flength%BlockSize (3)
其中Flength代表原始文件的大小,K代表最后一個文件分塊的大小。因為文件的大小與文件塊的大小不一定剛好是整除的關系。最特殊的情況就是某文件的大小剛好小于文件塊的大小,此時的文件就只有一塊,即該文件本身。
1.2 分塊文件的上傳
將分塊文件上傳到數(shù)據(jù)庫之前,首先要在數(shù)據(jù)庫中創(chuàng)建一個存儲文件信息表,并定義相關的字段,方便用戶查詢和管理[4]。數(shù)據(jù)庫表中主要的相關字段包括:文件編號、文件名、文件大小、基本路徑、相對路徑、文件塊大小、文件塊編號、文件類型、文件內(nèi)容等。
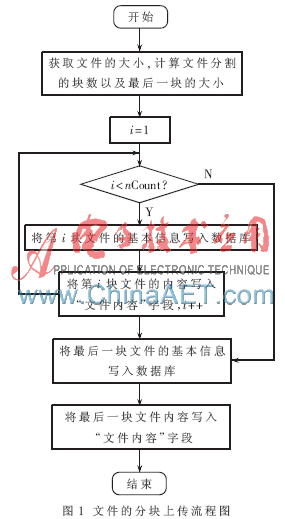
文件上傳到數(shù)據(jù)庫主要步驟為:(1)將文件的名稱、路徑、大小、類型等基本信息寫入數(shù)據(jù)庫;(2)根據(jù)這些基本信息查找對應的記錄,并將文件的內(nèi)容寫到blob字段中,文件內(nèi)容以二進制的形式存貯在數(shù)據(jù)庫中[5-6]。
文件分塊上傳時,首先連接服務器端的數(shù)據(jù)庫,在數(shù)據(jù)庫連接成功的條件下,遍歷要上傳的文件所在的路徑。當查找到要上傳的文件時,根據(jù)文件分塊的大小,計算文件分割的塊數(shù)和最后一個文件塊的大小,從第一個文件塊開始,計算過程如下:
(1) 判斷是否成功連接到數(shù)據(jù)庫。
(2) 判斷這是否為最后一個文件塊,如果是,則從文件中讀取最后一個文件塊,寫入數(shù)據(jù)庫后結(jié)束;否則從文件中讀取BlockSize個字節(jié)。
(3) 用Insert命令在對應的表中寫入文件的編號、文件名稱、文件大小、文件的基本路徑及相對路徑、文件類型、文件塊的大小和編號。
(4) 通過文件編號、文件路徑,文件名稱和文件塊編號查找相應的記錄。
(5) 將要寫入數(shù)據(jù)庫的文件內(nèi)容保存在一個安全數(shù)組中,并調(diào)用AppendChunk()函數(shù)將該塊文件內(nèi)容填到對應的blob字段當中,并更新記錄。
(6)為寫入記錄中的文件的路徑、文件名以及文件塊編號設置標記,方便重新上傳時定位斷點的位置,跳轉(zhuǎn)到步驟(1)。
文件分塊上傳的流程圖如圖1所示。
如果服務器數(shù)據(jù)庫與客戶端的連接斷開,將導致文件上傳失敗。在客戶端與服務器端數(shù)據(jù)庫重新建立連接后,需要續(xù)傳文件,同時要通過斷開數(shù)據(jù)庫時的標記,找到上次上傳文件的斷點。
續(xù)傳文件時,為了找到文件續(xù)傳的起始位置,依然要遍歷文件所在的路徑,通過文件路徑和名稱找到對應的文件,再使用文件塊的編號和文件塊的大小獲取下一次文件要上傳的位置。設offset為文件指針的偏移值,BlockNo為文件塊的編號,BlockSize為文件塊的大小,三者之間的關系如下:
offset=BlockNo×BlockSize (4)
式中,被標記文件塊的編號BlockNo乘以文件塊的大小BlockSize,就是續(xù)傳時讀取文件的偏移值。通過這個方法,就可以找到斷點所在的文件塊位置,實現(xiàn)文件的續(xù)傳, 從而避免重新上傳之前已經(jīng)寫入數(shù)據(jù)庫的文件塊。
1.3 分塊文件的下載
因為文件是保存在數(shù)據(jù)庫中的,用戶可用通過SQL命令對數(shù)據(jù)庫中的記錄進行增刪查改等操作,這比存儲在FTP服務器中的文件處理要方便很多。下載的過程其實就是上傳的逆過程,思想相似。
下載時根據(jù)相關的查詢條件,如果存在符合條件的記錄,即可對這些記錄保存的文件進行下載,在成功連接到數(shù)據(jù)庫的條件下,從第一條記錄開始執(zhí)行以下過程:
(1)判斷是否成功連接到數(shù)據(jù)庫。
(2)判斷該記錄是否超過最后一條記錄編號,如果是,下載結(jié)束;否則跳轉(zhuǎn)到步驟(3)。
(3)從記錄中獲取文件的類型、文件名以及相對路徑,判斷該文件是否已經(jīng)存在,如果不存在,則根據(jù)文件的類型創(chuàng)建一個文件,以可追加的形式打開文件。
(4)調(diào)用GetChunk()函數(shù)獲取blob字段中的內(nèi)容,并保存在一個安全數(shù)組中,最后將安全數(shù)組中的數(shù)據(jù)寫入文件。
(5)關閉文件,并標記該記錄中的文件路徑、文件名以及文件塊編號,并跳轉(zhuǎn)到步驟(1)。
1.4 分塊文件的合并
本文雖然實現(xiàn)了文件的分塊下載,但是在實際情況中,人們通常希望使用完整的文件,而不是一個文件塊,所以在下載的過程中需要將各個文件的分塊重新合并成一個文件。本文采用的方法是在下載的過程中即可進行合并操作,文件合并下載的流程圖如圖2所示。
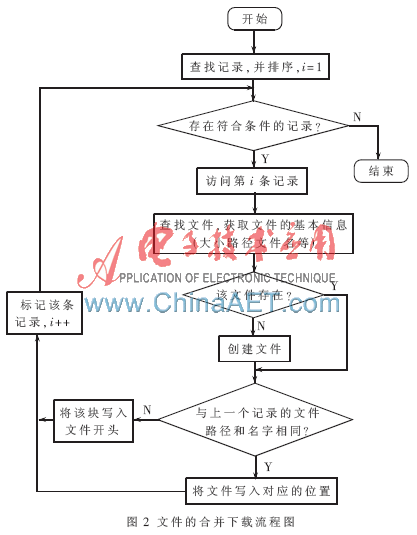
文件的合并是文件合并下載過程中的一部分,即每次下載某條記錄中的文件內(nèi)容時,先判斷該文件塊將寫入的文件。
用戶根據(jù)文件名稱,文件路徑等信息查找所需要的文件,如果存在符合條件的記錄,就依次訪問這些記錄,并將每條記錄中的文件內(nèi)容讀取出來,寫入相應的文件中。從查詢到的第一條記錄開始:
(1)判斷是否已經(jīng)訪問了最后一條符合條件的記錄,如果是,則結(jié)束,否則轉(zhuǎn)到步驟(2)。
(2)獲取文件的路徑、文件名稱、文件類型等基本信息, 判斷當前路徑下是否已經(jīng)存在這樣的文件,如果不存在,將創(chuàng)建一個對應的文件;否則跳轉(zhuǎn)到步驟(3)。
(3)將記錄中的文件相對路徑、文件名兩個字段的內(nèi)容與上一條記錄中的相對路徑和文件名匹配,如果相同,則將文件內(nèi)容追加到該文件;否則根據(jù)該文件塊的基本信息重新創(chuàng)建一個文件。
(4)標記該條記錄并移到下一條記錄,并跳轉(zhuǎn)到步驟(1)。
所有記錄被訪問完的同時,所有的文件分塊都被寫入了相應文件中,既不會出現(xiàn)文件內(nèi)容的覆蓋問題,也不會額外地占用存儲空間。
2 實驗分析
通過測試發(fā)現(xiàn),文件的完整上傳所消耗的時間最短,但是上傳失敗后要重新上傳整個文件。如果使用文件的分塊上傳,文件分塊的大小要適當,分塊越多,上傳的速度就越慢。因為記錄每個分塊文件的基本信息也要消耗一定的時間,在上傳失敗需要重新上傳的情況下,只需上傳剩下的沒有上傳成功的文件,效率有所提高。在下載的過程中,單塊文件明顯比整個文件的下載要快,因為單塊文件下載只需要讀取塊數(shù)據(jù)。而文件的合并下載時間比整塊文件下載時間要長,因為在合并的過程中要判斷各個文件塊是否來源于同一個原始文件,會消耗一定的時間。
相對于普通的將文件上傳到FTP服務器,本文實現(xiàn)了基于Oracle數(shù)據(jù)庫的大文件分塊上傳下載應用軟件,將文件的內(nèi)容以二進制的形式分散保存在Oracle數(shù)據(jù)庫中,這不僅可以對大量數(shù)據(jù)信息進行管理,還可以使得不同的用戶共享很多數(shù)據(jù)信息。文件的分塊上傳采用文件分割技術,將文件分塊保存在數(shù)據(jù)庫中。通過文件的續(xù)傳,避免了由于各種網(wǎng)絡原因?qū)е碌膶憯?shù)據(jù)庫操作失敗,需要將整個文件重新上傳的問題。文件的合并下載解決了同一個文件中不同分塊的合并問題,避免了先下載文件再進行合并的做法,提高了軟件的運行效率。
參考文獻
[1] 馮素梅.基于FTP的文件上傳與下載研究[J].北京電力高等專科學校學報(自然科學版),2010,27(5):197-199.
[2] 陶宏才.數(shù)據(jù)庫原理及設計[M]. 北京:清華大學出版社,2007.
[3] 張翼.BLOB數(shù)據(jù)優(yōu)化算法及其應用[J].計算機測量與控制,2011(6):1478-1480.
[4] 徐孝凱,賀桂英.數(shù)據(jù)庫基礎與SQL Server應用開發(fā)[M].北京:清華大學出版社,2008.
[5] 謝華成,張昆朋,范黎林,等.基于文件分割的二進制大對象存取算法[J].計算機應用,2011,31(10):2612-2616.
[6] 趙宇峰,張燁.VC存取數(shù)據(jù)庫的BLOB類型的方法[J].微型電腦應用,2007,23(3):59-60.