
摘 要: 通過研究各種決策樹分類算法的并行方案后,并行設(shè)計C4.5算法,。同時根據(jù)Hadoop云平臺的MapReduce編程模型,,詳細描述C4.5并行算法在MapReduce編程模型下的實現(xiàn)及其執(zhí)行流程。最后,,對輸入的海量文本數(shù)據(jù)進行分類,,驗證了算法的高效性和擴展性。
關(guān)鍵詞: 云計算,;Hadoop,;MapReduce;數(shù)據(jù)分類,;C4.5算法,;并行
隨著信息技術(shù)的高速發(fā)展,人們積累的數(shù)據(jù)量急劇增長,,如何從海量數(shù)據(jù)中提取有用的知識成為當(dāng)務(wù)之急,。數(shù)據(jù)挖掘應(yīng)運而生,它是一個從大量的,、不完全的,、有噪聲的、模糊的,、隨機的實際應(yīng)用數(shù)據(jù)中,,提取隱含在其中的人們事先不知道的但又是潛在有用的信息和知識的過程[1]。然而隨著數(shù)據(jù)量的增加,,數(shù)據(jù)挖掘處理海量數(shù)據(jù)的能力成為了不可忽視的問題,。
云計算是解決這個問題的有效途徑,它把大量高度虛擬化的資源管理起來,,組成一個大的資源池,,用來統(tǒng)一提供服務(wù),。云計算是最近幾年出現(xiàn)的一門新興技術(shù),是并行計算,、分布式計算、網(wǎng)格計算的發(fā)展[2],,具有廣泛的應(yīng)用前景,。IBM、Google,、微軟等眾多公司都很重視云計算技術(shù),,都快速推出了自己的云計算平臺。目前比較熱門的開源云計算平臺有:Abiquo公司的abiCloud,、Amazon公司的Eucalyptus,、MongoDB、Enomalism,、Nimbus,、Hadoop。其中Hadoop平臺是完全模仿Google體系架構(gòu)做的一個開源項目,,是現(xiàn)在應(yīng)用最廣,、最成熟的平臺。
決策樹分類算法作為一個經(jīng)典的數(shù)據(jù)挖掘方法,,通過對大量數(shù)據(jù)的屬性值進行分析,,構(gòu)造決策樹,來發(fā)現(xiàn)數(shù)據(jù)中蘊涵的分類規(guī)則,。然而,,在數(shù)據(jù)增長大爆炸的時代,這些算法處理海量數(shù)據(jù)的性能總有些差強人意,。云計算作為一個處理海量數(shù)據(jù)的良好途徑,,將算法布置在云計算平臺中進行分布式計算是一個行之有效的方法。
本文采用Hadoop開源云平臺,,對數(shù)據(jù)集進行數(shù)據(jù)橫向和縱向劃分,,分布到不同的節(jié)點對不同的屬性進行并行處理,對海量文本數(shù)據(jù)進行分類,。
1 Hadoop開源云平臺
Hadoop是Apache軟件基金會旗下的一個開源分布式平臺,,以Hadoop分布式文件系統(tǒng)HDFS和MapReduce(Google MapReduce的開源實現(xiàn))為核心,為用戶提供了系統(tǒng)底層細節(jié)透明的分布式基礎(chǔ)架構(gòu)[3],。HDFS的高容錯性,、高伸縮性等優(yōu)點允許用戶將Hadoop部署在低廉的硬件上,MapReduce分布式編程模型允許用戶在不了解分布式系統(tǒng)底層細節(jié)的情況下開發(fā)并行應(yīng)用程序,。因此用戶可以充分利用集群的計算和存儲能力,,完成海量數(shù)據(jù)的處理。
1.1 分布式文件系統(tǒng)HDFS
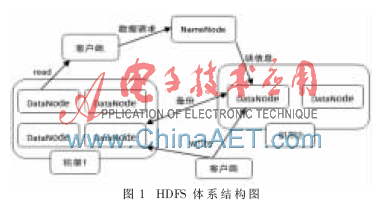
HDFS采用了主從(Master/Slave)結(jié)構(gòu)模型,一個HDFS集群由一個NameNode和若干個DataNode組成,。其中NameNode作為主服務(wù)器,,管理文件系統(tǒng)的命名空間和客戶端對文件的訪問操作;集群中的DataNode管理存儲的數(shù)據(jù),。HDFS允許用戶以文件形式存儲數(shù)據(jù),。從內(nèi)部來看,文件被分成若干個數(shù)據(jù)塊,,而且這若干個數(shù)據(jù)塊存放在一組DataNode上[3],。NameNode執(zhí)行文件系統(tǒng)的命名空間操作,如打開,、關(guān)閉,、重命名文件或目錄等,也負責(zé)數(shù)據(jù)塊到具體DataNode的映射,。DataNode負責(zé)處理文件系統(tǒng)客戶端的文件讀寫請求,,并在NameNode的統(tǒng)一調(diào)度下進行數(shù)據(jù)塊的創(chuàng)建、刪除和復(fù)制工作,。圖1所示為HDFS的體系結(jié)構(gòu),。
1.2 并行編程框架MapReduce
Hadoop上的并行應(yīng)用程序開發(fā)基于MapReduce編程框架,框架由一個單獨運行在主節(jié)點上的JobTracker和運行在每個集群從節(jié)點的TaskTracker共同組成,。它的原理是:利用一個輸入的key/value對集合來產(chǎn)生一個輸出的key/value對集合,。用戶用Map和Reduce兩個函數(shù)來表達計算[3]。
用戶自定義的Map函數(shù)接收一個輸入的key/value對,,然后產(chǎn)生一個中間key/value對的集合,。MapReduce把所有具有相同key值的value集合在一起,然后傳遞給Reduce函數(shù),。自定義的Reduce函數(shù)接收key和相關(guān)的value集合,,合并這些value值,形成一個較小的value集合,。
圖2為MapReduce的數(shù)據(jù)流圖,,這個過程簡而言之就是將大數(shù)據(jù)集分集為成百上千個小數(shù)據(jù)集,每個或若干個小數(shù)據(jù)集分別由集群中的一個節(jié)點進行處理并生成中間結(jié)果,,然后這些中間結(jié)果又由大量的節(jié)點合并,,形成最終結(jié)果。此框架下并行程序中需要3個主要函數(shù):Map,、Reduce,、Main。在這個結(jié)構(gòu)中,,需要用戶完成的工作僅僅是根據(jù)任務(wù)編寫Map和Reduce兩個函數(shù),。

2 C4.5決策樹分類算法
在決策樹分類算法中,,最常用、最經(jīng)典的是C4.5算法,,它繼承了ID3算法的優(yōu)點并對ID3算法進行了改進和補充,。此算法描述如下[4]:
(1)預(yù)處理樣本數(shù)據(jù)集。若存在連續(xù)取值的屬性變量,,則將其進行離散化,,形成決策樹的訓(xùn)練集;若不存在則忽略此步,。
①根據(jù)原始數(shù)據(jù),分別找到該連續(xù)型屬性的最小取值a0和最大取值an+1,;
②在區(qū)間[a0,,an+1]內(nèi)插入n個數(shù)值,將其等分為n+1個小區(qū)間,;
③分別以ai(i=1,,2,…,,n)為分段點,,將區(qū)間[a0,an+1]劃分為兩個子區(qū)間:[a0,,ai],,[ai+1,an+1],,對應(yīng)該連續(xù)型屬性變量的兩類取值,,有n種劃分方式。
(2)計算每個屬性的信息增益和信息增益率,。
①計算屬性A的信息增益Gain(A),;
②計算屬性A的信息增益率GainRatio(A)。對于取值連續(xù)的屬性,,以ai(i=1,,2,…,,n)為分割點計算相應(yīng)分類的信息增益率,,選擇最大信息增益率對應(yīng)的ai作為該屬性分類的分割點。而后選擇信息增益率最大的屬性作為當(dāng)前的屬性節(jié)點,,得到?jīng)Q策樹的根節(jié)點,。
(3)根節(jié)點屬性的每一個取值對應(yīng)一個子集,對樣本子集遞歸執(zhí)行步驟(2),,直到劃分的每個子集中的數(shù)據(jù)在分類屬性上取值都相同,,或者沒有剩余屬性可以進一步劃分數(shù)據(jù),,或者給定的分支中沒有數(shù)據(jù),便停止劃分,,生成決策樹,。
(4)根據(jù)生成的決策樹提取分類規(guī)則,對新的數(shù)據(jù)集進行分類,。
3 C4.5算法并行化
本文結(jié)合數(shù)據(jù)橫向和縱向劃分方法,,以提高并行效率。具體設(shè)計思想如下:
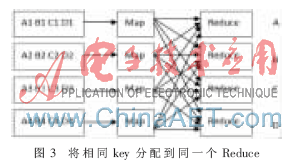
Map階段:主要任務(wù)是處理輸入的1/M訓(xùn)練樣本集,,掃描每條記錄,,將其格式化為<key,value>對,。具體格式為key=屬性S,,value=<對應(yīng)屬性S的值s,所屬類別c,,原表中此記錄的id>,。格式化后即可進行Map操作,每個Map任務(wù)為劃分歸類具有相同key的鍵值對,,寫到相應(yīng)文件,,由partition用模計算將各個文件分配到指定的Reduce上,即將相同的key分配到同一個Reduce節(jié)點上,,如圖3所示,。
Reduce階段:主要任務(wù)是處理Map輸出的<key,value>鍵值對,。對于具有連續(xù)值的屬性,,先從小到大排序?qū)傩灾担芍狈綀D,,用來記錄該屬性對應(yīng)記錄的類分布,,初始化為0,每個Reduce任務(wù)都計算分割點的信息增益率,,并及時更新直方圖,。對于離散的屬性,不需要排序,,也無需更新直方圖,,第一次掃描數(shù)據(jù)Map的輸出記錄時,生成相對應(yīng)的直方圖,,計算各子節(jié)點的信息增益率,。每個Reduce節(jié)點都將計算得到各自屬性列的信息增益率和分裂點,根據(jù)分裂點分割屬性列表,,用列表的索引號生成記錄所在節(jié)點的哈希表,,存儲分裂點兩側(cè)的數(shù)據(jù)記錄,。哈希表格式為<key,value>鍵值對,,value=<樹節(jié)點號NodeID,,當(dāng)前樹節(jié)點號的子節(jié)點號SubNodeID>,其中SubNodeID為0表示左節(jié)點,,1表示右節(jié)點,。哈希表中的第N條記錄表示原數(shù)據(jù)中第N條記錄所劃分到的樹節(jié)點號。最后根據(jù)哈希表各分節(jié)點對其他屬性列表進行分割,,并生成屬性直方圖,。
主程序算法設(shè)計描述如下:
Main()
{
輸入訓(xùn)練樣本集T;
生成有序的屬性列表A和直方圖G;
創(chuàng)建節(jié)點隊列Q,首節(jié)點N為訓(xùn)練樣本集所有數(shù)據(jù)
記錄;
while(隊列不為空)
{
取出隊列首節(jié)點,;
while(節(jié)點數(shù)據(jù)樣本不屬于同一類&&還有屬性
可操作&&樣本數(shù)據(jù)不是太少)
{
將節(jié)點中的訓(xùn)練樣本集進行水平劃分,,分割為
M份,由InputFormat完成,,將數(shù)據(jù)劃分為InputSplit發(fā)
送到各個Map節(jié)點進行處理,這里同時也進行垂直
分割;
Map操作;
Reduce操作,,以Map節(jié)點的輸出中間結(jié)果作為
輸入;
根據(jù)各個Reduce節(jié)點返回的輸出結(jié)果,,選擇最
大信息增益的屬性,以其分裂點和哈希表分裂原始數(shù)
據(jù)集,,生成子節(jié)點N1和N2,,放入隊列Q;
}
}
}
例如,以ALLElectronic顧客數(shù)據(jù)為訓(xùn)練集,,Hadoop默認參數(shù)進行分片,,其中水平和垂直分割過程如圖4所示。
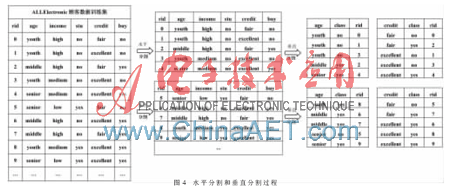
對ALLElectronic顧客數(shù)據(jù)集進行分類,,顧客數(shù)據(jù)集的屬性分別為ID,、年齡、收入水平,、學(xué)生身份標(biāo)志,、信用卡水平。根據(jù)這些屬性對顧客消費潛力進行評估,,將顧客分為會消費顧客和不會消費顧客,,訓(xùn)練產(chǎn)生的決策樹模型如圖5所示,用此模型對數(shù)據(jù)進行分類,。

4 實驗
本實驗主要驗證算法的高效性和擴展性,。實驗數(shù)據(jù)為UCI數(shù)據(jù)集Bank Marketing,用來預(yù)測用戶是否會定期存款,。該數(shù)據(jù)集屬于商業(yè)領(lǐng)域,,具有多變量的特征,,包括客戶的年齡、工作,、婚姻情況,、學(xué)歷、年均收入,、房貸,、支出等17個屬性,而且是實數(shù),,有45 211個元組,,沒有缺省值,經(jīng)常用來完成分類的任務(wù),。
實驗環(huán)境:軟件方面:采用Hadoop-0.20.2版本,,Ubuntu Linux 9.04系統(tǒng),Eclipse3.3.2開發(fā)工具,,Jdk 7.0,;(上接第87頁)
硬件方面:7臺PC(其中1臺作為主機,其他6臺作為從機),,每臺PC的配置為:CPU i3,,內(nèi)存1 GB,網(wǎng)卡100 Mb/s,。
實驗內(nèi)容:采用復(fù)制的手段將Bank Marketing擴大,,產(chǎn)生分別為100 MB、200 MB,、400 MB,、700 MB、1 GB大小的數(shù)據(jù)集,。測試各個數(shù)據(jù)集在不同數(shù)量的集群中算法的運行時間,,從機集群數(shù)量分別設(shè)為1、2,、4,、6臺。運行結(jié)果統(tǒng)計如圖6所示,。

數(shù)據(jù)的處理時間主要花費在數(shù)據(jù)的分割和記錄的格式化過程,,由圖6可見,隨著集群數(shù)量的增大,處理時間有效地縮短了,。具體原因分析如下:MapReduce對數(shù)據(jù)的分割一般以64 MB為一基本單位,。例如,700 MB大小的數(shù)據(jù)可分割為11個數(shù)據(jù)塊,如果用1臺機器去處理,,需要計算11次,;用2臺處理,需要計算6次,;4臺處理則只要計算3次,;6臺則只要計算2次。因此可以得出此算法有很高的高效性和擴展性,。
決策樹分類算法有廣泛的應(yīng)用領(lǐng)域,,如客戶關(guān)系管理、專家系統(tǒng),、語音識別,、模式識別等。C4.5并行化決策樹分類算法與傳統(tǒng)決策樹分類算法相比,,有較大優(yōu)勢,,可以支持海量數(shù)據(jù)的處理。同時將其運行在Hadoop云計算平臺上,,能夠高效地對大規(guī)模海量數(shù)據(jù)進行分類,。
參考文獻
[1] 房祥飛.基于決策樹的分類算法的并行化研究及應(yīng)用[D]. 濟南:山東師范大學(xué),2007.
[2] 劉鵬.云計算[M].北京:電子工業(yè)出版社,,2010.
[3] 陸嘉恒.Hadoop實戰(zhàn)[M].北京:機械工業(yè)出版社,,2011.
[4] 田金蘭,趙慶玉.并行決策樹算法的研究[J].計算機工程與應(yīng)用,,2001,,16(5):17-20.