
文獻標(biāo)識碼: A
文章編號: 0258-7998(2013)01-0040-03
音視頻編碼標(biāo)準(zhǔn)(AVS)是我國具有知識產(chǎn)權(quán)的第二代信源編碼標(biāo)準(zhǔn)[1]。近年來,AVS解碼器發(fā)展較為成熟,已有較多的國內(nèi)外企業(yè)生產(chǎn)解碼芯片。但是,AVS編碼器還未發(fā)展到令人滿意的程度,在一定程度上限制了AVS的推廣。運動估計在AVS編碼器中主要用于消除時間冗余,以使視頻編碼達到更高的壓縮率。然而,其運算量巨大,占整個視頻編碼的60%左右。所以,在面積和功耗限制下設(shè)計專門的運動估計硬件結(jié)構(gòu)成為當(dāng)前研究熱點。
AVS整像素運動估計的搜索算法很多,其中全搜索塊匹配算法因數(shù)據(jù)流規(guī)則匹配率高并且沒有復(fù)雜的動態(tài)反饋和決策邏輯,最適合可變塊大小運動估計,故本文選擇全搜索塊匹配算法。現(xiàn)有的全搜索塊匹配算法運動估計硬件結(jié)構(gòu)在面積及處理速度上已做了很多努力,如參考文獻[2-5]提出的實現(xiàn)方案:參考文獻[2]利用像素截斷的方法,將像素低位截斷,在保證圖像信噪比降低不多的情況下大大減少了運算量;參考文獻[3]提出了二維intra-Level SAD計算陣列的運動估計結(jié)構(gòu),在列方向上數(shù)據(jù)重用率可達到100%;參考文獻[4]和[5]提出的結(jié)構(gòu)能夠?qū)崿F(xiàn)100%的硬件處理器利用率,但是均存在I/O帶寬大的缺點。本文根據(jù)AVS整像素運動估計的特點,采用二維內(nèi)置SAD加法樹計算陣列,通過合理安排片上存儲,極大地降低了I/O帶寬;運用了加1電路選擇進位加法器,進一步縮小了結(jié)構(gòu)面積,提高了處理速度,實現(xiàn)了適用于AVS的高性能整像素運動估計硬件設(shè)計。
1 AVS運動估計算法
1.1 可變塊運動估計
基于塊的運動估計,即找到當(dāng)前幀的塊在參考幀中一定范圍內(nèi)最匹配的塊所在的相對位置,這個相對位置稱為運動矢量。AVS標(biāo)準(zhǔn)中規(guī)定將16×16的宏塊進一步劃分為8×16、16×8、8×8的子塊,如圖1所示,這樣能夠提供更加精確的運動矢量預(yù)測。可變塊運動估計需要對每個宏塊的所有子塊進行塊匹配,即進行9次計算。本文采用如圖2所示的加法樹結(jié)構(gòu),所有的大塊由小塊簡單相加即可,大大減少了計算量[4]。


2 AVS整像素運動估計硬件設(shè)計
2.1 像素截斷
由參考文獻[2]可知,適當(dāng)?shù)貙ο袼氐牡臀粩?shù)據(jù)進行截斷,并不影響整個運動估計的結(jié)果。本文采用的方法并不是真正截斷數(shù)據(jù),而是利用“與門”將輸入像素的低3位變?yōu)?,以減少運算量,降低功耗。
2.2 內(nèi)置SAD加法樹計算陣列
要實現(xiàn)高性能全搜索可變塊運動估計的硬件結(jié)構(gòu),需要滿足資源利用率高、PE個數(shù)少、I/O帶寬低等條件。本文采用參考文獻[3]提出的在計算陣列中內(nèi)置加法樹的方法。計算陣列由8×8個處理單元(PE)及二維加法樹組成,如圖3所示。采用二維陣列結(jié)構(gòu)提高了硬件資源的利用率;將當(dāng)前像素儲存在陣列寄存器中,不需要反復(fù)讀入當(dāng)前像素,PE個數(shù)由宏塊大小決定,不隨著搜索窗大小變化而變化;參考像素存儲在移位寄存器組中,每個移位寄存器存儲9個像素值,配合蛇形移動的數(shù)據(jù)傳輸方式,如圖4所示,參考塊數(shù)據(jù)輸入經(jīng)過初始的8個移動周期后,寄存器組中正好存放著一個參考塊的像素值,之后的每次移動,寄存器組中的數(shù)據(jù)只需更新一行新的數(shù)據(jù),而有7行數(shù)據(jù)是與上一個參考塊共享的, 這樣能實現(xiàn)列方向100%的數(shù)據(jù)重用率,有效地減少了I/O帶寬。整個設(shè)計結(jié)構(gòu)有4個這樣的計算陣列,只需在開始計算時等待25個周期,以后的每個周期計算陣列都將輸出整個8×8塊的SAD值,保證了數(shù)據(jù)讀入過程中的時鐘不被浪費。


2.3 進位選擇加法器
通過上文介紹的結(jié)構(gòu)可知,每個計算陣列需要使用大量的加法器。當(dāng)計算小塊SAD值時,不僅需要得到當(dāng)前像素和一個參考像素的差的絕對值,而且需要累加整個塊的絕對差值;當(dāng)計算大塊SAD值時,又需要將小塊SAD值進行累加。大量的加法器嚴重影響計算陣列的面積和處理速度,故本設(shè)計對加法器進行了改進。目前已有設(shè)計選擇使用超前進位流水線加法器,其處理速度雖然提高了很多,但是大量并行處理占用了比普通加法器更多的資源。由于進位選擇加法器比普通加法器處理速度快,占用的資源比超前進位加法器少,所以本設(shè)計選擇進位選擇加法器。
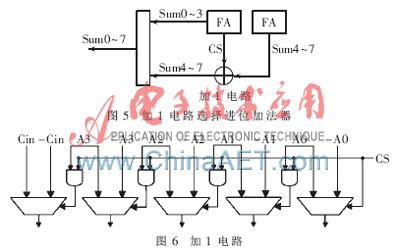
傳統(tǒng)的進位選擇加法器使用兩個相同的行波法加法器計算高位的值,兩個行波法加法器分別假設(shè)進位為0和1并同時進行計算,等待正確的進位到來時,再選擇正確的結(jié)果輸出。這樣雖然可以縮短等待時間,但是占用面積較大。本文采用加1電路的選擇進位加法器,如圖5所示。高位加法器以固定進位為0進行計算。若正確進位為0,則加1電路不必進行計算,直接輸出結(jié)果;若正確的進位為1,則將此結(jié)果加1,得到進位為1的結(jié)果。加1電路如圖6所示,其中CS表示低位進位。如此,計算陣列的面積和功耗將會降低很多,處理速度也較快。
2.4 存儲器設(shè)計
由于當(dāng)前像素直接存放在陣列寄存器中,所以不需要設(shè)計緩沖器。考慮到參考塊一共有47×47個像素,且每個周期需要配合計算陣列蛇形輸入數(shù)據(jù),因此采用片上RAM來緩存參考數(shù)據(jù)。將參考塊分為6個區(qū)域,每個區(qū)域大小為8×47個像素,用RAM0~RAM5來標(biāo)識,如圖7所示。設(shè)計使用雙端口RAM,利用奇偶地址,讓32 bit雙端口RAM相當(dāng)于64 bit單端口RAM。由于相鄰宏塊的搜索區(qū)域重疊部分占整個搜索塊的三分之二,按照本文的存儲器設(shè)計,當(dāng)進行下一個宏塊的運動估計時,不需要更新整個參考塊的數(shù)據(jù),只需更新其中兩個區(qū)域的數(shù)據(jù)即可,進一步減少了存儲帶寬,提高了數(shù)據(jù)的重用率。

3 仿真和結(jié)構(gòu)分析
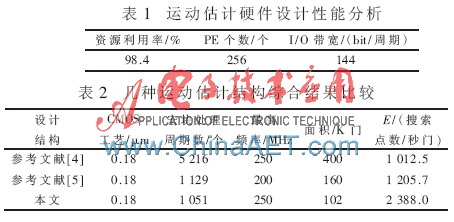
本文提出了一種適用于AVS的高性能整像素運動估計硬件設(shè)計,使用了Verilog HDL語言進行RTL級描述,用AVS軟件RM52j的C程序產(chǎn)生測試碼流,應(yīng)用了Modelsim 6.5c仿真平臺進行了邏輯功能的仿真驗證。采用Synopsys的Design Compiler在SMIC 0.18 ?滋m CMOS工藝庫下綜合,在最大頻率為250 MHz時,門數(shù)為102 K(未包括存儲器面積)。表1給出了運動估計硬件設(shè)計性能分析,這表明本文所設(shè)計的結(jié)構(gòu)具有高性能、低帶寬的優(yōu)勢。表2將本文提出的結(jié)構(gòu)與其他幾種運動估計結(jié)構(gòu)進行了比較,其中引用了效率E作為一個重要的比較參數(shù),E為結(jié)構(gòu)每秒處理的搜索點數(shù)和實際面積的比值,具體公式見參考文獻[5]。通過比較可以看出,本設(shè)計與參考文獻[5]的設(shè)計均可實現(xiàn)對高清圖像的實時處理,但本設(shè)計的最快時鐘頻率提升了25%,面積減小了36.2%,效率提高了98%。
本文針對AVS視頻標(biāo)準(zhǔn),提出了一種適用于AVS的高性能整像素運動估計硬件設(shè)計。采用二維內(nèi)置SAD加法樹計算陣列,通過合理的安排片上存儲,優(yōu)化了加法器設(shè)計,大大提高了結(jié)構(gòu)的性能。實驗結(jié)果表明,本設(shè)計電路規(guī)模為102 K門,處理一個宏塊只需要1 051個時鐘周期,能夠以2 388.0搜索點數(shù)/秒門的效率對高清圖像進行運動估計。與同類設(shè)計相比,本設(shè)計具有電路規(guī)模小、處理速度快、I/O帶寬低等優(yōu)勢。另外,本設(shè)計還可以作為IP核嵌入到特定的處理器中,對AVS高清視頻進行實時處理。
參考文獻
[1] GB/T20090.2-2006.信息技術(shù)先進音視頻編碼第二部分:視頻[S].2006.
[2] He Zhongli,LIOU M I.Reducing hardware complexity of motion estimation algorithms using truncated pixels[C]. Proceedings of IEEE International Symposium on Circuits and Systems,1997,4:2809-2812.
[3] CHEN C Y,CHIEN S Y,HUANG Y W,et al.Analysis and architecture design of variable block-size motion estimation for H.264/AVC[J].IEEE Transactions on Circuits and Systems,2006,53(3):578-593.
[4] Deng Lei,Xie Xiaodong,Gao Wen.A real-time full architecture for AVS motion estimation[J].IEEE Transactions on Consumer Electronics,2007,53(4):1744-1751.
[5] Cao Wei,Hou Hui,Tong Jiarong,et al.A high-performance reconfigurable VLSI architecture for VBSME in H.264[J]. IEEE Transactions on Consumer Electronics,2008,53(4):1338-1345.