
摘 要: HEVC作為下一代視頻編碼標(biāo)準(zhǔn),正在由JCT-VC制定。根據(jù)最新的HEVC中提出的歸并技術(shù),描述了B幀編解碼效率的改善。實(shí)驗(yàn)驗(yàn)證了運(yùn)動(dòng)歸并技術(shù)在低延遲低復(fù)雜度情況下對(duì)P幀的影響。通過HM6.0中運(yùn)動(dòng)歸并技術(shù)算法原理,分析運(yùn)動(dòng)歸并技術(shù)對(duì)于P幀在編解碼效率上并無明顯的提升,PSRN平均降低了0.1%。
關(guān)鍵詞: HEVC;MCL;歸并模型
雖然H.264/AVC[1]視頻編碼標(biāo)準(zhǔn)采用很多新的編碼方案,在現(xiàn)有的視頻編解碼取得了很好的編碼效果,但是它的編碼單元(CU)仍然固定為16像素×16像素的宏塊(MB),包含16個(gè)4像素×4像素或者8個(gè)8像素×8像素變換塊,然而在編碼器處理高分辨率的圖像時(shí),運(yùn)動(dòng)估計(jì)(ME)和運(yùn)動(dòng)補(bǔ)償(MC)與CU大小只有很小的相關(guān)性。因此,HEVC(High Efficiency Video Coding)[2]中,CU在16像素×16像素MB的基礎(chǔ)上進(jìn)行了擴(kuò)展,CU的大小可以為8像素×8像素、16像素×16像素、32像素×32像素和64像素×64像素,對(duì)CU的預(yù)測(cè),可以將CU分割為預(yù)測(cè)單元(PU),每個(gè)PU可以分割為更小的PU,假設(shè)CU大小為2N×2N(N=4,8,16,32),PU可以分割為2個(gè)N×2N或者2N×N或4個(gè)N×N像素塊,再分割為非對(duì)稱模式下,PU可以為nR×2N、nL×2N、2N×nDe和2N×nU。同樣,HEVC中處理變化和量化部分有相應(yīng)的變換單元(TU),TU可以為4像素×4像素、8像素×8像素、16像素×16像素和32像素×32像素。
歸并技術(shù)應(yīng)用于CU單元在作RDO運(yùn)算之前,用于快速?zèng)Q定CU的預(yù)測(cè)模型,其中的并行運(yùn)算可以降低HM編碼端吞吐量過大的問題,提高視頻編碼效率。參考文獻(xiàn)[3]提出了歸并技術(shù)對(duì)不同CU層編解碼效率的提升,由于8像素×8像素CU占據(jù)整體CU的54%,大塊CU的歸并技術(shù)的應(yīng)用,導(dǎo)致PSNK值有較大的下降。參考文獻(xiàn)[4]提出了只對(duì)8像素×8像素CU進(jìn)行歸并技術(shù)的應(yīng)用,并在B幀上得到了很好的效果,將像素的Y、U與V的BD-rate提升了0.1%、0.1%與0.1%,解碼時(shí)間平均降低了12%。在本文中,將檢測(cè)及驗(yàn)證歸并技術(shù)在低延遲情況下對(duì)P幀的影響,并分析P幀中歸并技術(shù)的并行運(yùn)算原理。
1 MCL的并行運(yùn)算
在決定CU編碼模型和獲取CU的編碼列表前,HEVC會(huì)對(duì)當(dāng)前CU做歸并運(yùn)算,提前決定CU的預(yù)測(cè)列表,然后才對(duì)每個(gè)CU作RDO運(yùn)算,選擇最佳的編碼模型。而RDO的運(yùn)算必須對(duì)當(dāng)前CU作運(yùn)動(dòng)估計(jì)運(yùn)算,HEVC編碼器中歸并候選列表(MCL)的獲取速度會(huì)影響ME的計(jì)算,HM5中每個(gè)PU都有自己的MCL,一個(gè)64像素×64像素的CU有539個(gè)MCL,嚴(yán)重阻礙了預(yù)測(cè)模型類型的確定。HM6中提出的MCL的并行運(yùn)算,不僅可以減少M(fèi)CL的數(shù)量,同時(shí)減少了CU內(nèi)部PU的相互依賴性。在不包含不對(duì)稱CU的情況下,對(duì)于一個(gè)64×64的CU,相鄰有5個(gè)參考位置可以使用,其又可以分為4個(gè)32像素×32像素的CU,同樣擁有5個(gè)參考點(diǎn),總共有4×5個(gè)參考點(diǎn)。同理,16像素×16像素的CU有4×4×5個(gè)參考點(diǎn),8像素×8像素的CU有16×4×5個(gè)參考點(diǎn),所以一個(gè)64像素×64像素大小的CU總共包含425個(gè)參考位置。在包含不對(duì)稱CU的情況下,參考點(diǎn)的數(shù)量可達(dá)593個(gè)[3]。這樣龐大的數(shù)量,加重了計(jì)算量,應(yīng)該試圖減少M(fèi)CL的數(shù)量,特別是8像素×8像素CU中MCL的數(shù)量。
歸并技術(shù)利用已編碼的PU來推導(dǎo)或獲取當(dāng)前PU的參數(shù)列表(如運(yùn)動(dòng)向量、參考幀索引、參考幀列表標(biāo)志等),在HM6中提出了基于CU的運(yùn)動(dòng)歸并列表的構(gòu)造,它是將位于一個(gè)CU中所有8像素×8像素大小的PU共享同一個(gè)MCL,這不僅降低了幀間PU的相互依賴性,還減少了MCL的數(shù)量,最多可達(dá)HM5中MCL的57%。這種設(shè)計(jì)使得視屏質(zhì)量平均損失了0.3%,但提高了高吞吐量和高質(zhì)量編碼器的靈活性。
當(dāng)N=4時(shí),當(dāng)前PU的TMVP參考索引從其左邊PU獲取,當(dāng)這兩個(gè)PU位于相同的CU中時(shí),就說這兩個(gè)PU具有依賴性。圖1列舉了PU依賴性的情況。
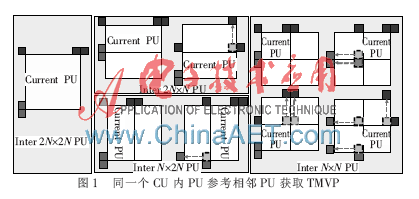
這種情況下,直到參考的PU編碼和解碼完成才能獲取當(dāng)前PU的TMVP,HM6中通過當(dāng)前CU之外已編碼的CU來獲取TMVP。TMVP參考索引的位置如圖2所示,其中位于CU內(nèi)部的PU,其TMVP參考索引被設(shè)置為A1,如果A1不可用,則把TMVP的參考索引設(shè)置為0。
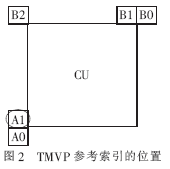
因?yàn)楫?dāng)前CU內(nèi)部的PU都參考同一個(gè)CU(A1),所以CU內(nèi)部PU的MCL的數(shù)量將會(huì)減少。對(duì)于CU中的不對(duì)稱PU,在去除PU間依賴性前,有13個(gè)參考點(diǎn),由于同一個(gè)CU內(nèi)部的PU采用同一個(gè)參考點(diǎn),因此對(duì)于一個(gè)64像素×64像素的PU只有一個(gè)參考點(diǎn)可以選擇(即A1)。同理,32像素×32像素共有4×13個(gè)參考點(diǎn),16像素×16像素共有4×4×13個(gè)參考點(diǎn),8像素×8像素共有16×4×1個(gè)參考點(diǎn),因此去除CU內(nèi)部PU的相互依賴性后,MCL的數(shù)量總共為397個(gè)。在包含不對(duì)稱PU的CU中,其他的參考點(diǎn)可以相應(yīng)求得。圖3表示MCL的獲取流程圖[4]。
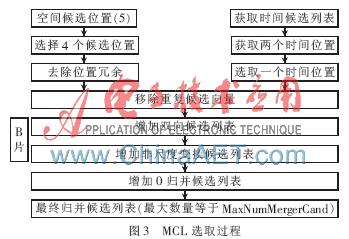
MCL的獲取需要考慮時(shí)間和空間上的候選參考點(diǎn)。在空間位置上,從當(dāng)前CU的5個(gè)候選參考點(diǎn)選擇其中4個(gè),選擇順序?yàn)锳1->B1->B0->A0->(B2),參考點(diǎn)B2只有在A1、B1、B0或A0無效時(shí)才可使用。在時(shí)間順序上,在當(dāng)前PU的POC值小的幀里選擇兩幀,從這兩幀與當(dāng)前PU相對(duì)應(yīng)的位置選擇兩個(gè)參考點(diǎn),然后通過比較選擇其中較好的參考點(diǎn)。最后從選擇的5個(gè)參考點(diǎn)中移除重復(fù)的參考點(diǎn),增加0歸并候選參考點(diǎn),得到MCL。
2 實(shí)驗(yàn)平臺(tái)與仿真結(jié)果分析
本文仿真采用JCTVC小組開發(fā)的HM6.0代碼,仿真平臺(tái)是CPU為3.30 GHz Intel CoreTM i3-2120、內(nèi)存為2 GB、操作系統(tǒng)為Windows XP的64位計(jì)算機(jī),運(yùn)行環(huán)境為Microsoft Visual Studio 2010。
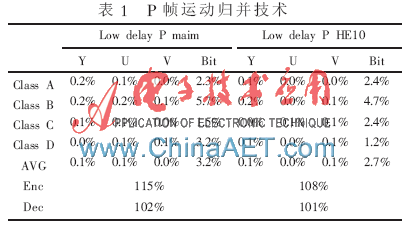
實(shí)驗(yàn)結(jié)果如表1所示,表中列出了運(yùn)動(dòng)歸并技術(shù)對(duì)于各類視頻P幀PSNR值、比特?cái)?shù)與編解碼時(shí)間的影響。P幀Y、U、V的PSNR值分別降低了0.1%、0.1%和0.1%,比特率平均提升了3%,編碼時(shí)間增加了10%。
視頻的PSNR平均值降低,編碼一幀比特?cái)?shù)增加,這是由于歸并技術(shù)在計(jì)算P幀時(shí)算法復(fù)雜度上升,使得在低延遲低復(fù)雜度配置文件下,P幀在8像素×8像素CU下需要額外的像素拷貝過程,使其運(yùn)算的復(fù)雜度上升,增加了P幀在運(yùn)動(dòng)歸并技術(shù)中的計(jì)算時(shí)間,影響了P幀的編解碼時(shí)間。
本文分析了PU相互依賴性的解決方案,相對(duì)于HM5,merge模型的歸并運(yùn)算很好地改善了編碼端視頻處理的吞吐量問題,降低了B幀的比特率,同時(shí)降低了B幀的解碼時(shí)間。由于歸并技術(shù)運(yùn)用于P幀的特殊性,今后可以改善P幀歸并技術(shù)的算法,使其達(dá)到同樣的效果,在降低視頻比特率的同時(shí),獲得較好的視頻質(zhì)量。歸并技術(shù)的并行運(yùn)算為HEVC編碼器的設(shè)計(jì)提出了更好的merge/skip模型決定,并且提供了更加靈活的設(shè)計(jì)方案。
參考文獻(xiàn)
[1] H.264 and ISO/IEC 14496-10. Advanced video coding for generic audiovisual services, ITU-T rec[S].
[2] BROSS B, HAN W J, OHM J R, et al. High efficiency video coding(HEVC) text specification draft 6. JCTVC-H1003, JCT-VC of ITU-T SG16 WP3 and ISO/IEC, CA, USA, 2012.
[3] Zhou Minhua. Configurable and CU-group level parallel merge/skip. JCTVC-H0082, JCT-VC of ITU-T SG16 WP3 and ISO/IEC, CA, USA, 2012.
[4] Yu Qin, Ma Siwei, Liu Hongbin, et al. Parallel AMVP candidate list constrction. JCTVC-I0036, JCT-VC of ITU-T SG16 WP3 and ISO/IEC, CA, USA, 2012.
[5] KIM H Y, CHO S H, LIM S C, et al. Throughput improvement for merge/skip mode. JCTVC-H0240, JCT-VC of ITU-T SG16 WP3 and ISO/IEC, CA, USA, 2012.
[6] MCCANN K, BROSS B, KIM I K, et al. High efficiency video coding(HEVC) test model 6 encoder description.JVTVC-H1002, JCT-VC of ITU-T SG16 WP3 and ISO/IEC, CA, USA, 2012.