
摘 要: 如何在各高校內(nèi)部成百上千個資源站點中,快速有效地查找到所需信息成為網(wǎng)絡(luò)用戶面臨的一個突出問題。為此提出了一款校內(nèi)搜索引擎軟件的設(shè)計,解決了當(dāng)前各高校大學(xué)生對本校信息難于快速有效獲取的問題。
關(guān)鍵詞: Java;校內(nèi);搜索引擎;設(shè)計
當(dāng)前,面對浩瀚的網(wǎng)絡(luò)資源,搜索引擎為所有網(wǎng)上沖浪的用戶提供了一個入口,所有的用戶都可以借助于搜索引擎到達自己想去的網(wǎng)上任何一個地方。隨著Internet的快速發(fā)展,海量信息和人們獲取所需信息能力之間的矛盾日益明顯,在信息海洋里查找信息,如同大海撈針一樣,而搜索引擎的出現(xiàn)正好解決了這一難題。
目前高校校內(nèi)信息量的不斷增加,面對浩瀚的網(wǎng)絡(luò)信息,選擇資源范圍廣而針對性不強,很難搜到符合自己的資源。針對這種情況,本文提出了一款校內(nèi)搜索軟件的設(shè)計與實現(xiàn)方法。該軟件采用Java語言開發(fā),是一款簡易且實用的校內(nèi)搜索引擎軟件。
1 設(shè)計原理
搜索引擎系統(tǒng)[1]通常是指互聯(lián)網(wǎng)信息檢索系統(tǒng)。本系統(tǒng)是建立在通過網(wǎng)絡(luò)爬蟲軟件抓取大量的網(wǎng)絡(luò)資源的基礎(chǔ)上進行開發(fā)設(shè)計的,系統(tǒng)通過對抓取的網(wǎng)頁文件進行智能提取、去標(biāo)注、內(nèi)容分析等處理,再經(jīng)過索引加載建立索引數(shù)據(jù)庫。用戶可以通過搜索頁面查詢索引數(shù)據(jù)庫,返回包含所有匹配查詢關(guān)鍵詞的網(wǎng)頁[2]。
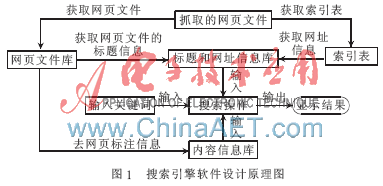
校內(nèi)搜索引擎軟件的設(shè)計原理如圖1所示,其原理如下:(1)通過網(wǎng)絡(luò)爬蟲軟件抓取網(wǎng)頁內(nèi)容;(2)從抓取的網(wǎng)頁文件中獲取索引表,索引表內(nèi)容為每個文件的序號與網(wǎng)址信息,得到網(wǎng)頁文件庫里面的內(nèi)容即為網(wǎng)頁文件;(3)對得到的網(wǎng)頁文件庫進行處理,使用正則表達式去除網(wǎng)頁標(biāo)注信息,得到的新內(nèi)容存放在一個新的文件夾中,作為內(nèi)容信息庫;(4)根據(jù)網(wǎng)頁文件庫和索引表,得到一個新的文件(也稱為標(biāo)題和網(wǎng)址信息庫),其里面的內(nèi)容為每個文件的序號、標(biāo)題和網(wǎng)址等信息;(5)當(dāng)用戶需要查找自己需要的信息時,只要輸入關(guān)鍵詞,搜索引擎軟件根據(jù)用戶輸入的關(guān)鍵詞在內(nèi)容信息庫中進行查找[3],如果內(nèi)容信息庫中存在用戶查找的內(nèi)容,軟件將根據(jù)給內(nèi)容所在的文件序號,在標(biāo)題和網(wǎng)址信息庫中提取出該內(nèi)容所在的標(biāo)題與網(wǎng)址等信息,最后再加上內(nèi)容信息庫中與關(guān)鍵詞相關(guān)的內(nèi)容信息作為查找的結(jié)果顯示出來。
2 具體算法實現(xiàn)
搜索引擎軟件開發(fā)環(huán)境:Myeclipse平臺,使用Java語言。首先可以Myeclipse平臺新建一個java project,在新建的project中需要導(dǎo)入下面一些相關(guān)的文件:
import java.io.BufferedReader;
import java.io.File;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.StringTokenizer;
搜索引擎軟件中獲得搜索結(jié)果的搜索函數(shù)核心代碼如下:
//根據(jù)用戶輸入的關(guān)鍵詞,在相應(yīng)的庫中進行搜索,并返回搜索結(jié)果信息
private static String search(String[] str, int n, String filepath)
{
String all=null;
File file=new File(filepath);
try{
String[] filelist=file.list();
for(int i=0,flen=filelist.length;i<flen; i++)
{
File readfile=new File(filepath+"\\"+
filelist[i]);
String upname=readfile.getName();
upname=upname.substring(0,upname.length
()-4);//去掉文件名中的.txt用于后面找網(wǎng)址
BufferedReader br=new BufferedReader
(new FileReader(
readfile));
String s="", ss=br.readLine();
while (ss != null)
{
s=s+ss;//s中存放文件內(nèi)容的信息
ss=br.readLine();
}
//判斷當(dāng)前讀入的記錄行中是否有
//輸入的關(guān)鍵詞,輸入了幾個關(guān)鍵詞
switch (n)
{
case 1://1個關(guān)鍵詞的情況
int end=s.indexOf(str[0]);
if (end != -1)
{
upname=Url(upname);
//獲取存標(biāo)題與網(wǎng)址信息
s=s.substring(end, 20);
//取關(guān)鍵字后的20個字符
all=all+"\n"+upname+"
關(guān)鍵字內(nèi)容:"+s;
flag=1;
break;
} else
break;
case 2://2個及多個關(guān)鍵詞的情況
......
}
br.close();//一定要關(guān)閉資源
}
} catch (FileNotFoundException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return all;
}
搜索函數(shù)中調(diào)用的其他主要函數(shù)代碼如下:
// 通過傳遞的文件名參數(shù),在文件TitleInfo中查找得到與此文件名對應(yīng)的標(biāo)題信息+網(wǎng)址信息
public static String Url(String filename)
{
String filepath="D:\\test\\TitleInfo\\TitleInfo.txt";
File file=new File(filepath);
String url="";
try
{
BufferedReader br=new BufferedReader(new
FileReader(file));
String s=br.readLine();//讀入第一行信息
while (s !=null)
{
if(s.indexOf(filename)!=-1)
{
url=s.substring(s.indexOf("標(biāo)題"),s.length());
//取該行標(biāo)題后的信息
break;
} else
s=br.readLine();//讀入下一行的信息
}
br.close();//一定要關(guān)閉資源
} catch (FileNotFoundException e)
{
e.printStackTrace();
} catch (IOException e)
{
e.printStackTrace();
}
return url;
}
至此,完成了搜索引擎軟件代碼的編寫工作,接下來可以進行run操作(即可以在指定內(nèi)容信息庫與標(biāo)題和網(wǎng)址信息庫中進行操作),返回用戶查找的相關(guān)網(wǎng)頁文件的序號、標(biāo)題、網(wǎng)址和主要內(nèi)容等信息的結(jié)果。
3 實驗結(jié)果分析
內(nèi)容信息庫的存放路徑為D:\test\ContentInfo;內(nèi)容信息庫中的內(nèi)容如圖2所示。標(biāo)題和網(wǎng)址信息庫的存放路徑為D:\test\TitleInfo;文件庫中存放了標(biāo)題和網(wǎng)址信息文件,文件名為TitleInfo.txt,其內(nèi)容如圖3所示。

運行該搜索引擎軟件,得出的輸出結(jié)果如圖4所示。

由圖4可以看到,通過該系統(tǒng)可以把待測文件中臟字及臟詞組出現(xiàn)的次數(shù)全部顯示出來,其結(jié)果與實際情況完全一致。
針對當(dāng)前網(wǎng)絡(luò)在高校的應(yīng)用越來越普及,校內(nèi)網(wǎng)絡(luò)中的資源也越來越多,而目前市場上的搜索軟件(如百度、谷歌的)又難以滿足實踐的需要,并且有些搜索軟件比較昂貴。本文在基于這些問題的情況下進行研究 與分析,提出了校內(nèi)網(wǎng)絡(luò)資源搜索軟件的設(shè)計方法,并在Myeclipse環(huán)境下通過Java語言實現(xiàn)了這種方法,為高校校內(nèi)網(wǎng)絡(luò)資源的搜索提供了一種方法。另外,可以在此基礎(chǔ)上進行二次開發(fā),作者就在此基礎(chǔ)上完成了Web界面上的搜索(類似百度的功能)。本軟件在南昌工程學(xué)院已開始試用,如圖5所示。

根據(jù)本文的設(shè)計原理,用戶可以根據(jù)自己的實際需要,在界面上改進與調(diào)整。
參考文獻
[1] 梁斌.走進搜索引擎[M].北京:電子工業(yè)出版社,2007.
[2] 宋春陽.Web搜索引擎技術(shù)綜述[J].現(xiàn)代計算機,2008(5).
[3] 徐寶文.搜索引擎與信息獲取技術(shù)[M].北京:清華大學(xué)出版社,2003.