
摘 要: 針對(duì)初始聚類中心對(duì)傳統(tǒng)K-means算法的聚類結(jié)果有較大影響的問題,提出一種依據(jù)樣本點(diǎn)類內(nèi)距離動(dòng)態(tài)調(diào)整中心點(diǎn)類間距離的初始聚類中心選取方法,由此得到的初始聚類中心點(diǎn)盡可能分散且具代表性,能有效避免K-means算法陷入局部最優(yōu)。通過UCI數(shù)據(jù)集上的數(shù)據(jù)對(duì)改進(jìn)算法進(jìn)行實(shí)驗(yàn),結(jié)果表明改進(jìn)的算法提高了聚類的準(zhǔn)確性。
關(guān)鍵詞: K-means;聚類算法;初始聚類中心;動(dòng)態(tài)聚類
聚類分析[1]是基于數(shù)據(jù)集客觀存在著若干個(gè)自然類,每個(gè)自然類中的數(shù)據(jù)的某些屬性都具有較強(qiáng)的相似性而建立的一種數(shù)據(jù)描述方法。因而可以講,聚類分析是將給定的一些模式分成若干組,對(duì)于多選定的屬性或者特征,每組內(nèi)的各樣本模式是相似的,而與其他組的樣本模式差別較大。聚類分析有許多具體的算法,從算法策略上看,可以分為如下幾種典型方法:(1)根據(jù)相似性閾值和最小距離原則的簡單聚類方法;(2)譜系聚類算法;(3)近鄰函數(shù)法;(4)動(dòng)態(tài)聚類法。其他方法基本是由這四種派生而來。
在眾多的聚類方法中,動(dòng)態(tài)聚類法中的K-means算法因其方法簡單、效率高、結(jié)果尚令人滿意,因此得到了廣泛的應(yīng)用。但是K-means算法本身存在缺陷和不足,如K值的選取、初始聚類中心的選取以及對(duì)噪聲敏感等問題。學(xué)術(shù)界對(duì)初始聚類中心的選取提出了多種改進(jìn)算法,如參考文獻(xiàn)[2]提出利用數(shù)據(jù)樣本的近鄰點(diǎn)信息確定初始聚類中心的方法;參考文獻(xiàn)[3]采用基于密度的思想,將不重復(fù)的核心點(diǎn)作為初始聚類中心;參考文獻(xiàn)[4]選擇包含數(shù)據(jù)樣本最多的K個(gè)類中心作為初始聚類中心;黃韜等[5]通過對(duì)數(shù)據(jù)集的多次采樣,選取最終較優(yōu)的初始聚類中心。這些算法提高了聚類準(zhǔn)確性,但初始中心點(diǎn)的選取未能同時(shí)兼顧代表性和分散性的特性。
針對(duì)樣本點(diǎn)之間的近類內(nèi)、遠(yuǎn)類間的分布特性,本文提出一種依據(jù)類內(nèi)距離動(dòng)態(tài)調(diào)整中心點(diǎn)類間距離的初始聚類中心選取方法,得到的初始聚類中心能盡量分散,很好地代表K個(gè)簇,并且,掃描一遍數(shù)據(jù)集即可完成初始聚類中心的選取。實(shí)驗(yàn)表明,與隨機(jī)選取初始聚類中心的傳統(tǒng)K-means算法相比,該方法提高了聚類的準(zhǔn)確率,使得聚類結(jié)果更穩(wěn)定。
1 K-means算法的基本理論
K-means算法有兩個(gè)階段,第一個(gè)階段是確定K個(gè)中心點(diǎn),每一類有一個(gè)中心點(diǎn);第二個(gè)階段是把數(shù)據(jù)集的每個(gè)樣本點(diǎn)關(guān)聯(lián)到最近的中心點(diǎn),并由此循環(huán)得到新的K個(gè)中心點(diǎn)。循環(huán)的結(jié)果就是中心點(diǎn)位置不斷地變動(dòng),直到穩(wěn)定不變,標(biāo)志著聚類收斂。
設(shè)待分類的數(shù)據(jù)集為{x1,x2,…,xC},聚類的個(gè)數(shù)為K。算法的具體步驟如下:

在K-means算法中,數(shù)據(jù)之間的相似度用歐氏距離來衡量,距離越大越不相似,距離越小越相似,兩個(gè)簇之間數(shù)據(jù)太密集就會(huì)合并為新的聚類簇,而離兩個(gè)聚類簇稀疏的數(shù)據(jù)就會(huì)形成新的簇。因此如果選取兩個(gè)簇密集區(qū)域的聚類中心的平均值和離簇稀疏的數(shù)據(jù)作為初始聚類中心,將有利于目標(biāo)函數(shù)的收斂。
由此,本文將依據(jù)樣本點(diǎn)實(shí)際分布情況,利用類內(nèi)最短距離調(diào)整中心點(diǎn)的類間距離,不斷更新優(yōu)化初始聚類中心。基本思路如下:(1)隨機(jī)選取的K個(gè)樣本(記為集合L)作為初始中心點(diǎn),按式(4)計(jì)算這K個(gè)數(shù)據(jù)兩兩之間的最小距離作為初始類間距離limit,設(shè)集合R=U-L;(2)按式(4)計(jì)算R中任一樣本點(diǎn)到L的最短距離t=Dist[ri,L](ri表示R中第i個(gè)樣本點(diǎn)),如果t大于limit,則刪除集合L中最近的兩個(gè)點(diǎn),把這兩點(diǎn)的中點(diǎn)ri加入到集合L中,更新limit為t。否則,不做任何操作;(3)更新R=R-ri,重復(fù)步驟(2),直至R為空。
假設(shè)現(xiàn)在有一個(gè)二維數(shù)據(jù)樣本集合,含有6個(gè)樣本點(diǎn),分成3個(gè)聚類簇,如圖1所示。

按照本文的算法思想:(1)首先隨機(jī)選取3個(gè)初始點(diǎn)A、C、D構(gòu)成集合L,按式(4)計(jì)算這3個(gè)數(shù)據(jù)兩兩之間的最小距離作為初始閾值limit,設(shè)集合R=U-L={B、E、F};(2)按式(4)計(jì)算R中任一樣本點(diǎn)到L的最短距離t=Dist[B,L],若t大于閾值limit,則刪除集合L中最近的兩個(gè)點(diǎn)C和D,并把這兩點(diǎn)的平均值和B加入到集合L中,更新閾值limit為Dist[B,L];(3)更新R=R-B={E、F}。重復(fù)步驟(2),直到R為空。最終得到的聚類中心接近于聚類算法期望得到的聚類中心。
由上述動(dòng)態(tài)選取初始聚類中心算法得到的聚類中心作為K-means算法的初始聚類中心,即為改進(jìn)的動(dòng)態(tài)K-means算法。
改進(jìn)的動(dòng)態(tài)K-means算法的時(shí)間復(fù)雜度主要由兩部分組成,一部分是生成初始聚類中心的時(shí)間,另一部分是迭代所需要的時(shí)間。改進(jìn)的動(dòng)態(tài)K-means算法計(jì)算出初始聚類中心需要的時(shí)間復(fù)雜度為O(K×C×N),其中K為聚類數(shù),C為所有樣本數(shù)據(jù)的個(gè)數(shù),N為樣本屬性。
3 實(shí)驗(yàn)與結(jié)果分析
為驗(yàn)證改進(jìn)算法的有效性,本文采用UCI標(biāo)準(zhǔn)數(shù)據(jù)集中的葡萄酒Wine數(shù)據(jù)集和鳶尾花Iris數(shù)據(jù)集。對(duì)各數(shù)據(jù)集的描述如表1所示。

對(duì)于表1所描述的數(shù)據(jù),本文做對(duì)比實(shí)驗(yàn),比較隨機(jī)選取聚類中心的K-means算法和本文改進(jìn)的動(dòng)態(tài)K-means算法,分別在Wine和Iris數(shù)據(jù)集上進(jìn)行10次試驗(yàn)。本文用隨機(jī)的方式選取初始中心點(diǎn),實(shí)驗(yàn)結(jié)果如表2、表3、圖2和圖3所示。

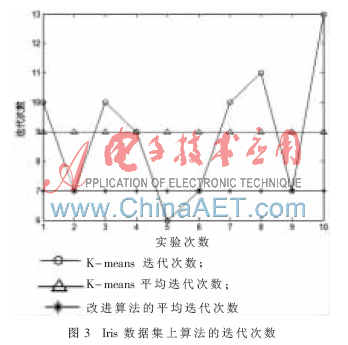
從表2和圖2可以看出,在Wine數(shù)據(jù)集進(jìn)行10次實(shí)驗(yàn),K-means算法的準(zhǔn)確率在53.37%~70.22%之間浮動(dòng),平均準(zhǔn)確率為62.25%;迭代次數(shù)最少5次,最多16次,平均迭代次數(shù)為9。由此可見,K-means聚類算法結(jié)果不穩(wěn)定,并且受初始中心點(diǎn)影響很大。本文算法平均準(zhǔn)確率為70.34%,平均迭代次數(shù)為5。從表3和圖3可以看出,在Iris數(shù)據(jù)集進(jìn)行10次實(shí)驗(yàn),K-means算法平均準(zhǔn)確率為75%,平均迭代次數(shù)為9次,本文算法平均準(zhǔn)確率為89.47%,平均迭代次數(shù)為7次。實(shí)驗(yàn)結(jié)果表明,本文改進(jìn)的動(dòng)態(tài)K-means算法選取的初始聚類接近簇中心,收斂速度快,準(zhǔn)確率高,聚類效果好。
K-means算法的聚類結(jié)果受初始聚類中心影響很大且迭代次數(shù)多,本文改進(jìn)的算法優(yōu)化了初始聚類中心,有效地提高了收斂速度,提高了聚類的準(zhǔn)確率。但本文方法受噪聲點(diǎn)影響較大,下一步將對(duì)減少噪聲點(diǎn)的影響方面進(jìn)行學(xué)習(xí)和研究。
參考文獻(xiàn)
[1] 孫即祥,姚偉,騰書華.模式識(shí)別[M].北京:國防工業(yè)出版社,2009.
[2] CAO F Y,LIANG J Y,JIANG G.An initialization method for the K-means algorithm using neighborhood model[J].Computers&Mathematics with Applications,2009,58(3):474-483.
[3] 張琳,陳燕,汲業(yè),等.一種基于密度的K-means算法研究[J].計(jì)算機(jī)應(yīng)用研究,2011,28(11):4071-4073.
[4] 張瓊,張瑩,白清源,等.基于Leader的K均值改進(jìn)算法[J].福州大學(xué)學(xué)報(bào),2008,36(4):493-496.
[5] 黃韜,劉勝輝,譚艷娜.基于K-means聚類算法的研究[J].計(jì)算機(jī)技術(shù)與發(fā)展,2011,21(7):54-57.