
0 引 言
近年來(lái),VoIP(Voice over
IP)技術(shù)及其業(yè)務(wù)的迅速發(fā)展,對(duì)傳統(tǒng)的電信業(yè)務(wù)造成了巨大的沖擊,與傳統(tǒng)電話相比,IP電話以其網(wǎng)絡(luò)帶寬利用率高,通話成本低,可靈活地提供豐富的增值功能而備受市場(chǎng)青睞。然而,由于VoIP的語(yǔ)音在與其他數(shù)據(jù)一起在網(wǎng)絡(luò)中傳輸時(shí)要經(jīng)過(guò)壓縮、編碼、打包等一系列處理,造成回聲路徑的延遲較大,延遲抖動(dòng)也較大,嚴(yán)重影響了話音質(zhì)量,阻礙了VoIP市場(chǎng)的拓展。因此,在VoIP終端上增加回聲消除算法已成為必然。
1 聲學(xué)回聲消除技術(shù)的原理
1.1 聲學(xué)回聲產(chǎn)生原理
根據(jù)回聲的產(chǎn)生原因,回聲可以分為聲學(xué)回聲和電學(xué)回聲兩類。電學(xué)回聲是由于電路阻抗不匹配造成的,通常影響比較小。隨著消除回聲技術(shù)的發(fā)展,當(dāng)前回聲消除研究的重點(diǎn)已由“電學(xué)回聲”的消除轉(zhuǎn)向了“聲學(xué)回聲”的消除。聲學(xué)回聲指設(shè)備的一部分聲音信號(hào)回饋到同一設(shè)備的受話器,分為直接回聲和間接回聲。直接回聲指揚(yáng)聲器的聲音未經(jīng)任何反射直接進(jìn)入麥克風(fēng),這種回聲延遲最短。間接回聲是指揚(yáng)聲器播放的聲音經(jīng)不同的路徑一次或多次反射后進(jìn)入麥克風(fēng)所產(chǎn)生的回聲集合,其主要特點(diǎn)是回聲路徑?jīng)_激響應(yīng)變化范圍大,變化快,沖激響應(yīng)持續(xù)時(shí)間長(zhǎng),一般在50~300
ms。這使得自適應(yīng)建模濾波器的階數(shù)很高,因而成為語(yǔ)音通信系統(tǒng)回聲的主要難題。
1.2 聲學(xué)回聲消除的原理
自適應(yīng)回聲抵消的基本思想是估計(jì)回聲路徑的特征參數(shù),產(chǎn)生一個(gè)模擬的回音路徑,得出模擬回聲信號(hào),從接收信號(hào)中減去該信號(hào),實(shí)現(xiàn)回聲抵消。
圖1中,y(n)代表來(lái)自遠(yuǎn)端的信號(hào);r(n)是經(jīng)過(guò)回聲通道而產(chǎn)生的不期望的回聲;x(n)是近端的語(yǔ)音信號(hào);D口的近端信號(hào)疊加有不期望的回聲。對(duì)消回聲器來(lái)說(shuō),接收到的遠(yuǎn)端信號(hào)作為參考信號(hào),消回聲器根據(jù)由自適應(yīng)濾波器產(chǎn)生回聲估計(jì)值,將r1(n)從近端帶有回聲的語(yǔ)音信號(hào)減去,就得到近端傳送出去的信號(hào)μ(n)=x(n)+r(n)-r1(n)。在理想情況下,經(jīng)過(guò)消回聲處理后,殘留的回聲誤差e(n)=r(n)-r1(n)將為0,從而實(shí)現(xiàn)回音消除。
2 自適應(yīng)回聲消除算法理論
回聲消除理論的難點(diǎn)是估計(jì)回聲與近端輸入信號(hào)之間的同步問(wèn)題以及如何對(duì)雙端講話進(jìn)行處理的問(wèn)題,若這兩個(gè)問(wèn)題處理不好,就會(huì)造成濾波器的發(fā)散,不但不能消除回聲,反而會(huì)引入更煩人的噪聲。
2.1 雙端話音處理與MDF算法結(jié)合
在NLMS算法中,假設(shè)輸入近端背景噪聲與遠(yuǎn)端信號(hào)均為白噪聲,那么兩信號(hào)間為時(shí)間無(wú)關(guān)的,因此可以求得最優(yōu)步長(zhǎng)因子:
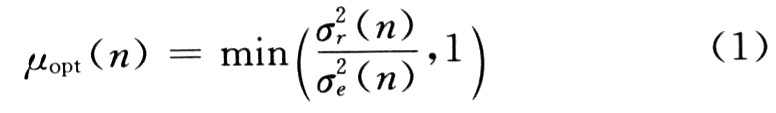
式中:r(n)為殘留回聲的方差的估計(jì)值;e(n)為誤差信號(hào)的方差的估計(jì)值。
但是用LMS/NLMS算法來(lái)進(jìn)行語(yǔ)音信號(hào)的聲學(xué)回聲消除時(shí),兩信號(hào)時(shí)間無(wú)關(guān)的假設(shè)就不完全成立,因此只能借助于頻域處理法。MDF算法相當(dāng)于對(duì)每一個(gè)頻率使用NLMS算法。為了解決雙端講話檢測(cè)這個(gè)難題,文獻(xiàn)[6]提出了一種與MDF相結(jié)合的不需要顯式進(jìn)行雙端話音檢測(cè)的方法,以下是推導(dǎo)。由于信號(hào)在頻域的相關(guān)程度比在時(shí)域的相關(guān)程度小得多,而且步長(zhǎng)因子μ也可以變換到頻率域μ(k,l),即有公式:
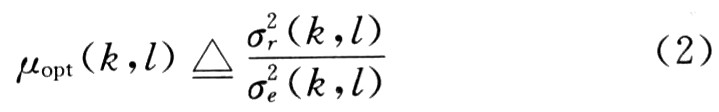
式中:k為輸入信號(hào)塊索引號(hào);l為信號(hào)頻率。假定殘留回聲是泄漏因子η(l)與回聲估計(jì)值的乘積,即:
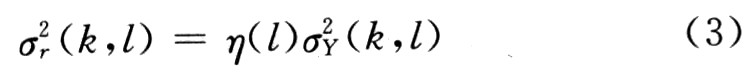
又因?yàn)椴介L(zhǎng)因子需要在雙端講話發(fā)生時(shí)迅速對(duì)其做出反應(yīng),故可以有等式:
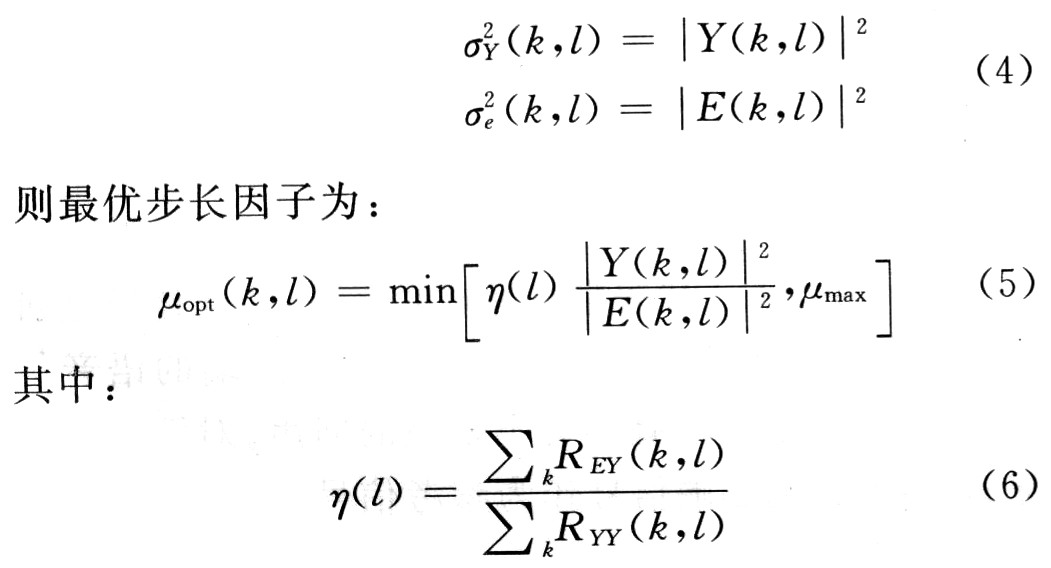
分子代表估計(jì)回聲與誤差信號(hào)的互相關(guān)值,分母為估計(jì)回聲的自相關(guān)值。若有雙端講話存在,則誤差就會(huì)變得很大,因此步長(zhǎng)因子就會(huì)變得非常小,不會(huì)使濾波器系數(shù)變化太大;若有背景噪聲存在,由于步長(zhǎng)因子公式中,分子分母都有噪聲的影響,因此相互抵消后噪聲的影響也會(huì)變得非常小了。
2.2 估計(jì)回聲與近端輸入信號(hào)的同步
回聲消除的原理就是利用參考回聲與真實(shí)回聲之間的相關(guān)性,因此播放聲音的線程和錄音線程之間的同步就顯得極為重要。下面分兩步進(jìn)行處理:
第一步,輸入/輸出設(shè)備與處理器之間存在速度不匹配的問(wèn)題,為了改善這個(gè)矛盾,需要在輸入/輸出端分別劃出若干個(gè)專用緩沖區(qū)。在本測(cè)試環(huán)境中,輸入/輸出流的延遲經(jīng)過(guò)計(jì)算結(jié)果為10幀,也就是從處理器把第一幀要播放的聲音放人參考回聲幀隊(duì)列算起,到處理器從參考回聲幀隊(duì)列中取出一幀來(lái)與第一幀錄音輸入進(jìn)行回聲消除時(shí)為止,錄音輸入比參考回聲在時(shí)間上落后了10幀。也就是說(shuō),這前10幀錄音輸入不用進(jìn)行回聲消除,而是直接傳走,這個(gè)過(guò)程就稱為預(yù)取。
第二步,實(shí)際應(yīng)用中播放聲音和錄音是用兩個(gè)線程完成的,所以僅僅用上面固定的延遲數(shù)量來(lái)同步參考回聲和錄音輸入這兩個(gè)信號(hào)還不行。設(shè)一個(gè)變量rec_ts作為處理器要處理的錄音輸入幀的序列號(hào),設(shè)play_ts作為處理器處理的參考回聲幀的序列號(hào)。用seq_delay=play_ts-rec_ts來(lái)修正上面的預(yù)取過(guò)程。當(dāng)Seq_delay>0時(shí),證明播放線程比錄音線程快,因此則減少錄音輸入幀的預(yù)取個(gè)數(shù);當(dāng)Seq-delay<0時(shí),證明播放線程比錄音線程慢,因此則增加錄音輸入幀的預(yù)取個(gè)數(shù)。
3 測(cè)試及結(jié)論
Speex是一個(gè)開源、免費(fèi)、專門針對(duì)VoIP語(yǔ)音的編解碼器,是一種動(dòng)態(tài)比特率編碼方式,它意味著可以根據(jù)網(wǎng)絡(luò)環(huán)境的變化來(lái)動(dòng)態(tài)地修改其比特率,它在窄帶和寬帶中都提供相應(yīng)版本。回音消除一直是VoIP中亟待解決的主要問(wèn)題,所以近年來(lái)Speex中也集成了回音消除的模塊。因?yàn)镾peex算法中,AEC沒(méi)有考慮線程同步問(wèn)題,因此這里提出了一種使播放線程和錄音線程同步的方法。
用PC機(jī)在VC 6.O下建工程進(jìn)行測(cè)試。用麥克將一段語(yǔ)音錄下,存為ref.pcm,之后用音箱把這段錄音播放出來(lái),播放的同時(shí)再用麥克將其錄下,等播放一段時(shí)間后(代表只有遠(yuǎn)端講話的情況),再有人開始講話,這時(shí)的錄音就代表雙端講話的情況,把該文件存為echo.pcm。測(cè)試時(shí)采樣率為8 000 Hz,20 ms為一幀,/μmax=1。
回聲抵消效果一般還采用回聲返回衰減增益(ERLE)來(lái)評(píng)價(jià),其定義如下:

ERLE值越大,則表明回聲抵消效果越好,一般要求ERLE≥6 dB。測(cè)試回聲返回衰減增益如圖2所示。
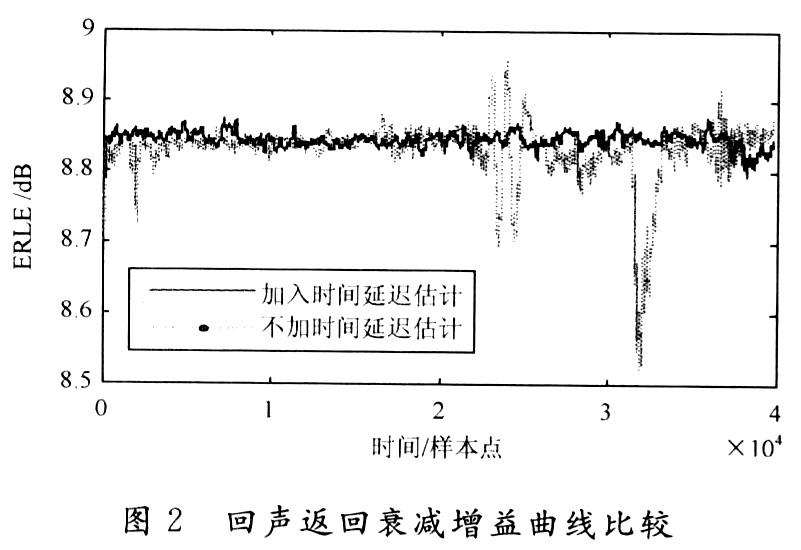
由圖2可知,加入時(shí)間延遲估計(jì)后的效果好于不加時(shí)間延遲估計(jì)的效果。
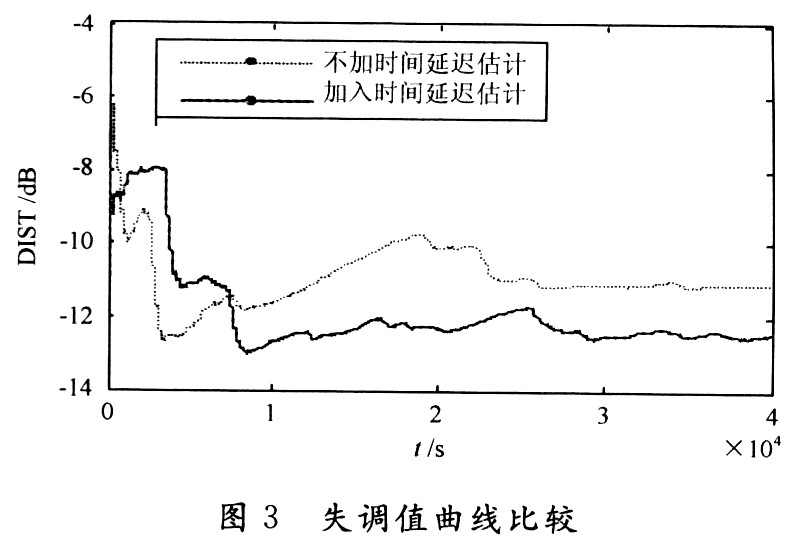
失調(diào)也稱為系統(tǒng)距離(DIST),反映的是回聲消除器中自適應(yīng)FIR濾波器r1(n)對(duì)真實(shí)回聲路徑r(n)的逼近程度。其定義如下:
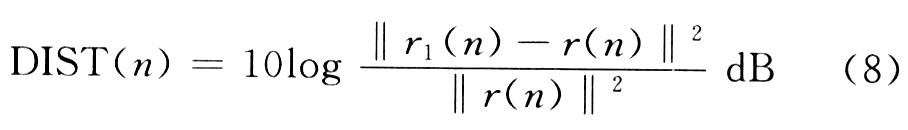
DIST值越低,表明自適應(yīng)濾波器收斂性能越好。由圖3也可看出,加入時(shí)間延遲估計(jì)后的失調(diào)量總體上低于不加時(shí)間延遲估計(jì)的失調(diào)量。
通過(guò)測(cè)試和大量的通話主觀測(cè)試,結(jié)果表明,用該方法實(shí)現(xiàn)的聲學(xué)回聲消除器能夠滿足通信對(duì)語(yǔ)音的要求,因此為VoIP語(yǔ)音通信和移動(dòng)通信終端提供了參考。