
0 前言
隨著智能手機和平板電腦等無輸入鍵盤電子設(shè)備的流行,,聯(lián)機手寫識別的研究吸引了越來越多的關(guān)注,。而手寫簽名驗證和基于3D加速度傳感器的姿態(tài)識別,、手寫識別等新應(yīng)用形式的出現(xiàn),,也為聯(lián)機手寫識別的研究注入了新的活力,。
支持向量機(Support Vector Machine,,SVM)是在統(tǒng)計學(xué)習(xí)理論的基礎(chǔ)上發(fā)展起來的新一代分類識別算法,,使用核函數(shù)方法將非線性可分的特征向量映射到高維空間,計算最大化分類間隔的最優(yōu)分類超平面。在文本分類,、語音識別,、手寫識別、曲線擬合等領(lǐng)域,,SVM已經(jīng)有比較成熟的應(yīng)用,。但是,一般的核函數(shù)要求不同樣本的特征向量的維數(shù)相同,,限制了SVM在語音識別和聯(lián)機手寫識別領(lǐng)域的進(jìn)一步發(fā)展,。為此,Bahlmann等人使用彈性距離計算算法--DTW算法--構(gòu)造了GDTW核函數(shù),,進(jìn)而提出GDTW-SVM算法,。GDTW-SVM的聯(lián)機手寫識別實驗結(jié)果表明,GDT W-SVM取得了可媲美隱馬爾科夫模型,、神經(jīng)網(wǎng)絡(luò)等分類算法的識別率,,并且與使用后來提出的基于其它彈性距離計算構(gòu)造的核函數(shù)的SVM相比,性能不相伯仲,。
本文結(jié)合GDTW核函數(shù)和聯(lián)機手寫識別樣本的特征向量的特點,,引入新的控制參數(shù)優(yōu)化GDTW核函數(shù)的計算。實驗結(jié)果表明,,本文提出的優(yōu)化方法不僅減少了支持向量的數(shù)目,,而且提高了GDTW-SVM運行效率。
1 聯(lián)機手寫識別過程
1.1 聯(lián)機手寫識別流程介紹
聯(lián)機手寫識別的過程與通用模式識別的過程基本相同,,由數(shù)據(jù)采集和預(yù)處理,、特征提取、分類識別,、后處理四個步驟組成,。
在數(shù)據(jù)采集和預(yù)處理階段,首先使用傳感器采集原始物理信息,,比較常見的是加速度,、速度、位移,、起筆和落筆,;然后,對原始信息進(jìn)行傳感器矯正,、去噪等預(yù)處理,。
特征提取是手寫識別的重要步驟之一,對分類器的設(shè)計和分類結(jié)果有著重要的影響,,選擇合適的特征不僅可以提高識別率,,也可以節(jié)省計算存儲空間,、運算時間、特征提取費用,。聯(lián)機手寫識別中比較常見特征提取方法有加速度,、位移、DCT變換等,。
分類識別是手寫識別的核心階段,,大多數(shù)分類器在實際分類應(yīng)用之前,需要使用訓(xùn)練樣本對分類器進(jìn)行訓(xùn)練,,不斷地修正特征提取方法和方案,、分類器的判決規(guī)則和參數(shù)。目前,,分類識別的訓(xùn)練階段需要人工干預(yù)以達(dá)到最佳的識別率,。
一些識別系統(tǒng)在分類識別之后使用后處理進(jìn)一步提高識別率。例如,,數(shù)字“1”和小寫字母“1”在很多情況下難以分辨,,但是在后處理階段結(jié)合上下文信息,決定當(dāng)前字符是數(shù)字“1”還是小寫字母“1”,。
1.2 聯(lián)機手寫識別實驗
本文聯(lián)機手寫識別實驗采用了Bahlmann等人和Bothe等人使用的方法,。所使用的樣本數(shù)據(jù)庫是免費的聯(lián)機手寫數(shù)據(jù)庫UJIpenchars2。它采用Toshiba M400 Tablet PC收集,,包含60個書寫者的共11640個手寫樣本。這些樣本包含ASCII字符,、拉丁字符和西班牙字符,,而每個字符包含80個訓(xùn)練樣本和140個測試樣本。每個樣本由一劃或多劃組成,,數(shù)據(jù)庫提供每個筆劃的坐標(biāo)序列,。
坐標(biāo)序列由等時間間隔采集的筆尖的水平坐標(biāo)xi和垂直坐標(biāo)yi組成。而在本文實驗中,,樣本的坐標(biāo)序列不經(jīng)過任何去噪等預(yù)處理,,直接對每個坐標(biāo)點,使用字符的重心(μx,,μy)和垂直坐標(biāo)的方差σy計算列向量

式(1)中,,ang是求虛數(shù)相角的函數(shù)。每個字符樣本的特征向量是T=(t1,,…,,tNT),其中,,NT是采集的坐標(biāo)點數(shù)目,,即特征向量的維數(shù),每個字符樣本的NT可以不相同。
本文的聯(lián)機手寫識別實驗假設(shè)每個字符不需要分析其上下文即可完成識別,,所以,,特征提取之后使用本文所述的分類算法進(jìn)行分類識別,并且將其輸出結(jié)果作為最終識別結(jié)果,,不經(jīng)過任何后處理,。
2 GDTW-SVM算法
2.1 支持向量機
假設(shè)線性分類器對輸入的特征向量x={x1,x2,,…xn}(n是樣本數(shù)目),,輸出Y={y1,y2,,…,,yn}其中,xi,,I RN,,N是特征向量的維數(shù):yi∈{-1,1},, yi=-1表示樣本(xi,,yi)屬于第一類,yi=1表示樣本(xi,,yi)屬于另一類,。該線性分類器的分類決策為
y(
式(2)中(w,b)確定分類超平面
SVM以最小化結(jié)構(gòu)風(fēng)險為目標(biāo),,計算使得訓(xùn)練樣本集到分類超平面的距離最大化的最優(yōu)分類超平面,。其等價于對式(2)求解凸二次規(guī)劃問題。

即尋找使平均距離最小的最優(yōu)對齊路徑,。DTW距離越小,,T和R所代表的樣本越相似??梢允褂脛討B(tài)規(guī)劃(Dynamic Programming)算法計算最優(yōu)對齊路徑和DTW距離,。
圖1給出了最優(yōu)對齊路徑和DTW距離的示例,其中,,上半部分是字符樣本的繪圖,,順次是“oocae”;下半部分是各個字符樣本與第一個字符樣本的最優(yōu)對齊路徑和DTW距離,。

Bahlmann等人使用DTW距離代替高斯核函數(shù)(6)中的歐幾里德距離‖X-Z‖p的計算(取p=2),,構(gòu)造了GDTW核函數(shù)
KGRBF(X,Z)=exp(-y·DTW(X,,Z)) (8)
他們的聯(lián)機手寫識別實驗的結(jié)果和Bothe等人的實驗結(jié)果表明,,GDTW-SVM取得了比GDTW-SVM和k近鄰算法(k-Nearest Neighbor,,kNN)更高的識別率,而且在不同聯(lián)機手寫識別數(shù)據(jù)庫子集的識別實驗中,,與基于其它彈性距離計算的核函數(shù)的SVM相比,,各有優(yōu)劣且識別率的差值在0.3%以內(nèi)。
3 優(yōu)化GDTW-SVM算法
盡管GDTW-SVM獲得了較高的識別率,,但是其計算復(fù)雜度高,。DTW算法的計算復(fù)雜度是O(NT,NR),而SVM算法在訓(xùn)練和識別過程中需要反復(fù)使用GDTW核函數(shù),,對于嵌入式設(shè)備的計算能力要求較高,。因此,需要對GDTW核函數(shù)進(jìn)行優(yōu)化,。
分析圖1中的最優(yōu)對齊路徑,,當(dāng)兩個樣本完全相同時,最優(yōu)對齊路徑和對角線重合,;當(dāng)兩個樣本有所差別時,,最優(yōu)對齊路徑偏離對角線,且差別(DTW距離)越大最優(yōu)路徑越偏離對角線,。下面以字母m和n為例,,進(jìn)一步分析以上結(jié)論。
(1)依次從字母n的所有訓(xùn)練樣本中選擇一個樣本,,計算其到字母n的所有訓(xùn)練樣本最優(yōu)對齊路徑,,并規(guī)整到80’80矩陣;
(2)將所有計算結(jié)果疊加后得到n-n最優(yōu)對齊路徑疊加圖,;
(3)繪制疊加圖,,即圖2的第一幅圖,圖中像素點灰度越高,,代表越多最優(yōu)對齊路徑經(jīng)過此點。同理,,繪制n-m最優(yōu)對齊路徑疊加圖和m-m最優(yōu)對齊路徑疊加圖,,分別為圖2的第二和第三幅圖所示。
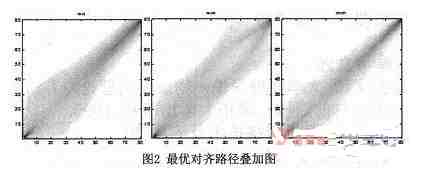
從圖2可以看到,,兩個相同或相似字符的最優(yōu)對齊路徑集中在對角區(qū)域:由于n的不同樣本,、m的不同樣本的起筆寫法比收筆寫法隨意,第一和第三幅圖的對角區(qū)域的左下角比較寬,;n和m的最優(yōu)對齊路徑在對角區(qū)域中分布較均勻,,且第二幅圖顯示對角區(qū)域的中部有明顯的低灰度區(qū)域。
假設(shè)訓(xùn)練樣本可以代表聯(lián)機手寫字符的特征,,則可以通過僅計算對角區(qū)域中的最優(yōu)對齊路徑來優(yōu)化GDTW核函數(shù),。計算兩個樣本T=(t1,,…,tNT)和R=(r1,,…,,rNR)的GDTW核函數(shù)時,假定二者屬于相同的字符類,,那么二者的差別不大,,因此,在GDTW核函數(shù)計算中引入?yún)?shù)k和τ

式(9)中l(wèi)bottom,,ltop,,lleft,lright如圖3所示,。引入?yún)?shù)k和τ之后,,不在NT×NR的矩陣中求解式(8),而是在k和τ約束的區(qū)域(即圖3中兩條虛線所夾的對角區(qū)域)中求解,,計算最優(yōu)對齊路徑,。

從直觀的角度看,參數(shù)k和τ減少了最優(yōu)對齊路徑的計算空間,,因此,,修改后的GDTW核函數(shù)的計算時間減少。而另外一方面,,如果參數(shù)τ保持不變(如τ=0.6),,參數(shù)k越小,最優(yōu)對齊路徑的前端的計算被約束在越小的空間,,迫使其“最優(yōu)”對齊路徑的計算選擇非最優(yōu)對齊路徑,,即參數(shù)k是兩個字符樣本頭部的相識程度的權(quán)重;類似地,,參數(shù)τ是兩個字符樣本尾部的相識程度的權(quán)重,。參數(shù)k和τ的權(quán)重作用對于如數(shù)字“0”和“6”等相似字符的分類有重要意義。
4 實驗結(jié)果與分析
本文主要針對阿拉伯?dāng)?shù)字樣本集和英文字母樣本集進(jìn)行識別實驗,,阿拉伯?dāng)?shù)字樣本集,、英文小寫字母樣本集和英文大寫字母樣本集分開識別。實驗環(huán)境是Matlab R2010a,,所使用的SVM工具包是Matlab SVM Toolbox,。
分類實驗采用Leave-One-Out的交叉驗證策略:依次從樣本集中取出一個字符的訓(xùn)練樣本標(biāo)記為第一類,將剩余字符的訓(xùn)練樣本標(biāo)記為第二類,,用標(biāo)記后的訓(xùn)練樣本訓(xùn)練GDTW-SVM,;使用樣本集中的所有測試樣本測試GDTW-SVM的識別率。
使用未優(yōu)化GDTW-SVM重復(fù)分類識別10次,,取10次實驗結(jié)果的平均值作為未優(yōu)化GDTW-SVM的識別結(jié)果,;其次,,優(yōu)化GDTW-SVM的參數(shù)(K,τ)分別取(0.2,,0.5),、(0.2,0.2)和(0.5,,0.5),,分別重復(fù)分類識別10次且取10次識別結(jié)果的平均值作為使用該組參數(shù)的優(yōu)化GDTW-SVM的識別結(jié)果,最終取三組識別結(jié)果中的最優(yōu)識別結(jié)果作為優(yōu)化GDTW-SVM的識別結(jié)果,;以上實驗中,,γ=1.9。
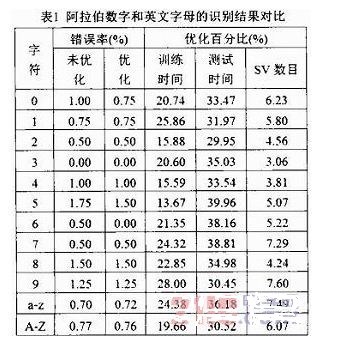
表1是阿拉伯?dāng)?shù)字和英文字母的識別結(jié)果對比,。其中,,英文字母數(shù)目較多,因此,,僅給出平均識別結(jié)果,。優(yōu)化后的GDTW-SVM和未優(yōu)化的GDTW-SVM的實驗結(jié)果對比顯示:參數(shù)k和τ的引入不僅使字符識別的錯誤率基本保持不變,同時,,訓(xùn)練時間減少13~25%,、測試時間減少29~39%、支持向量的數(shù)目也減少3.0~7.6%,。
5 結(jié)論
本文提出了在GDTW核函數(shù)中引入?yún)?shù)k和τ,,約束GDTW最優(yōu)對齊路徑的計算空間,然后構(gòu)造GDTW-SVM分類器,。實驗結(jié)果表明,,優(yōu)化后的GDTW-SVM分類器的識別率與未優(yōu)化的分類器的識別率基本相同;同時,,支持向量數(shù)目減少,,計算時間有13%~39%的減少,有利于GDTW-SVM分類器的聯(lián)機手寫識別的應(yīng)用和推廣,。