
MPEG-4是一種新興的視頻標(biāo)準(zhǔn),其彈性糾錯能力和可支持小屏幕的特性使之在移動通信市場上受到廣泛關(guān)注,幾乎所有移動電話生產(chǎn)商和PDA開發(fā)商都對其表示出極大的興趣。然而這種視頻標(biāo)準(zhǔn)對處理器的要求卻非常高。在整個(gè)移動通信結(jié)構(gòu)中,僅MPEG-4處理器這一部分就會毫不客氣地吞掉大量的資源。因而要想真正實(shí)現(xiàn)無線視頻應(yīng)用這一夢想,首先就必須解決MPEG-4信號處理問題。
工程師們已經(jīng)嘗試過采用固定編碼邏輯和通用型DSP來完成這一龐然大物般的MPEG-4處理,但結(jié)果均不理想。固定編碼邏輯雖然能夠提供較高的性能,但設(shè)計(jì)和實(shí)現(xiàn)所需的時(shí)間太長,而且得到的設(shè)計(jì)結(jié)果不夠靈活,無法滿足將來修改的需要。而通用可編程數(shù)字信號處理器(DSP)盡管很適合有限沖擊響應(yīng)(FIR)濾波和其他一些MAC密集的應(yīng)用,但對于可變長度解碼和離散余弦變換等視頻編解碼中固有的算法卻又無法有效實(shí)現(xiàn)。
那么怎樣才能設(shè)計(jì)出滿足要求的處理器呢?本文給出了一種方案:采用定制DSP。工程師們可以利用數(shù)字DSP IP核并結(jié)合一些新的設(shè)計(jì)方法,設(shè)計(jì)一種用戶化的引擎來完成所需的MPEG-4功能,從而將無線視頻應(yīng)用變?yōu)楝F(xiàn)實(shí)。
本方案的第一步,要開發(fā)一種應(yīng)用軟件來執(zhí)行MPEG-4視頻標(biāo)準(zhǔn),然后對該軟件進(jìn)行優(yōu)化和校驗(yàn),以保證其滿足MPEG-4視頻標(biāo)準(zhǔn)的要求。第二步,在這個(gè)應(yīng)用軟件得到優(yōu)化之后,將其編譯至一個(gè)通用型DSP引擎,仔細(xì)分析它在應(yīng)用中可能出現(xiàn)的性能瓶頸。通過分析,構(gòu)造一組由設(shè)計(jì)者定義的計(jì)算單元(DDCU),有針對性地解決應(yīng)用中的計(jì)算瓶頸問題。這組DDCU構(gòu)成一個(gè)庫,利用這個(gè)庫,設(shè)計(jì)者可以為不同的產(chǎn)品和產(chǎn)品域創(chuàng)建不同的用戶應(yīng)用DSP引擎。例如,在一個(gè)支持QCIF(四分之一普通接口格式)和CIF幀格式的PDA中,可以通過簡單等級(SP)和高級簡單等級(ASP)創(chuàng)建一個(gè)簡單的定制 DSP來實(shí)現(xiàn)低速編解碼。
此外,通過恰當(dāng)?shù)脑O(shè)計(jì)規(guī)劃,設(shè)計(jì)者還可以使引擎的性能剛好滿足目標(biāo)產(chǎn)品的要求——例如針對CIF格式設(shè)計(jì)出幀處理速度為每秒15幀的 DSP引擎——這樣就能降低對時(shí)鐘速率、指令長度和存儲映像的要求,從而實(shí)現(xiàn)低功率和低成本。但是若想支持更大尺寸的幀并支持高級分析,就需要創(chuàng)建一種性能更高的DSP引擎。這種DSP引擎內(nèi)部并行度更高,可用資源量更大,因而運(yùn)行速度也更快。
最后一步,將定制DSP融入多處理器內(nèi)核,通過兩者的共同作用來達(dá)到進(jìn)一步規(guī)劃高端應(yīng)用性能的目的。在當(dāng)今的通信行業(yè)中,產(chǎn)品推向市場的速度越來越快,以上談到的方法和工具恰好為快速分析和創(chuàng)建定制DSP從而加快產(chǎn)品設(shè)計(jì)提供了一種較好的方案。
下面讓我們看看定制DSP是如何創(chuàng)建的。
可定制的VLIW(超長指令字)引擎
引擎指一組資源的集合,通過對這種資源編程,可以使之以某種給定的順序?qū)崿F(xiàn)一系列操作。通常,設(shè)計(jì)中最主要的處理工作是由數(shù)據(jù)通道資源-即我們所說的計(jì)算單元-來完成的。
計(jì)算單元可以對其輸入進(jìn)行一系列操作,并輸出一個(gè)或多個(gè)計(jì)算結(jié)果。RISC(精簡指令集計(jì)算機(jī))和DSP是兩種由計(jì)算單元組成的處理器。其中,RISC處理器每次(每時(shí)鐘周期)只能執(zhí)行一個(gè)操作,而典型的多媒體和DSP應(yīng)用卻可以在每個(gè)時(shí)鐘周期內(nèi)執(zhí)行多項(xiàng)操作。這是因?yàn)榇蟛糠诌@種高級DSP 的結(jié)構(gòu)都具有某種形式的指令級并行處理能力。
本文給出的方案中,針對MPEG-4應(yīng)用而設(shè)計(jì)的DSP引擎能夠達(dá)到固定編碼邏輯和通用型DSP都無法達(dá)到的性能。該引擎之所以如此成功,主要原因之一就是采用了VLIW結(jié)構(gòu)。VLIW是一種非常適合多媒體應(yīng)用的結(jié)構(gòu)。它支持指令級并行性,這就使得采用它的DSP引擎可以在單時(shí)鐘周期內(nèi)執(zhí)行多項(xiàng)操作。不但如此,它還支持應(yīng)用程序編譯過程中的并行性,這又避免了為龐大的視頻處理耗費(fèi)過長的運(yùn)行時(shí)間或增加過大的晶片體積。與VLIW類似的超標(biāo)量體系結(jié)構(gòu)也具備這一特性。
用戶應(yīng)用引擎的一種專用解決方案
下面來討論一個(gè)現(xiàn)實(shí)生活中的解決方案,該方案采用了三級不同的可定制性來構(gòu)造專門的用戶應(yīng)用引擎。
第一級可定制性在處理器的標(biāo)準(zhǔn)資源處提供,這些標(biāo)準(zhǔn)資源包括算術(shù)邏輯單元(ALU)以及乘法器和累加器(MAC)等。對某些應(yīng)用而言MAC 用得較多,如基于快速傅立葉變換(FFT)的算法;還有一些則傾向于更多地采用ALU。這就提出了一個(gè)要求,對于不同的應(yīng)用,處理器應(yīng)有不同的資源組合,而不是將所有的應(yīng)用都分配到同樣的一組固定的資源中去。
例如,可以將一個(gè)MAC密集的算法分配到一個(gè)包含4 MAC、2 ALU、1 SHIFT的處理器中去,而將一個(gè)ALU密集的應(yīng)用分配給一個(gè)包含3 ALU、1 MAC、1 SHIFT的引擎。這種處理器資源分配的可定制性對許多普通應(yīng)用而言已經(jīng)綽綽有余,但對大多數(shù)與視頻相關(guān)的應(yīng)用來說還遠(yuǎn)遠(yuǎn)不夠,它們的要求更高,并且需要更多的運(yùn)算單元來加快運(yùn)行速度。
第二級可定制性允許向處理器添加DDCU協(xié)處理器。設(shè)計(jì)者先要對所需完成的應(yīng)用有一個(gè)大致的認(rèn)識,接著對該應(yīng)用進(jìn)行分析,將其中的一些專用函數(shù)分離出來,然后在硬件上專門針對這些函數(shù)進(jìn)行加速處理,即添加DDCU。此外,設(shè)計(jì)者還可以分析一下,采用工具組添加DDCU來加快運(yùn)行速度會對處理器的性能造成怎樣的潛在影響,以及在諸如此類的一些其他假設(shè)下會出現(xiàn)什么情況。
DDCU是一種適用于專用算法的計(jì)算單元。一旦設(shè)計(jì)者確認(rèn)了哪個(gè)算法需要用DDCU進(jìn)行硬件加速之后,就可以寫出實(shí)現(xiàn)該DDCU的RTL 代碼,并將其加入用戶應(yīng)用引擎。例如,在通用DSP中加入濾波DDCU,那么若用該DSP實(shí)現(xiàn)一個(gè)需要濾波的應(yīng)用,其表現(xiàn)出來的性能就會有所增強(qiáng)。
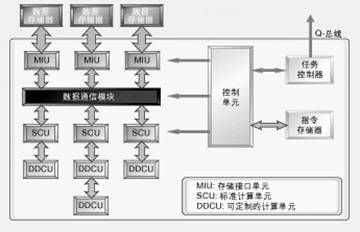
除此以外,設(shè)計(jì)者還要在增加并行性所帶來的性能優(yōu)化和該并行性對指令的影響之間尋找最佳平衡。為解決這一問題,可以在VLIW指令中定義分段的數(shù)目(從而定義最大并行度),并為每一段分別分配CU和DDCU(見圖1)。
最后一級可定制性表現(xiàn)在處理器資源的選擇上。設(shè)計(jì)者可以自己決定需要多大的數(shù)據(jù)存儲器,以及需要多少個(gè)數(shù)據(jù)寄存器和地址寄存器。而且,根據(jù)具體應(yīng)用所提出的數(shù)據(jù)要求,設(shè)計(jì)者還可以增加存儲器接口,以便提供并行數(shù)據(jù)訪問。這些共享的存儲器接口又可以用來連接多個(gè)處理器引擎,這就為處理器資源提供了一定的可伸縮性。
采用DSP引擎的一個(gè)關(guān)鍵的好處是可以加快產(chǎn)品投入市場的時(shí)間。但要達(dá)到這個(gè)目的,還要先定義一系列與DSP引擎協(xié)作的DDCU協(xié)處理器。在設(shè)計(jì)MPEG-4引擎的時(shí)候,首先要對其各個(gè)方面進(jìn)行全面分析,確定需要采用哪些DDCU。然后用這些DDCU構(gòu)建起一個(gè)大致MPEG-4引擎,分析其性能瓶頸,并針對性能瓶頸再定義一些DDCU加入引擎中,從而提高該引擎的性能,沖破其瓶頸。為了更方便地完成以上工作,人們開發(fā)出一個(gè)專門用于MPEG -4應(yīng)用的DDCU庫。以下討論了該庫中的某些專用DDCU。
1. 比特流/可變長度解碼DDCU
在視頻編碼中常常會遇到可變長度解碼。比特流/可變長度解碼DDCU 可以加快從輸入比特流中取出可變長度字段的速度,這是一種基本操作。如果用軟件來實(shí)現(xiàn)這種比特流管理,會消耗大量的時(shí)鐘周期來處理指針的移位、屏蔽和管理,而采用比特流/可變長度解碼DDCU則可以在一個(gè)簡單的硬件單元里快速完成同樣的功能。

在比特流/可變長度解碼DDCU中,由用戶設(shè)計(jì)的指令組集中完成普通比特的提取和插入操作。這種DDCU不但能加快處理速度,提高整個(gè)視頻引擎的性能,還可以解放處理器中的其他資源,使之得以用于周圍的其他處理過程。因此,采用這種DDCU不但可以減小指令長度,同時(shí)還增強(qiáng)了系統(tǒng)性能。實(shí)際上,在DSP中加入這種計(jì)算單元會使可變長度解碼的速度增快23.2%。
2. 量化/反量化DDCU
量化和反量化是視頻編解碼中的兩種基本操作,其計(jì)算量占整個(gè)視頻編解碼計(jì)算量的10%甚至更多。量化/反量化DDCU允許在單周期內(nèi)處理多像素,其內(nèi)部操作可以滿足多種MPEG-4等級的量化需求。在比特流/可變長度解碼DDCU中,將可變長度解碼模塊的計(jì)算需求降低15.4%時(shí),指令存儲空間也會減小,這一特性同樣適用于量化、反量化DDCU。
3. 半像素內(nèi)插/運(yùn)動補(bǔ)償DDCU
這種運(yùn)算單元用于加速半像素內(nèi)插操作,該操作所需計(jì)算量相當(dāng)大。在解碼器中,內(nèi)插/補(bǔ)償操作所消耗的時(shí)鐘周期約為總時(shí)鐘周期的40%。該單元中所涉及的運(yùn)算其實(shí)很簡單,只需要面積很小的硅片就能完成,因此很容易移入DDCU中去。就算是邊緣擴(kuò)展這樣的涉及大量計(jì)算的操作,只要不需要進(jìn)行優(yōu)化處理,也還是可以較好地移入硬件中。
不論采用哪種內(nèi)插類型,內(nèi)插/運(yùn)動補(bǔ)償DDCU中的指令組都允許每周期內(nèi)插4個(gè)像素,這一特性也減少了需要執(zhí)行的指令數(shù)。通過使用內(nèi)插/運(yùn)動補(bǔ)償DDCU,半像素內(nèi)插/運(yùn)動補(bǔ)償操作的速度可以增快74.6%。
4. DCT/IDCT DDCU
IDCT(反離散余弦變換)和DCT(離散余弦變換)都是視頻編碼中固有的運(yùn)算。眾所周知,這兩種運(yùn)算需要占用大量的時(shí)鐘周期,并要求在編寫其匯編代碼時(shí)非常小心。本文談到的這種專用DCT/IDCT DDCU單元(依據(jù)IEEE 1180-1990規(guī)范)可模仿DCT/IDCT中的“蝶形”運(yùn)算。通過使用這種計(jì)算單元可以大大提高視頻設(shè)計(jì)的性能和生產(chǎn)力,從而使開發(fā)人員能夠集中精力開發(fā)視頻應(yīng)用中的其他方面,以達(dá)到使其產(chǎn)品區(qū)別于其他同類產(chǎn)品的目的。
5. 運(yùn)動估計(jì)(MEMC)DDCU
MEMC單元用于幫助完成運(yùn)動估計(jì)這一計(jì)算量最大的操作。無線視頻應(yīng)用中,在每個(gè)運(yùn)動矢量的位置上都必須進(jìn)行誤差測量。MEMC DDCU可以完成兩種最常見的誤差測量計(jì)算:絕對誤差和(SAD)測量和平方誤差和(SSE)測量。DSP平臺中若加入該運(yùn)算單元,那么每周期誤差測量時(shí)所比較和累加的像素位置就可以多達(dá)4個(gè)。
6. 四分之一像素運(yùn)動補(bǔ)償單元
基本來說,該單元所提供的功能是對半像素內(nèi)插單元的一種必要的擴(kuò)展。四分之一像素算法比半像素算法稍微復(fù)雜一些,因?yàn)樗紫炔捎昧艘粋€(gè)2維FIR 濾波器來獲取半像素值,然后才使用線性插值法來計(jì)算四分之一像素值。這個(gè)2維濾波器直接并入半像素內(nèi)插單元,致使半像素內(nèi)插單元的硅片面積稍有增大,但這種方式仍然保持了較高的像素處理速度,這一速度遠(yuǎn)遠(yuǎn)超過只采用Simple Profile 設(shè)計(jì)的DSP引擎。
7. 全局運(yùn)動補(bǔ)償單元
在視頻應(yīng)用中有一種變形函數(shù)(warping function)專門用來描述當(dāng)前視頻對像相對于參考視頻對像的變化。全局運(yùn)動補(bǔ)償(GMC)單元就是為加速這種函數(shù)的運(yùn)算而設(shè)計(jì)的。該單元最大可支持 3點(diǎn)變形(即參考VOP的仿射變換)。一旦從比特流中分析出變形點(diǎn)的個(gè)數(shù)后,就用這個(gè)數(shù)值來初始化GMC。GMC計(jì)算變形等式的速度遠(yuǎn)遠(yuǎn)快于純軟件實(shí)現(xiàn)方式的計(jì)算速度。
8. 語境自適應(yīng)算法編/解碼DDCU
構(gòu)成語境需要進(jìn)行逐位操作,而逐位操作只能在標(biāo)準(zhǔn)的32位DSP中實(shí)現(xiàn)。為了打破這一限制,語境自適應(yīng)算法編/解碼DDCU采用硬件方法形成語境值。該DDCU內(nèi)部有一個(gè)查找表,用于存放所有可能的語境值,以便快速查找判斷。語境自適應(yīng)編解碼運(yùn)算單元支持以1b/周期的速度進(jìn)行算法編、解碼。
怎樣創(chuàng)建一個(gè)工作平臺
設(shè)計(jì)者定義了需要用到的DDCU之后,就可以用它們來創(chuàng)建滿足其特殊要求的用戶應(yīng)用引擎,并由此構(gòu)建起工作平臺,從而設(shè)計(jì)出具有MPEG-4視頻功能的產(chǎn)品。
為清楚起見,讓我們來看一個(gè)例子,例中的引擎是專門針對可傳送MPEG-4信息的3G移動電話設(shè)計(jì)的。這樣的引擎要想在3G移動電話上實(shí)現(xiàn)預(yù)期的視頻功能,就必須以低于20MHz的速度處理第1級和第2級MPEG-4簡單視覺等級,這樣才能為諸如音頻和語音處理等其他DSP功能留有一定的可規(guī)劃帶寬。
在開始設(shè)計(jì)用戶DSP時(shí),分配1 ALU、1 SHIFT和1MAC單元作為起始基準(zhǔn)平臺是比較合理的。要想增加并行性,只需將這些計(jì)算單元再分配給兩個(gè)單獨(dú)的指令段:ALU和SHIFT分配給同一段, MAC分配給另一段。如果該視頻應(yīng)用采用的是幀處理速度為每秒15幀的CIF格式,那么要在這個(gè)用戶平臺上編譯視頻應(yīng)用程序就需要40MHz的帶寬,若采用QCIF格式則只需10MHz帶寬。盡管這樣的帶寬已經(jīng)很具競爭力了,但仍然不能滿足前面提到的具有MPEG-4功能的3G移動電話的需要。
降低帶寬要求的解決方案
首先,要分析在用戶平臺中加入不同的計(jì)算單元對其性能的影響(這些計(jì)算單元全部來自MPEG-4 DDCU庫)。也就是說,我們定義了一系列的引擎,以此分析不同的計(jì)算單元混用方式所造成的性能影響。分析表明,應(yīng)該保留兩段型引擎定義,因?yàn)檫@可以限制指令寬度,使之不至于過寬。
然后再定義一些新的引擎,經(jīng)過編譯,分析其結(jié)果。新引擎定義分析的整個(gè)過程用了1或2個(gè)小時(shí)。由于DDCU庫是提前創(chuàng)建好的,因此許多引擎可以在一天時(shí)間內(nèi)就分析完。接著從這些引擎中選出最能滿足目標(biāo)產(chǎn)品要求的,用來構(gòu)建工作平臺。
這樣得到的工作平臺與基準(zhǔn)平臺相比,增加了一個(gè)ALU和四個(gè)MPEG-4 DDCU:比特流DDCU、量化/反量化DDCU、半像素DDCU和DCT/IDCT DDCU(見圖2)。在起始平臺的基礎(chǔ)上添加這些運(yùn)算單元,目的就是在不增大指令存儲或數(shù)據(jù)存儲的前提下,盡可能降低對時(shí)鐘速率(MHz)的要求。完成這些操作之后,我們得到了這樣一個(gè)用戶應(yīng)用引擎,該引擎可以用帶寬只有18MHz的DSP完成每秒15幀的CIF格式圖像的解碼,同時(shí)還能滿足這種3G無線視頻應(yīng)用的其他關(guān)鍵要求(低功率、小晶片尺寸以及低時(shí)鐘速率)。
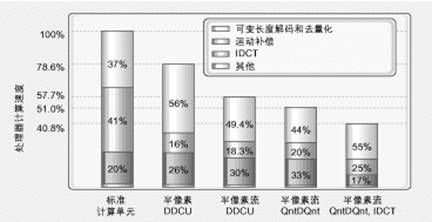
從圖3中可以看出DDCU對加快整個(gè)應(yīng)用運(yùn)行速度的作用。圖中第一條表示在標(biāo)準(zhǔn)CU構(gòu)成的基準(zhǔn)平臺上,整個(gè)運(yùn)算時(shí)間在IDCT、運(yùn)動補(bǔ)償(MC)以及可變長度編碼和反量化(VLD/DQnt)這幾種DDCU之間的分布情況。
可以看出,在這幾種DDCU中,MC部分占用時(shí)鐘周期最多。因此我們在工作平臺上添加了一個(gè)DDCU來加速半像素內(nèi)插操作,提高M(jìn)C部分的速度。一旦MC部分所占用的時(shí)鐘周期數(shù)大幅降低,VLD/DQnt馬上就上升成為了限制整個(gè)應(yīng)用性能的最主要因素。針對這一情況,再添加一個(gè)比特流 DDCU和一個(gè)量化/反量化DDCU,又進(jìn)一步提高了性能。這樣,最初的基準(zhǔn)平臺已經(jīng)經(jīng)過了兩次組合。此時(shí),再將IDCT DDCU加入其中,整個(gè)應(yīng)用的性能就得到了更大的提高。圖3中的最后一條給出了三次組合后整個(gè)應(yīng)用需要耗費(fèi)的時(shí)鐘周期。
上面介紹的只是一個(gè)典型案例。一般而言,在無線視頻應(yīng)用的開發(fā)中,按照以上這幾步進(jìn)行操作,我們就可以快速地構(gòu)造一個(gè)優(yōu)化的引擎,為移動電話或PDA設(shè)備開發(fā)出收發(fā)MPEG-4視頻信息的功能。更妙的是,在構(gòu)造起這個(gè)引擎的同時(shí)還可以解放一部分處理器資源,使之有余力去支持其他的一些新興功能,比如MP3音頻、網(wǎng)絡(luò)瀏覽,甚至更多。