
??? 摘 要:針對重復記錄清理中的“排序、識別、合并”算法存在的問題進行了改進。改進后的重復記錄清理算法在保證記錄匹配率的情況下有效地提高了記錄排序的效率;在重復記錄識別時,考慮了匹配字段的文字數(shù)量、在2個字段中出現(xiàn)的頻率、在記錄中各字段的重要性(權(quán)重)、中文字段的語義和語義重點偏后等5個因素;合并重復記錄時采用了聚類和實用算法并用的策略,有效地提高了數(shù)據(jù)倉庫中重復記錄清理算法的準確性和健壯性。
??? 關(guān)鍵詞:數(shù)據(jù)清理;重復記錄清理;重復記錄識別;數(shù)據(jù)倉庫
?
??? 目前,國內(nèi)外已經(jīng)有一些對數(shù)據(jù)清理的研究,由于中文數(shù)據(jù)之間沒有以空格分割,這在識別上帶來了一定的難度,因此大部分的研究都只針對英文的數(shù)據(jù)清理,涉及中文數(shù)據(jù)清理的研究較少。重復數(shù)據(jù)清理技術(shù)旨在清除冗余的備份數(shù)據(jù)、確保只有“獨有的”數(shù)據(jù)存儲在磁盤上,即容量優(yōu)化保護技術(shù)。重復數(shù)據(jù)清理技術(shù)的關(guān)鍵是只保留唯一的數(shù)據(jù)實例,有效地解決了“容量膨脹”的效率問題[1]。
??? 從數(shù)據(jù)清理算法研究內(nèi)容上講,重復數(shù)據(jù)清除算法可分為兩類:一類是數(shù)據(jù)清理的記錄間算法,一類是數(shù)據(jù)清理的記錄內(nèi)算法。目前,研究人員對第一類算法研究得比較多,如:滑動窗口算法[2]、優(yōu)先隊列算法[3]等;對第二類算法的研究一般都是直接引用字符串相似匹配算法[4],這種算法的缺點是沒有考慮到字段不等長、中文字段語義重點偏后等重復記錄的特點。
1 重復記錄排序算法的改進
??? 重復記錄清理的直觀方法是將每一個記錄與數(shù)據(jù)庫中其余記錄逐個進行對比,該方法的識別精度非常高,但是在數(shù)據(jù)量較大的情況時,其處理時間會讓用戶難以忍受。鄰近排序算法(SNM)[5]是目前常用的一種排序方法,它有效地克服了直觀方法的缺點,大大提高了重復記錄的匹配效率和重復記錄清理的完成效率。但是,SNM算法存在其匹配結(jié)果嚴重依賴于排序關(guān)鍵字的選擇和滑動窗口大小W的選取很難控制等缺陷。由于在SNM算法里記錄只能與窗口內(nèi)的紀錄進行比較,當W太小時或排序的關(guān)鍵字選擇不當時,會造成漏配;而當W太大時又會產(chǎn)生很多沒有必要的比較,因此恰當?shù)腤無論如何都無法得到。
??? 本節(jié)針對SNM算法存在的上述缺陷作了改進,改進后算法的基本思想是使用相對較小的滑動窗口,選擇數(shù)據(jù)庫的一個關(guān)鍵字執(zhí)行SNM算法,存儲本次排序后相似記錄的序號,然后依次選擇數(shù)據(jù)庫中的其他關(guān)鍵字獨立地執(zhí)行SNM算法,并在每次執(zhí)行完畢后把此次執(zhí)行結(jié)構(gòu)中新增的相似記錄號添加到相似記錄存儲表中得到所有可能重復記錄的序號,然后對對這些可能的重復記錄采用直觀方法進行清理。
??? 改進后的SNM算法的偽碼描述如下:
??? while(還有沒用過的關(guān)鍵字)
??? do{
??? 為記錄集TS中的記錄選擇該趟排序需要的排序關(guān)
??? 鍵字;
??? 根據(jù)排序關(guān)鍵字對TS中的記錄進行排序;
??? 滑動窗口W從TS的第一個記錄開始滑動;
??? while(W沒有滑動到TS的尾部)
??? do{
??? 初始化執(zhí)行對比的次數(shù)n=0;
??? while(執(zhí)行的對比次數(shù)n<|W|)
??? do{
??? 新進入滑動窗口的記錄與第n+1個進入窗口的記錄進行重復記錄比較;
??? if(比較的記錄為相似重復記錄)
??? {
??? 把相似重復記錄的記錄號添加到相似記錄存儲表;
??? }
??? 執(zhí)行n+1;
??? }
??? 向下滑動窗口;
??? }
??? 對相似記錄存儲表中的記錄采用直觀方法進行比較,記錄相似重復記錄聚類;
??? }
2 識別算法" title="重復記錄識別算法">重復記錄識別算法的改進
??? 記錄排好序后,下一個要解決的問題是如何判斷兩條記錄是否為相似重復記錄。識別重復記錄首先需要進行字段相似度的計算,然后再根據(jù)字段的權(quán)重進行加權(quán)和計算后得到記錄的相似度,最后進行記錄相似度和所設(shè)定閥值的比較,如果兩條記錄的相似度小于閥值,則認為這兩條記錄匹配,否則認為是兩個不同的記錄。基于相似度的重復記錄識別算法[1]是最常用的一種重復記錄識別方法,但是恰當閾值的設(shè)定仍是一個沒有解決的難題。若閾值設(shè)定的過小,則容易遺漏某些相似的重復記錄,從而降低了算法的匹配率;若閾值設(shè)定的過大,則容易將某些不同的記錄誤判為相似重復記錄,從而降低了算法的正確率。此算法對記錄的識別僅使用一個單一的閾值過于絕對,且沒有考慮文中語句語義偏后的特點,無法滿足實際情況的要求。
??? 下面針對基于相似度的重復記錄識別算法存在的上述問題對此算法進行了適當改進,給出了一種基于雙閾值[6]位置權(quán)重[7]的語義重復記錄識別算法。本算法的具體描述如下:對記錄相似度設(shè)定一大一小兩個閾值δup和δlow,當通過位置權(quán)重識別法計算出當前兩條記錄的相似度大于δup,則直接判定它們是重復記錄;若計算出的相似度小于δlow,則可以判定它們是兩個不同的記錄;而對于相似度在δup和δlow之間的兩條記錄,則不能直接確定它們是否重復或不重復,需要通過語義重復識別法[3],[8]進行判定;對仍無法判定的記錄則需人工進行處理。根據(jù)參考文獻[9]一般閾值取0.37和0.68,為了提高準確率本文第一次相似度計算取閾值為0.35和0.7。
??? 簡單的字段識別法只考慮了字段之間的字符的匹配度,而忽略了匹配字符所在的位置(稱為匹配序)。由于大部分中文尤其是特定領(lǐng)域的專業(yè)術(shù)語的語義重點往往集中在字段的后半部分字符串中,通過調(diào)整字段的匹配度和匹配序的權(quán)重(記作α和β,滿足α+β=1),則可以在很大程度上提高字段識別的準確率。具體定義如下:
??? 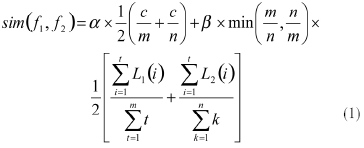
??? 其中,f1和f2分別為兩個中文字段(如果字段中有英文字母,則將連續(xù)的英文字母視作一個漢字),m和n分別為f1和f2的字數(shù),c為f1和f2的識別字符數(shù)量,L1(i)和L2(i)分別為識別字符i在f1和f2中的匹配序。匹配序按照從左到右的順序,從1開始自然數(shù)遞增的方式計算,而α和β則一般根據(jù)黃金分割律來確定,分別取0.6和0.4[10]。例如,f1=“燕大電氣工程學院”、f2=“燕山大學電氣工程學院”,下面通過位置權(quán)重識別法判定S1和S2是否為重復字段。和的匹配字符為“燕”、“大”、“電”、“氣”、“工”、“程”、“學”、“院”,它們在f1中的匹配序依次為“1、2、3、4、5、6、7、8”,在f2中的匹配序依次為“1、3、5、6、7、8、9、10”。那么f1和f2的語義相似度為:
??? 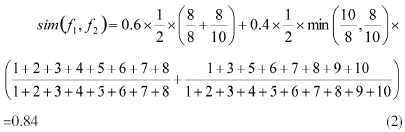
??? 基于語義距離的相似度識別方法體現(xiàn)了字段內(nèi)部的結(jié)構(gòu)和詞語之間語義的相互作用關(guān)系,而編輯距離由于同義詞詞林的應用可以兼顧同義詞之間的替換,并體現(xiàn)了組成句子的每個詞深層的語義信息。基于語義距離的相似度識別算法的基本思路是:首先,利用參考文獻[11]中介紹的骨架依存樹思想分析字段的語法結(jié)構(gòu),得到字段中所有的核心詞和直接依存于它們的有效詞組成的搭配對(有效詞定義為動詞、名詞和形容詞,它是由分詞后的詞性標注決定的),然后再進行語義距離(為兩個字段有效搭配對的最短距離)的相似度計算,最后根據(jù)閾值進行重復識別判斷。
??? 設(shè)f1和f2為需要識別的兩字段,f1包含的詞為f11、f12、…、f1m,f2包含的詞為f21、f22、…、f2n,則詞f1i(1≤i≤m)和f2j(1≤j≤n)之間的相似度可用sim( f1, f2)來表示,這樣就得到兩個字段中任意搭配對的相似度,f1和f2兩字段之間的語義相似度sim( f1, f2)的計算公式如下:
??? 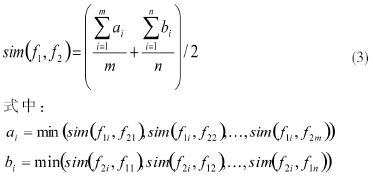
??? 使用雙閾值位置權(quán)重的語義識別法,雖然在一定程度上增加了用戶的工作量,降低了算法的效率,但同時提高了算法的正確性和健壯性;而把位置權(quán)重和基于語義距離的相似度識別兩種方法結(jié)合起來,揚長避短、互為補充,根據(jù)這些特征計算字段之間的相似度,可以使本重復識別算法獲得很高的準確率。通過以上分析可知,本節(jié)對重復識別算法的改進是有效的、值得的。
3 重復記錄合并算法的改進
??? 在相似重復記錄的識別完成以后,下一步要做的工作就是選擇合適的方法合并識別出來的相似重復記錄。參考文獻[8]、[12]介紹了目前常用的多種重復記錄合并方法,它們在合并方面各有利弊,單獨使用都無法得到很好的效果,下面對此進行改進。
??? 針對上述缺點,本節(jié)采用實用兼人工策略,給出了一種實用和聚類算法結(jié)合的合并算法。從一組相似重復記錄中選擇與其它記錄匹配次數(shù)最多的一條記錄進行保留,如果多個不同的記錄具有相同的匹配率,則對這些相似記錄進行聚類(會通過屏幕把聚類結(jié)果返回給用戶),由用戶人工確定要保留的記錄,并把其他重復記錄從數(shù)據(jù)庫中刪除。
??? 針對現(xiàn)有的重復記錄清理策略存在的問題,分析了其原因,找出了現(xiàn)有重復記錄清理策略里記錄排序、重復記錄識別、重復記錄合并各步驟中所用算法存在的缺陷,給出了各自的改進方案,并通過算法分析和舉例說明證明了改進的合理性。改進后的重復記錄清理算法可以有效地提高判斷質(zhì)量,減小誤判率,縮短了重復記錄處理時間,很好地保障了數(shù)據(jù)倉庫數(shù)據(jù)的質(zhì)量。
參考文獻
[1]?LIN De Kang. An Information-theoretic Definition of Similarity[C]//Proc. Of the 15th Intermational Conf. on Machine Learning. San Francisco,CA,USA:Morgan Kaufmann,1998.
[2]?MONGE A. E, ELKAN? C. An Efficient Domain-Independent Algorithm for Detecting Approximately Duplicate Database Records.DMKD,1997.
[3]?GUTTMAN A. R-trees? a dynamic index structure for spatial searching Proc. ACM SIGMOD Int Conf on Management of Data, 1984,47-57.
[4]?馮玉才,桂浩,李華,等. 數(shù)據(jù)分析和清理中相關(guān)算法研究[J]. 小型微型計算機系統(tǒng), 2005,26(6):1018-1022.
[5] HEMANDEZ, M? A, STOLFO? S? J. The Merge/Purge Problem for Large Database[C].In SIGMOD Conference,1995:127-138.
[6]?洪圓,孫未未,施伯樂. 一種使用雙閥值的數(shù)據(jù)倉庫環(huán)境下重復記錄消除算法[J]. 計算機工程與應用,2005,1:168-170.
[7]?張雪英,閭國年. 基于字面相似度的地理信息分類體系自動轉(zhuǎn)換方法[J].遙感學報,2008,12(3):433-440.
[8] 劉寶艷,林鴻飛,趙晶.基于改進編輯距離和依存文法的漢語句子相似度計算[J].計算機應用與軟件,2008,25(7):33-34.
[9]?陳偉. 數(shù)據(jù)清理關(guān)鍵技術(shù)及其軟件平臺的研究與應用[D]. 南京航空航天大學,2004.
[10]?王源,吳小濱,涂從文,等.后控制規(guī)范的計算機處理[J].現(xiàn)代圖書情報技術(shù),1993,2:4-7.
[11]?趙妍妍,秦兵,劉挺,等. 基于多特征融合的句子相似度計算 [A]. 全國第八屆計算語言學聯(lián)合學術(shù)會議(JSCL-2005)論文集[C],2006.
[12]?DAVIDSON? S? B,? KOSKY? A? S. Specifying Database Transformations in WOL[J].Data Engineering, 1999 ,22(1):25-31.