
摘 要: 提出一種在雙目視覺(jué)的條件下,利用光流金字塔跟蹤算法跟蹤關(guān)節(jié)點(diǎn),以解決傳統(tǒng)光流不能進(jìn)行大幅度運(yùn)動(dòng)跟蹤的問(wèn)題,并利用極線約束進(jìn)行三維重建獲得深度信息,結(jié)合對(duì)消失關(guān)節(jié)點(diǎn)的位置預(yù)測(cè)求出相應(yīng)的三維坐標(biāo),再利用層次化的描述方法將三維坐標(biāo)轉(zhuǎn)化為三維模型中各個(gè)關(guān)節(jié)點(diǎn)的旋轉(zhuǎn)角度,實(shí)現(xiàn)對(duì)人體運(yùn)動(dòng)的模型描述。實(shí)驗(yàn)結(jié)果表明,該算法能有效地對(duì)人體的運(yùn)動(dòng)進(jìn)行描述。
關(guān)鍵詞: 人體三維模型;光流金字塔;極線約束;層次化描述
人體的運(yùn)動(dòng)包含了相當(dāng)豐富的信息,如從人體運(yùn)動(dòng)當(dāng)中可以看出其動(dòng)作、姿態(tài);根據(jù)目前的運(yùn)動(dòng)可以推測(cè)它在未來(lái)某個(gè)時(shí)刻的位置、速度;可以看出它的表情、神態(tài);可以了解一個(gè)人的個(gè)性等。正因?yàn)槿绱耍瑢?duì)人體運(yùn)動(dòng)的研究有著相當(dāng)廣闊的應(yīng)用空間,如視頻監(jiān)控、運(yùn)動(dòng)分析檢測(cè)、虛擬現(xiàn)實(shí)、動(dòng)畫制作等。而其中關(guān)于人體關(guān)節(jié)點(diǎn)的運(yùn)動(dòng)跟蹤檢測(cè)以及人體運(yùn)動(dòng)姿勢(shì)的三維重建更是其研究的熱門話題。人體姿勢(shì)的三維重建可以按照視點(diǎn)的個(gè)數(shù)分為基于單視點(diǎn)的三維重建[1]和基于多視點(diǎn)的三維重建。基于單視點(diǎn)三維重建的優(yōu)點(diǎn)在于它使用方便,可以在大多數(shù)的場(chǎng)合中使用,限制的條件較少,只需要一個(gè)攝像機(jī)或其他輸入設(shè)備。缺點(diǎn)是由于只有一個(gè)視點(diǎn),得不到相應(yīng)的深度信息,所以當(dāng)有自遮擋的情況時(shí)會(huì)產(chǎn)生匹配的模糊性問(wèn)題。而基于多視點(diǎn)的三維重建可以部分解決這個(gè)問(wèn)題。與單視點(diǎn)相比,多視點(diǎn)易于進(jìn)行三維重建,但多視點(diǎn)的跟蹤同樣存在特征對(duì)應(yīng)及自遮擋等難點(diǎn),而且多視點(diǎn)的自動(dòng)對(duì)應(yīng)也是目前比較有難度的一個(gè)課題。其中對(duì)于基于多視點(diǎn)的人體姿勢(shì)三維重建,大體上可以分為利用機(jī)器學(xué)習(xí)的方法和目標(biāo)跟蹤的方法兩種。通過(guò)機(jī)器學(xué)習(xí)的方法,可以利用大量的先驗(yàn)知識(shí)來(lái)獲得更加準(zhǔn)確的有關(guān)三維人體姿勢(shì)的估計(jì)。然而,該方法需要大量的樣本數(shù)據(jù),使用起來(lái)十分不方便而且費(fèi)時(shí),在一定程度上限制了它的應(yīng)用。目標(biāo)跟蹤的方法主要由兩個(gè)步驟組成:首先是在每一幀中為每一個(gè)特征點(diǎn)定位,并且在每一幀中跟蹤相應(yīng)的特征點(diǎn);然后是通過(guò)獲得特征點(diǎn)來(lái)對(duì)人體姿勢(shì)進(jìn)行三維重建。本文提出一種在兩個(gè)攝像機(jī)的條件下,利用金字塔光流的方法對(duì)關(guān)節(jié)點(diǎn)進(jìn)行跟蹤檢測(cè),并利用極線約束進(jìn)行三維重建,對(duì)運(yùn)動(dòng)過(guò)程中被遮擋的關(guān)節(jié)點(diǎn)進(jìn)行預(yù)測(cè)處理,最后將求出的關(guān)節(jié)點(diǎn)三維坐標(biāo)轉(zhuǎn)化成模型中的旋轉(zhuǎn)角,通過(guò)層次化的描述,用人體模型來(lái)顯示相應(yīng)的動(dòng)作姿態(tài)。
1 算法主要思想
1.1 三維人體模型
將人體看成是由關(guān)節(jié)點(diǎn)及其連接線段所組成的剛體的集合。如下肢是由膝關(guān)節(jié)連接的大腿和小腿兩個(gè)剛體。以一條線段來(lái)表示一個(gè)剛體,將人體的運(yùn)動(dòng)簡(jiǎn)化為人體框架的運(yùn)動(dòng),這樣就得到一個(gè)三維人體框架模型[2],如圖1、圖2所示。該人體模型共包含16個(gè)人體關(guān)節(jié)點(diǎn),其中所有關(guān)節(jié)點(diǎn)之間的線段在任何時(shí)刻都不會(huì)發(fā)生形變,而且各個(gè)線段之間的長(zhǎng)短比例關(guān)系可以事先根據(jù)個(gè)體情況進(jìn)行適當(dāng)調(diào)整[3]。

1.2 光流金字塔跟蹤算法
傳統(tǒng)的Lucas-Kanade的光流算法[4]主要基于以下三個(gè)假設(shè):(1)亮度恒定,即圖像場(chǎng)景中目標(biāo)的像素在幀間運(yùn)動(dòng)時(shí)外觀上保持不變。對(duì)于灰度圖像,需要假設(shè)像素被逐幀跟蹤時(shí)其亮度不發(fā)生變化。(2)時(shí)間連續(xù)或運(yùn)動(dòng)是“小運(yùn)動(dòng)”,即圖像的運(yùn)動(dòng)隨時(shí)間的變化比較緩慢。在實(shí)際應(yīng)用中指的是時(shí)間變化相對(duì)圖像中目標(biāo)運(yùn)動(dòng)的比例要足夠小,這樣目標(biāo)在幀間的運(yùn)動(dòng)就比較小。(3)空間一致,即一個(gè)場(chǎng)景中同一表面上鄰近的點(diǎn)具有相似的運(yùn)動(dòng),它們?cè)趫D像平面的投影也在鄰近區(qū)域。但是由于受人體運(yùn)動(dòng)和圖像噪聲的影響,前后幀中對(duì)應(yīng)的特征點(diǎn)的亮點(diǎn)完全相等幾乎是不可能的,一方面是人體的運(yùn)動(dòng)往往幅度較大,光線難以保證均勻。另一方面由于運(yùn)動(dòng)會(huì)產(chǎn)生不可避免的遮擋,亮度甚至還會(huì)發(fā)生突變,因此傳統(tǒng)的方法在人體跟蹤中受到一定的局限。
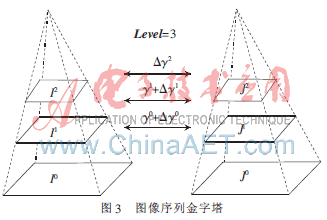
本文將對(duì)傳統(tǒng)的光流方法進(jìn)行改進(jìn),使用一種基于圖像金字塔的角點(diǎn)梯度光流計(jì)算方法對(duì)圖像序列中的角點(diǎn)進(jìn)行亞像素級(jí)跟蹤[5]。該方法的基本思想是:首先構(gòu)造如圖3所示的圖像序列的金字塔,金字塔中較高的層是下層圖像向下降采樣后的圖像,原始圖像的層數(shù)為零。當(dāng)圖像分解到一定的層后,相鄰幀的圖像間運(yùn)動(dòng)幅度就變得足夠小,就會(huì)滿足光流的幾個(gè)約束條件,此時(shí)便可進(jìn)行光流計(jì)算。由高層向低層進(jìn)行計(jì)算,當(dāng)某一級(jí)的光流增量計(jì)算出來(lái)后,將加到其初始值上,作為其下一層的光流計(jì)算初值。這一過(guò)程持續(xù)進(jìn)行直到估計(jì)出原始圖像的光流。


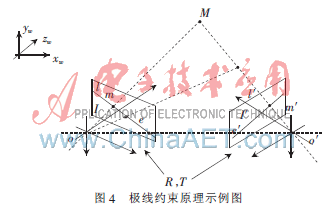
1.4 層次化描述
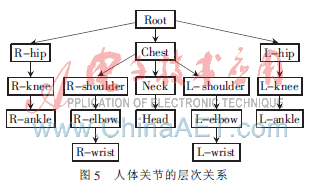
對(duì)于運(yùn)動(dòng)描述,本文使用一種層次化的運(yùn)動(dòng)描述方法[8],把人體模型看成是類似樹的結(jié)構(gòu),如圖5所示。樹的根節(jié)點(diǎn)是Root點(diǎn),其他子節(jié)點(diǎn)對(duì)應(yīng)人體模型中的各個(gè)關(guān)節(jié)點(diǎn)。整個(gè)人體的運(yùn)動(dòng)可以看成是由平移和旋轉(zhuǎn)組成的,Root點(diǎn)的旋轉(zhuǎn)決定人體模型所對(duì)應(yīng)的方向,人體的平移即為Root點(diǎn)的位移量,其他各節(jié)點(diǎn)的旋轉(zhuǎn)是在以父節(jié)點(diǎn)為坐標(biāo)原點(diǎn)的相對(duì)坐標(biāo)系下的旋轉(zhuǎn)。各個(gè)關(guān)節(jié)點(diǎn)的位置可以根據(jù)各個(gè)關(guān)節(jié)點(diǎn)間的線段長(zhǎng)度和旋轉(zhuǎn)向量求出,而關(guān)節(jié)點(diǎn)間的線段長(zhǎng)度可作為先驗(yàn)知識(shí)獲得。圖中的節(jié)點(diǎn)R_ankle,其位置與旋轉(zhuǎn)平移向量的對(duì)應(yīng)關(guān)系為:

在已經(jīng)知道每個(gè)關(guān)節(jié)點(diǎn)的運(yùn)動(dòng)除了包括繞父節(jié)點(diǎn)旋轉(zhuǎn)外,還包括隨父節(jié)點(diǎn)繞祖父節(jié)點(diǎn)旋轉(zhuǎn)和平移。因此,三維數(shù)據(jù)向旋轉(zhuǎn)平移數(shù)據(jù)轉(zhuǎn)化的關(guān)鍵是在各個(gè)非葉子節(jié)點(diǎn)處建立以該非葉子節(jié)點(diǎn)為原點(diǎn)的參考坐標(biāo)系。以人體上臂為例來(lái)說(shuō)明旋轉(zhuǎn)數(shù)據(jù)的計(jì)算方法。由于三維數(shù)據(jù)中沒(méi)有考慮扭矩的作用,可假設(shè)繞軸的運(yùn)動(dòng)分量為0;假設(shè)旋轉(zhuǎn)方向?yàn)橄壤@z軸旋轉(zhuǎn)β,再繞y軸旋轉(zhuǎn)θ。然后,將三維數(shù)據(jù)(x,y,z)變換到上臂參考坐標(biāo)系下,其坐標(biāo)為(m1,m2,m3),則參考坐標(biāo)系下的三維數(shù)據(jù)(m1,m2,m3)與參考坐標(biāo)系下的上臂初始位置(-l,0,0)之間的關(guān)系可以描述為[10]:

以此類推,可以計(jì)算出人體各個(gè)關(guān)節(jié)點(diǎn)的旋轉(zhuǎn)分量,其實(shí)現(xiàn)效果如圖6所示。

2 實(shí)驗(yàn)結(jié)果
根據(jù)本文提出的算法,使用VC++開(kāi)發(fā)一個(gè)人體運(yùn)動(dòng)跟蹤描述系統(tǒng),可運(yùn)行在Windows平臺(tái)上。實(shí)驗(yàn)中的視頻是使用兩個(gè)具有平行光軸的攝像機(jī)拍攝而成。圖7是拍攝的一段圖像序列的跟蹤結(jié)果以及恢復(fù)出的三維骨架序列。

本文提出一種雙目視覺(jué)下的三維人體運(yùn)動(dòng)描述算法。該算法魯棒性較高,因?yàn)槌觅N在人體關(guān)節(jié)處的用于構(gòu)建三維標(biāo)記點(diǎn)的白色標(biāo)記點(diǎn)之外,沒(méi)有利用圖像上的其他特征。實(shí)驗(yàn)結(jié)果表明,該算法能有效地對(duì)人體運(yùn)動(dòng)進(jìn)行描述,并且當(dāng)有比較大幅度的運(yùn)動(dòng)及遮擋的情況時(shí),依然可以較好地跟蹤和預(yù)測(cè)關(guān)節(jié)點(diǎn)位置,并進(jìn)行重建顯示。未來(lái)的工作是要加入更多的人體約束和運(yùn)動(dòng)學(xué)約束以消除動(dòng)作的多義性,進(jìn)一步提高描述的準(zhǔn)確性和魯棒性。
參考文獻(xiàn)
[1] Zou Beiji, Chen Shu, Cao Shi, et al. Automatic reconstruction of 3D human motion pose from uncalibrated monocular video sequences based on markerless human motion tracking[J]. Pattern Recognition, 2009,42:2.
[2] 劉小明,莊越挺,潘云鶴.基于模型的人體運(yùn)動(dòng)跟蹤[J].計(jì)算機(jī)研究與發(fā)展,1999,36:10.
[3] SHEN B C, SHIH H C, HUANG C L. Real-time human motion capturing system[C]. Proceedings of IEEE Interna-
tional Conference on Image Processing, 2005:11-14.
[4] 張永亮,盧煥章,高劼,等.一種改進(jìn)的Lucas-Kanade光流估計(jì)方法[J].海軍航空工程學(xué)院學(xué)報(bào),2009,24(4):444-445.
[5] 陳樂(lè),呂文閣,丁少華.角點(diǎn)檢測(cè)技術(shù)研究進(jìn)展[J].自動(dòng)化技術(shù)與應(yīng)用,2005,24(5):1-4.
[6] 張娟,潘建壽,吳亞鵬,等.基于雙目視覺(jué)的運(yùn)動(dòng)目標(biāo)跟蹤與測(cè)量[J].計(jì)算機(jī)工程與應(yīng)用,2009,45(25):191-193.
[7] 蔡濤,李德華,朱洲,等.基于彩色圖像序列的特征檢測(cè)和跟蹤[J].計(jì)算機(jī)工程,2005,31(8):12-13.
[8] Chen Yisheng, LEE J, PARENT R, et al. Markerless monocular motion capture using image features and physical constraints[C]. Proceedings of Computer Graphics International. Washington DC: IEEE Computer Society, 2005:36-43.
[9] KIM S M, PARK C B, LEE S W. Tracking 3D human body using particle filter in moving monocular camera[C].Proceedings of the 18th International Conference on Pattern Recognition. 2006:805-808.
[10] SILAGHI M, PLAENKERS R, BOULIC R, et al. Local and global skeleton fitting techniques for optical motion capture[C]. Proceedings of International Workshop on Modelling and Motion Capture Techniques for Virtual Environments. London: Spirnger-Verlag,1998:26-40.