
摘? 要: GM是Myrinet專用的系統(tǒng)軟件,由于采用了用戶層通信、在LANai上運(yùn)行MCP等機(jī)制,故具有占用系統(tǒng)開銷小、延遲短、帶寬大等優(yōu)點(diǎn),在國(guó)外已廣泛應(yīng)用于并行計(jì)算領(lǐng)域。
關(guān)鍵詞: Myrinet? GM? 用戶層通信? LANai
?
1 GM簡(jiǎn)述
GM是美國(guó)MyriCom公司為其高性能網(wǎng)絡(luò)產(chǎn)品Myrinet而推出的系統(tǒng)軟件,專門用于網(wǎng)絡(luò)并行計(jì)算,在國(guó)外已廣泛應(yīng)用于大規(guī)模并行計(jì)算領(lǐng)域。
GM的設(shè)計(jì)思想就是要實(shí)現(xiàn)一種高帶寬低延遲,主機(jī)開銷極少的通信方式。GM的高效率,除了采用用戶層通信機(jī)制等以外,關(guān)鍵在于充分配合Myrinet在硬件架構(gòu)上的特性。GM在Myrinet網(wǎng)卡的LANai芯片上運(yùn)行MCP,承擔(dān)了大部分的通信處理工作,大大減輕了主機(jī)的通信開銷。總的來說,GM具有如下特性:
·支持超過1000個(gè)節(jié)點(diǎn);
·可在不可靠網(wǎng)絡(luò)環(huán)境中提供可靠、有序的數(shù)據(jù)傳輸服務(wù);
·低開銷,每個(gè)數(shù)據(jù)包只耗費(fèi)主機(jī)大約1μs的處理時(shí)間;
·通過提供高低兩個(gè)優(yōu)先級(jí),可實(shí)現(xiàn)高效的防死鎖算法;
· 對(duì)多個(gè)用戶層程序直接訪問網(wǎng)絡(luò)接口提供存儲(chǔ)保護(hù);
· 理論上支持的消息長(zhǎng)度可達(dá)231-1字節(jié),實(shí)際則受限于主機(jī)DMA內(nèi)存大小;
· 自動(dòng)對(duì)Myrinet進(jìn)行映射,解決路由問題。
GM的不足之處在于編程模式不靈活和不支持多線程。
2 GM的結(jié)構(gòu)
GM由MCP,DRIVER,LIBGM三部分構(gòu)成。這三部分之間的關(guān)系可以用圖1來描述。

LIBGM為用戶程序提供編程接口,其中最重要的是發(fā)送和接收函數(shù)。此外,還提供一整套通用函數(shù),如初始化、DMA內(nèi)存管理、令牌管理、哈希管理、CRC校驗(yàn)等。
LIBGM 所實(shí)現(xiàn)的功能可分成三類:第一類是通用函數(shù),如哈希管理;第二類是通過DRIVER實(shí)現(xiàn)的功能,如內(nèi)存映射功能;第三類是和MCP協(xié)同完成的功能,如發(fā)送和接收操作。其中第三類是完成數(shù)據(jù)通信功能的核心。為提高整個(gè)系統(tǒng)的性能,LIBGM和MCP之間的交互都繞開了操作系統(tǒng),避免了包括在用戶態(tài)和核心態(tài)之間的切換,從用戶空間到核心空間數(shù)據(jù)拷貝等在內(nèi)的各種開銷。因此,從發(fā)送和接收操作的路徑上看,GM采用的是用戶層通信。
DRIVER是GM中的一個(gè)重要部分。其最主要的功能是完成MCP的初始化,其次是提供一些輔助性的功能。以Linux + x86平臺(tái)為例,DRIVER以Module的形式實(shí)現(xiàn),當(dāng)被加載到內(nèi)核的時(shí)候,DRIVER同時(shí)完成一系列初始化工作,包括:查找并自動(dòng)配置PCI網(wǎng)卡設(shè)備,把MCP從主機(jī)加載到LANai的EPROM上,并且對(duì)LANai進(jìn)行初始化,對(duì)LANai發(fā)出reset指令,驅(qū)動(dòng)MCP運(yùn)行。LIBGM通過調(diào)用DRIVER的ioctl功能來完成各種輔助功能。
MCP 是GM最關(guān)鍵的部分,GM的其他功能都是在MCP的基礎(chǔ)上構(gòu)架起來的。MCP運(yùn)行在Myrinet的網(wǎng)卡的LANai芯片上,它由DRIVER加載到LANai上。MCP借助LANai上的CPU和SRAM承擔(dān)了大部分的通信處理工作,包括:在主機(jī)內(nèi)存和LANai SRAM之間的數(shù)據(jù)DMA傳送、數(shù)據(jù)包的拆分和組裝、CRC校驗(yàn)、通信的應(yīng)答管理、端口和令牌資源的分配、調(diào)度管理等。因此,主機(jī)方面的通信開銷幾乎為零。
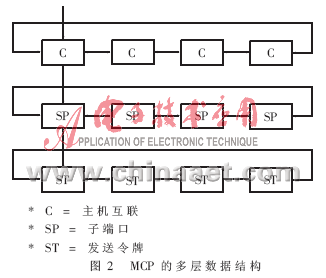
網(wǎng)卡上的SRAM主要用作發(fā)送和接收數(shù)據(jù)的緩沖。MCP采取端口(port)、優(yōu)先級(jí)(Priority)和發(fā)送/接收令牌(Token)等手段來實(shí)現(xiàn)資源的控制、分配和利用。對(duì)用戶程序而言,網(wǎng)卡上只有固定數(shù)目的端口,每個(gè)端口有高低兩個(gè)優(yōu)先級(jí),而每個(gè)端口有固定數(shù)目的發(fā)送和接收令牌。在發(fā)送或接收前,必須首先要打開端口,并申請(qǐng)發(fā)送或接收令牌,然后才能以某個(gè)優(yōu)先級(jí)發(fā)送或者接收數(shù)據(jù)。與此機(jī)制相適應(yīng),采用了MCP的如圖2所示的數(shù)據(jù)結(jié)構(gòu)方式。
?
如圖2,MCP的數(shù)據(jù)是以多級(jí)鏈表的方式組織的。第一級(jí)是表示各個(gè)主機(jī)之間的互連關(guān)系的雙向鏈表;在該雙向鏈表的每個(gè)節(jié)點(diǎn)處掛上一條表示通過該連接進(jìn)行傳輸?shù)牡诙?jí)子端口雙向鏈表SP;而在子端口雙向鏈表的每個(gè)節(jié)點(diǎn)處,還掛接一條要通過該子端口進(jìn)行數(shù)據(jù)發(fā)送的第三級(jí)發(fā)送令牌ST鏈表。用戶程序發(fā)送數(shù)據(jù)時(shí),只需要在這個(gè)多級(jí)鏈表結(jié)構(gòu)中掛上發(fā)送令牌,因此開銷很小,大概只需要1μs的處理時(shí)間。
3 GM的工作原理和編程模型
下面介紹GM的數(shù)據(jù)發(fā)送和接收的工作過程。實(shí)際程序中,通信前需要進(jìn)行一系列預(yù)備工作:
· 選定一個(gè)通信端口,調(diào)用gm_open()打開該端口。gm_open()進(jìn)行初始化工作,主要是打開設(shè)備文件(在Linux下一個(gè)GM端口對(duì)應(yīng)一個(gè)設(shè)備文件),將LANai上的EPPROM和SRAM映射到主機(jī)的內(nèi)存中去,以便用戶程序的訪問。
· 申請(qǐng)DMA存儲(chǔ)區(qū)。GM使用LANai上的DMA引擎來實(shí)現(xiàn)主機(jī)內(nèi)存與LANai SRAM之間的數(shù)據(jù)傳輸,所以主機(jī)方面的數(shù)據(jù)必須存放在DMA存儲(chǔ)區(qū)中。
· 申請(qǐng)發(fā)送令牌。令牌是LANai的資源管理手段,每個(gè)端口都只有有限數(shù)量的發(fā)送令牌和接收令牌。獲得令牌是使用LANai資源的保證,因此發(fā)送操作完成后,須馬上釋放令牌以保證后面的發(fā)送操作可以獲得必要的LANai資源。
現(xiàn)在假設(shè)上述預(yù)備工作已經(jīng)完成,一臺(tái)主機(jī)調(diào)用gm_send()發(fā)送數(shù)據(jù)。gm_send()僅僅根據(jù)發(fā)送參數(shù)填寫Send Token數(shù)據(jù)結(jié)構(gòu),并將其掛接到MCP的多級(jí)鏈表上。
MCP以輪詢的方式不斷檢測(cè)多級(jí)鏈表,當(dāng)發(fā)現(xiàn)有發(fā)送請(qǐng)求,就啟動(dòng)發(fā)送事件處理句柄來完成實(shí)際的發(fā)送操作。這個(gè)過程包括數(shù)據(jù)從主機(jī)到LANai SRAM的數(shù)據(jù)DMA傳送、數(shù)據(jù)拆分、組包、CRC校驗(yàn)、發(fā)送到網(wǎng)絡(luò)上。當(dāng)一個(gè)發(fā)送請(qǐng)求被處理后,就會(huì)被轉(zhuǎn)到另外的一個(gè)鏈表中,該鏈表維護(hù)所有已經(jīng)處理但是尚未收到對(duì)方應(yīng)答的發(fā)送請(qǐng)求。只有收到了對(duì)方的應(yīng)答后,數(shù)據(jù)發(fā)送才算真正完成。
在接收方,當(dāng)網(wǎng)卡采集到數(shù)據(jù)以后,會(huì)啟動(dòng)處理句柄對(duì)其處理,包括數(shù)據(jù)校驗(yàn)、重組、數(shù)據(jù)應(yīng)答等,然后存放在SRAM緩存中等待以DMA的方式傳送到主機(jī)內(nèi)存中。這需要主機(jī)方面預(yù)先準(zhǔn)備DMA內(nèi)存和接收令牌,如果主機(jī)長(zhǎng)時(shí)間不提供接收資源,那么這些數(shù)據(jù)將被丟棄。
4 GM的編程模型和API
GM用戶程序一般都是用輪詢的方式執(zhí)行的。程序在進(jìn)行了打開端口、申請(qǐng)內(nèi)存等預(yù)備工作以后,就進(jìn)入一個(gè)循環(huán),在這個(gè)循環(huán)里,通過不斷地調(diào)用gm_receive()來獲取當(dāng)前發(fā)生的事件,比如發(fā)送完成、有數(shù)據(jù)到達(dá)、系統(tǒng)出錯(cuò)等來決定相應(yīng)的動(dòng)作。下面是GM用戶程序的通用模式:
 ?
?
事實(shí)上這種編程模式不太靈活,這也是GM的高性能運(yùn)作模式所決定的。
LIBGM為GM用戶程序提供了一整套的API接口。這套API提供了以下的功能:
· 系統(tǒng)初始化和釋構(gòu);
· 數(shù)據(jù)發(fā)送,接收;
· DMA內(nèi)存的申請(qǐng),釋放,映射;
· Token管理;
· 哈希存儲(chǔ)管理;
· 獲取和定制系統(tǒng)參數(shù),比如獲取節(jié)點(diǎn)ID,設(shè)定可接收數(shù)據(jù)包的最少長(zhǎng)度。
?
參考文獻(xiàn)
1 GM-1.1.3 source code,http://www.myri.com/
2 Nanette J.Boden,et al,. Myrinet: a gigabit-per-second?local area network.[J]1999,29~36.