
0 引言
對于大多數(shù)人來說,都會有這樣的客戶體驗:去銀行或者保險公司辦理業(yè)務(wù),或者接收他們的保單宣傳,我們所面對和接收的都是一張張一樣的表單,然后上面有一些空白的表格或者下劃線,然后將客戶的信息填上去。這樣的做法有以下兩個缺點:
(1)客戶體驗差。所有客戶拿到的都是一樣的表單,因為考慮特殊的情況,表單里面的空白的地方都會比較大,所以一般會出現(xiàn)大片空白的區(qū)域。
(2)對于每種不同的客戶或者不同的業(yè)務(wù)會需要不同的表單,對于客戶信息變動的情況,需要人工完成,比較繁瑣。
為了更好的客戶體驗,越來越多的公司傾向于采用動態(tài)打印技術(shù)。這樣每個客戶接收到的文檔或者打印件都是定制化的,這樣就能克服以上缺點而做到:
(1)客戶體驗優(yōu)。所有客戶拿到的文檔都是定制化的,表單里沒有需要填空的地方,客戶的數(shù)據(jù)都會被程序動態(tài)地植入表格模板里,就好像專門為客戶定做的文檔。
(2)我們可以在模板中定義一些規(guī)則,然后根據(jù)客戶數(shù)據(jù)來采用相應(yīng)的規(guī)則。例如,美國各個州的法律是不一樣的,我們可以在編輯文檔的時候就定義規(guī)則:如果客戶是A州的,就用A條文,如果是B州的,就用B條文。這樣當(dāng)生成文檔的時候,程序會根據(jù)當(dāng)前客戶是屬于哪個州的,動態(tài)地加入這一段條文,而不需要人工的判定。并且,當(dāng)客戶從A州搬到B州,我們只需要更新一下客戶的數(shù)據(jù),客戶下次就能拿到更新的正確的文檔。
1 動態(tài)文檔發(fā)布系統(tǒng)
有了如上的需求,很多公司都加入了開發(fā)動態(tài)文檔發(fā)布系統(tǒng)的行列。對于動態(tài)文檔發(fā)布,簡單說起來,一般的步驟是:1)建立文檔模板;2)運(yùn)行時,裝載客戶數(shù)據(jù)進(jìn)入模板;3)拼接文檔;4)排版;5)輸出前處理;6)輸出成不同格式的文檔;7)發(fā)布和歸檔。
動態(tài)文檔發(fā)布系統(tǒng)可以使客戶高性能制作并發(fā)送設(shè)計精美、高度個性化的溝通材料,從合同、保險單、大批量的賬戶關(guān)系維護(hù)通知單,到定制的推廣資料、商業(yè)信函等。客戶可以在該系統(tǒng)平臺上,運(yùn)用自己熟悉的文檔開發(fā)軟件,如Word、Adobe Indesign、Dream Weaver,開發(fā)出文檔模板,并根據(jù)系統(tǒng)提供的插件進(jìn)行邏輯的設(shè)置。然后,該模板就能被送往系統(tǒng),跟隨提供的客戶數(shù)據(jù)而批量地生成客戶需要的定制文檔。接著,生成的文件可以通過不同的途徑,例如,郵件、e-mail、手機(jī)短信等方式發(fā)送到客戶,使客戶有良好的用戶體驗。
2 自動化測試的要求
對于這樣一個復(fù)雜的系統(tǒng),它的主要客戶是一些保險公司和銀行,而它的主要產(chǎn)出是保單和合同。同時,合同和保單都是很嚴(yán)肅和很嚴(yán)謹(jǐn)?shù)奈臋n。客戶需要的是他們的客戶在客戶數(shù)據(jù)沒有改變的情況下,得到的是一貫的體驗。
但是同時,動態(tài)文檔發(fā)布系統(tǒng)本身又是一個不斷發(fā)展和改善的系統(tǒng)。它擁有非常復(fù)雜的排版邏輯,并且每個版本的升級都會有大量的新功能和新邏輯被引入,這樣的邏輯改變?nèi)绻呐掠幸稽c點的差錯,原來客戶的整個文檔可能就會面目全非。如果老的客戶需要升級這些新功能的話,我們需要保證客戶得到一貫的體驗。也就是說,他們用舊的版本系統(tǒng)生成的文檔和在新的版本系統(tǒng)生成的文檔要保持一致,除非新的版本生成的更好,并得到客戶的同意。
這樣,為了達(dá)到上面的目標(biāo),我們需要在新版本發(fā)布前,運(yùn)行一些老客戶的文檔(挑選一些很典型的客戶文檔),并且一個個和老版本生產(chǎn)的文檔進(jìn)行比較。但是我們不能把這個過程推到新版本發(fā)布之前才做,因為那個時候整個項目已經(jīng)積累了很多的不同點,很難追查到源頭并加以改正。所以我們需要把這個過程提前,并且頻繁地去檢查。
由于需要頻繁的檢查,并且文檔的比較是個很繁重的體力活,所以自動測試將會是很好的方法,它不僅能夠節(jié)省絕對的人力,而且能夠保證絕對的準(zhǔn)確,不會被人為因素干擾。
我們可以把這個自動測試集成到日常的打包系統(tǒng)中,每次打包后就可以自動地完成運(yùn)行,比較和生成報告。
但是,我們不能在打包服務(wù)器上每次都去部署新的系統(tǒng),因為那樣太笨重了,并且會讓環(huán)境問題和我們系統(tǒng)本身的問題經(jīng)常性地糾纏不清。所以,我們需要自己建立一套輕量級的架構(gòu)去承載這個測試過程:
(1)我們的系統(tǒng)是建立在基于應(yīng)用服務(wù)器的EJB架構(gòu)上的,并且EJB的主要操作是基于對數(shù)據(jù)庫的操作,但是我們對于該自動測試的系統(tǒng)的要求是,對外部的依賴越少越好,因為這樣的話,我們就能很方便地在各個相關(guān)程序員和測試人員以及配置人員之間進(jìn)行部署和實施,所以我們希望他不要依賴應(yīng)用服務(wù)器和數(shù)據(jù)庫。
(2)我們要明確輸入源和輸出源,并且能夠提供一些簡單并且方便的配置,而且在很小代價的前提下,能夠在不同的輸入源和輸出源之間隨意切換。
(3)結(jié)果必須是可以有辦法鑒別的,并且鑒別結(jié)果是能夠很容易取得和方便查閱的。
3 設(shè)計方案
根據(jù)上面提出的三個要求,我們將通過分析我們的系統(tǒng)來提出我們的解決方案。
3.1 分析
對于這個系統(tǒng)來說,我們首先需要解決對于應(yīng)用服務(wù)器,也就是對于EJB的依賴。為了達(dá)到這個目的,我們必須對系統(tǒng)的主要模塊進(jìn)行分析,來想辦法如何解除依賴。
3.1.1 系統(tǒng)主要模塊介紹
我們可以看看此系統(tǒng)的一個特別簡化同時又很典型的流程:
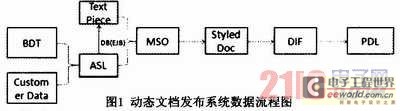
首先介紹一下每個術(shù)語:
BDT:Business document template,商業(yè)文檔模板。在這里我們定義一些規(guī)則,然后會跟客戶數(shù)據(jù)關(guān)聯(lián)選擇具體的規(guī)則。
Customer Data:客戶數(shù)據(jù)。XML格式記錄特定客戶的數(shù)據(jù),然后根據(jù)這些客戶數(shù)據(jù),動態(tài)產(chǎn)生不同文檔。
ASL:Assembly List,裝配列表。由BDT和客戶數(shù)據(jù)裝載生成,里面記錄的是一個個根據(jù)規(guī)則而選出來的最終文檔片段(text piece)。
Text Piece:文檔片段。在客戶端定義,并存儲在數(shù)據(jù)庫端的文檔片段。
MSO:微軟自己定義的HTML格式Microsoft HTML,然后我們在里面加入一些我們自己定義的標(biāo)記。
Styled Doc:式樣文檔。我們定義的一個格式,其實就是一些結(jié)構(gòu)類,會對文檔的各個內(nèi)容、樣式、布局進(jìn)行描述。
DIF:Document Independent Format,獨立文檔格式。StyledDoc經(jīng)過CE(composition)排版的結(jié)果就是DIF。它是一個頁面級別的概念,告訴你什么時候生成一個新頁面,多大,在哪里用什么字體寫些什么字,在哪里放一個什么樣的圖片。
PDL:Page Description Language,頁面描述語言。我們需要生成的最終結(jié)果,就是那些用頁面來表示文檔的語言,例如,Word、PDF、AFP、Postscript等等。
從圖1可以看出,我們的EJB主要用在對數(shù)據(jù)庫的操作上。對于數(shù)據(jù)庫的操作,主要是對數(shù)據(jù)模板(BDT)的提取,然后和本地客戶數(shù)據(jù)進(jìn)行整合,進(jìn)而得出需要真正從數(shù)據(jù)庫取出數(shù)據(jù)的組合(ASL),最后進(jìn)行后面的排版(CE)、計算,生成各種不同類型的文檔。
3.1.2 解耦數(shù)據(jù)庫
既然我們要去除EJB和數(shù)據(jù)庫的束縛,我們能不能繞過去呢?進(jìn)一步分析,我們得到,數(shù)據(jù)模板在和客戶數(shù)據(jù)裝載(Assemble)后會在數(shù)據(jù)庫里生成一個xml文件,用來描述最終會用到的具體的存在于數(shù)據(jù)庫中間的文本片段。而這個xml文件,我們稱之為ASL。我們試想,如果我們用一個辦法,直接生成我們要用到的ASL文件,那么我們是不是就可以繞過EJB和數(shù)據(jù)庫了呢?
答案是一半肯定,一半否定。首先,我們的確能繞過EJB的應(yīng)用,它主要用于assemble這個階段。但是光有ASL是沒有用的,因為我們還需要通過ASL去數(shù)據(jù)庫里取得所有的文本片段去做整合(Merge)。那么我們能不能把輸入進(jìn)一步地往后面推,推到Merge以后呢?答案是不能。首先來說Merge的輸入也就是文本片段會有很多,他們之間的關(guān)系很復(fù)雜,這些都是記錄在ASL里面,并且,Merge本身就是一個比較容易出問題的模塊,是我們做這個Test Client要重點模擬和測試的模塊,所以我們只能另想辦法。
這里我們大概介紹一下通過ASL去數(shù)據(jù)庫取文本片段的過程。這個過程其實比較簡單,因為邏輯方面的運(yùn)算已經(jīng)在Assemble的過程中處理完成,這里的任務(wù)是根據(jù)ASL里面的一個個的文本片段ID去數(shù)據(jù)庫里取出相應(yīng)的數(shù)據(jù)來進(jìn)行后續(xù)的流程。既然是這樣的一個過程,我們決定嘗試通過本地文件來模擬數(shù)據(jù)庫記錄。我們可以把數(shù)據(jù)從數(shù)據(jù)庫里取出來,按照一定的規(guī)則,給它們命名為本地的一個個文件,然后在我們的測試框架中重載以前的去數(shù)據(jù)庫取文本片段的方法為去本地的文件夾里取。這樣的確是可行的,因為:
(1)我們的目的是驗證我們的文檔歷史的保真度(Fidelity)的問題,那么我們的文檔的文本片段是不會有所改變的。所以我們可以把它們放心轉(zhuǎn)移到本地,而不用擔(dān)心更新問題。
(2)文件放到本地,能減少傳輸上的消耗,并且如果把方法進(jìn)行重載,是代價最小和最自然的一件事情,并且能最大限度地利用原來的代碼。
(3)經(jīng)過一些小小實驗,我們發(fā)現(xiàn)經(jīng)過很小的改動,我們可以把數(shù)據(jù)庫的文件按照一定的規(guī)則改寫到本地。這些都可以通過寫一些小程序來實現(xiàn)。以后有新的文檔,都可以用這個方法來實現(xiàn),簡單而易用。
3.1.3 輸入和輸出
在去除EJB和數(shù)據(jù)庫的束縛的過程中,我們得到了我們的輸入方式,那就是ASL+Text Pieces。輸出文件當(dāng)然很簡單了,我們選擇PDF,這個是我們主要的打印格式,當(dāng)然,我們可以方便配置生成其它的格式文件,但是對于自動比較,由于我們現(xiàn)在的工具只支持PDF的比較,所以,對其它的格式文件輸出,我們暫時不能提供自動比較。
3.2 框架方案
有了輸入和輸出,以及明確的需求,我們給出框架的解決方案:

(1)把整個過程分為輸入、過程中、輸出、輸出后。
(2)對于配置,采用XML,并且在XML里提供對輸入、輸出、以及中間的過程的配置。
(3)對于輸入,我們定義一個接口,對于這個接口的實現(xiàn)將會是各個不同的輸入方式,對于目前來說我們是支持ASL+Textpieces。但是我們以后會支持另外的輸入方式。然后對于所有的輸入接口,我們定義一個中心的中間輸出,我們叫它IDoc。它實際上是輸入和發(fā)布的中心,輸入都要轉(zhuǎn)成這個我們定義的中間結(jié)果,然后輸出都需要從這個中間結(jié)果進(jìn)行加工。
(4)對于輸出,我們可以把它們同樣配置在XML里面。并且對于最基本的輸出例如PDF,我們可以把它作為默認(rèn)的一個輸出,而不需要每次進(jìn)行配置。
(5)對于中間過程,我們配置了一些攔截器,這些攔截器以IDoc為中心,設(shè)置了publish前和publish后的攔截器,也就是說,在這里我們可以對publish前和publish后進(jìn)行一些配置。比如,在開始前我們可以開始計時,結(jié)束后結(jié)束計時,這樣我們可以測試一些效率方面的例子。
(6)對于輸出,我們對于PDF輸出,我們要實現(xiàn)它和自動比較工具的一個集成,也就是生成完P(guān)DF后,在配置要求進(jìn)行比較的情況下,自動調(diào)用PDF比較工具對輸出結(jié)果和標(biāo)準(zhǔn)進(jìn)行比較,然后得出結(jié)果,并且生成HTML結(jié)果表格,然后通過Email給相關(guān)人員進(jìn)行發(fā)送。
3.3 用例
當(dāng)整個系統(tǒng)運(yùn)行起來后,操作步驟如下:
首先,簡單來說,我們會提供一些默認(rèn)的XML配置,包括用例存放路徑、輸入方式、輸出方式、發(fā)比較結(jié)果郵件會發(fā)給哪些人等等進(jìn)行默認(rèn)配置。因為這些東西會很少改動,當(dāng)然改動的時候,我們重新配置就行。然后我們把需要運(yùn)行的輸入,即ASL+Text Pieces放到一個配置的路徑里,然后用名字去區(qū)分不同的用例。然后我們通過XML配置我們的輸入格式、輸出格式,以及需不需要對結(jié)果進(jìn)行比較、需不需要發(fā)郵件等等選項。當(dāng)這些配置配完以后,我們給它起一個唯一的用例名,然后在程序里將這個用例名作為參數(shù)運(yùn)行就能使整個過程自動完成。對于程序員,我們每次提交關(guān)鍵代碼,都會先運(yùn)行一下這個框架程序,然后查看自動生成的測試報告。如果發(fā)現(xiàn)問題,及時改正。而對于配置管理員來說,他們這個過程用ant工具配置在打包腳本中,然后我們就可以在每次打包時,自動地運(yùn)行我們預(yù)先設(shè)置的用例。并且,生成文件后,程序會自動對生成的PDF文件進(jìn)行比較,并將結(jié)果整理發(fā)出郵件。相關(guān)人員會通過Email收到比較結(jié)果,在上面可以通過超鏈接很方便地點選那些比較不對的文檔,然后通知程序員進(jìn)行改正。整個過程由于都是由機(jī)器在后臺快速運(yùn)行,少了人工的干擾,所以既提高了準(zhǔn)確率,又提高了效率。
4 結(jié)論
由于文檔發(fā)布系統(tǒng)的客戶對于不同系統(tǒng)版本間文檔一致性的高要求,使我們必須要提供一個長久的機(jī)制保證這個一致性。而要保證這個系統(tǒng)的一致性,我們提出了一個輕量級自動測試的方案。這里所說的輕量級,只是說該框架下運(yùn)行方便,不需要受應(yīng)用服務(wù)器和數(shù)據(jù)庫的約束,但是理論它上提供了文檔發(fā)布系統(tǒng)同樣的功能和行為。實際上在整個過程中,我們盡量調(diào)用原先系統(tǒng)的程序,但是在解除對于服務(wù)器和數(shù)據(jù)庫的依賴方面,我們通過仔細(xì)分析原來的動態(tài)文檔發(fā)布系統(tǒng)各個模塊的前提下,采用了用本地文件模擬數(shù)據(jù)庫的方法,通過重載方法實現(xiàn)了對于數(shù)據(jù)庫的解耦。該框架提供了強(qiáng)大的可配置功能,通過簡單的XML設(shè)置,我們可以對整個過程進(jìn)行配置,靈活實現(xiàn)不同的功能組合。
在未來,我們還會不斷完善這個框架,例如會提供更多的輸入選擇,提供可視化的配置,提供盡量準(zhǔn)確的診斷功能幫助程序員方便定位錯誤,并且根據(jù)動態(tài)文檔發(fā)布系統(tǒng)的升級而相應(yīng)提供更多的配置和功能。