
摘要:為了識別兩路頻譜混疊語音信號,多采用盲信號分離的方法。但是該方法在工程實踐中實現(xiàn)較困難。因此給出了一種利用盲源信號分離的原理及特點的實現(xiàn)方法,具體說明了用FastICA算法在ADSP_BF533平臺上實現(xiàn)盲源信號分離時的具體流程。該設(shè)計方案所需時間短,效率高,而且占用內(nèi)存較少。
關(guān)鍵詞:盲信號分離;DSP;FastICA;ADSP_BF533平臺
0 引言
近年來,許多學(xué)者都針對盲信號分離不斷地提出新的理論算法,盲信號分離(BSS)發(fā)展也日趨完善。而用DSP器件實現(xiàn)這種技術(shù)具有很大意義。本文提出了盲源信號分離的實現(xiàn)原理、算法和實現(xiàn)步驟,并對利用DSP實現(xiàn)時經(jīng)常出現(xiàn)的問題提出了解決方案。
盲信號分離是指在傳輸信道特性和輸入信息未知或者僅有少量先驗知識的情況下,只由觀測到的輸出信號來辨識系統(tǒng),以達(dá)到對多個信號分離的目的,從而恢復(fù)原始信號或信號源。它是一種在神經(jīng)網(wǎng)絡(luò)和統(tǒng)計學(xué)基礎(chǔ)上發(fā)展起來的技術(shù),并在近十年來獲得了飛速發(fā)展。盲源信號分離對很多領(lǐng)域的多信號處理與識別提供了很大方便。該技術(shù)在通信、生物醫(yī)學(xué)信號處理、語音信號處理、陣列信號處理以及通用信號分析等方面有著廣泛的應(yīng)用前景。它不僅對信號處理的研究,而且也對神經(jīng)網(wǎng)絡(luò)理論的發(fā)展起著積極的推動作用。
1 盲源信號分離的數(shù)學(xué)模型及常見算法
1.1 數(shù)學(xué)模型
盲分離問題的研究內(nèi)容大體上可以劃分為瞬時線性混疊盲分離、卷積混疊盲分離,非線性混疊盲分離以及盲分離的應(yīng)用四部分。當(dāng)混疊模型為非線性時,一般很難從混疊數(shù)據(jù)中恢復(fù)源信號,除非對信號和混疊模型有進(jìn)一步的先驗知識。圖1所示是瞬時線性混疊盲分離信號模型示意圖。
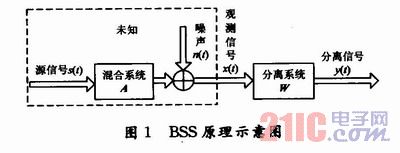
圖1中,S=[s1(t),s2(t),…,sN(t)]T是未知的N維源信號向量,A是未知的混合矩陣,n=[n1(t),n2(t),…,nN(t)]T是M維噪聲向量,X=[x1(t),x2(t),…,xM(t)]T是傳感器輸出的M維觀測信號向量,有X=AS+n,盲源分離算法要求只知道X來確定S或A。獨立分量分析(Independent ComponentAnalysis,ICA)是BSS的一種,其基本含義是把信號分解成若干個互相獨立的成分。圖1中,ICA的目標(biāo)就是尋找一個分離矩陣W,使X經(jīng)過變換后得到的新矢量Y=[y1(t),y2(t),…,yN(t)]T的各分量盡可能的獨立。Y=WX為待求的分離信號向量,也就是源信號S的估計值。
1.2 盲信號預(yù)處理常見算法
在盲信號處理過程中,為了減少計算量,提高系統(tǒng)效率,通常需要經(jīng)過預(yù)處理。預(yù)處理一般包括中心化和白化。中心化是使信號的均值為零。由于在一般情況下所獲得的數(shù)據(jù)都具有相關(guān)性,所以通常都要求對數(shù)據(jù)進(jìn)行初步的白化處理,因為白化處理可去除各觀測信號之間的相關(guān)性,從而簡化后續(xù)獨立分量的提取過程。而且,通常情況下,對數(shù)據(jù)進(jìn)行白化處理與不對數(shù)據(jù)進(jìn)行白化處理相比,其算法的收斂性較好、工作量少、效率高。
線性混疊盲分離信號模型一般都采用獨立分量分析的方法。ICA的主要依據(jù)和前提是假設(shè)源信號是獨立的,因此,自然就可以設(shè)想ICA算法的第一步是建立目標(biāo)函數(shù)來表征分離結(jié)果的獨立程度。目標(biāo)函數(shù)確定后,可通過各種不同的優(yōu)化算法進(jìn)行優(yōu)化,進(jìn)而確定分離矩陣W,其中有代表性的算法主要有最大信息量(Infomax)法、自然梯度法、快速獨立元分析算法(FastICA)、矩陣特征值分解法等。盲分離中經(jīng)常要用到優(yōu)化運(yùn)算,就優(yōu)化手段而言,Infomax算法、自然梯度算法屬于梯度下降(上升)尋優(yōu)算法,收斂速度是線性的,速度略慢一些,但屬于自適應(yīng)方法,且具有實時在線處理能力;FastICA算法是一種快速而數(shù)值穩(wěn)定的方法,采用擬牛頓算法實現(xiàn)尋優(yōu),具有超線性收斂速度,通常收斂速度較梯度下降尋優(yōu)算法快得多;矩陣特征值分解方法一般通過對矩陣進(jìn)行特征分解或者廣義特征分解來估計分離矩陣,這是一種解析方法,可直接找到閉形式解(Closed Form Soutions),由于其沒有迭代尋優(yōu)過程,因此運(yùn)行速度最快。
2 盲源信號分離的DSP實現(xiàn)方法
2.1 實現(xiàn)原理
由于FastICA算法和其他的ICA算法相比,具有許多人們期望的特性:如收斂速度快、無需選步長參數(shù)、能夠通過選擇適當(dāng)?shù)姆蔷€性函數(shù)g來最佳化、能減小計算量等。同時也有許多神經(jīng)算法的優(yōu)點,如并行、分布式且計算簡單,內(nèi)存要求很少等。因此,F(xiàn)astICA得到了廣泛的應(yīng)用。本文就采樣了這種算法。
2.2 實現(xiàn)方法
基于負(fù)熵最大的FastICA算法的基本原理是基于中心極限定理。即:若一隨機(jī)變量X由許多相互獨立的隨機(jī)變量Si(i=1,2,…,N)之和組成,那么,只要Si具有有限的均值和方差,則不論其為何種分布,隨機(jī)變量X較Si更接近高斯分布。由信息論理論可知;在所有等方差的隨機(jī)變量中,高斯變量的熵最大,因而可以利用熵來度量非高斯性,常用熵的修正形式,即負(fù)熵。因此,在分離過程中,可通過對分離結(jié)果的非高斯性度量來表示分離結(jié)果間的相互獨立性,當(dāng)非高斯性度量達(dá)到最大時,表明已完成對各獨立分量的分離。
負(fù)熵的定義公式如下:
![]()
式中:YGauss是與Y具有相同方差的高斯隨機(jī)變量,H(·)為隨機(jī)變量的微分熵,其表達(dá)式為:
![]()
當(dāng)Y具有高斯分布時,Ng(Y)=0;Y的非高斯性越強(qiáng),其微分熵越小,Ng(Y)值越大,所以,Ng(Y)可以作為隨機(jī)變量Y非高斯性的測度。由于根據(jù)公式計算微分熵時,要知道Y的概率密度分布函數(shù)不切實際,于是可采用如下公式:
![]()
式中:E[·]為均值運(yùn)算;g(·)為非線性函數(shù),其表達(dá)式可用下列非線性函數(shù)表示:

這樣就可以算出一個獨立分量,但每次迭代完成后,還應(yīng)對Wi進(jìn)行歸一化處理。當(dāng)計算n個獨立分量時,需要n個列矢量,并且每次迭代后,都需進(jìn)行線性組合以去掉相關(guān)性。
3 軟硬件實現(xiàn)
3.1 硬件平臺
Blackfin處理器以RISC編程模型突破性地把信號處理性能和電源效率結(jié)合起來。這種處理器在統(tǒng)一的結(jié)構(gòu)中可提供微控制器(MCU)和信號處理兩種功能,并可以在控制和信號處理兩種功能需求之間靈活的劃分。
本硬件系統(tǒng)包含ADSP-BF533處理器,32 MBSDRAM MT48LC32M16A2TG,2 MB FLASHPSD4256G6V,ADV1836音頻編解碼器等,其系統(tǒng)結(jié)構(gòu)框圖如圖2所示。

3.2 軟件實現(xiàn)
Matlab仿真成功后,還需要用硬件來實現(xiàn)。這里以選用ADSP_BF533為例進(jìn)行闡述。其流程圖如圖3所示。在用DSP編程實現(xiàn)時,其常見問題首先是白化處理中要用到特征值分解,采用的方式是進(jìn)行多次QR分解。

為了使人耳可以分辨出不同的聲音,觀測時間應(yīng)該足夠大,在AD1836采集頻率為48kHz時,采集約為22s的聲音信號,其需要處理的數(shù)據(jù)長度為48K×22b,約為一百萬個點。在常規(guī)的程序設(shè)計中,對此信號的處理就需要定義長度為一百萬的數(shù)組,這遠(yuǎn)遠(yuǎn)的超出了內(nèi)存容量,故其解決方案是直接訪問(包括讀寫)存儲在SDRAM中的數(shù)據(jù),并把原來程序中的數(shù)組運(yùn)算修改為針對每個元素的運(yùn)算。每個元素均可直接訪問SDR-AM,而不必將保存在SDRAM中的數(shù)據(jù)通過數(shù)組的方式傳遞到內(nèi)存中。這就相當(dāng)于用時間換取內(nèi)存空間。
AD1836采集的數(shù)據(jù)為24位的二進(jìn)制有符號整形數(shù)據(jù)。為了提高精度,減小誤差,應(yīng)選用32位而不是16位的數(shù)據(jù)格式進(jìn)行處理。從24位到32位的轉(zhuǎn)換可采用的方案如下:
對于負(fù)數(shù):
![]()

其次,為了保證處理過程中的精度,還可選擇將data轉(zhuǎn)為float運(yùn)算的方法。
一般地,處理完的數(shù)據(jù)數(shù)值很小,范圍在(-10,10)之間,而播放時必須經(jīng)過D/A,但D/A本身的熱噪聲會帶來很大的誤差,信噪比顯然無法容忍。對此,其解決辦法是將處理完的數(shù)據(jù)乘以較大的數(shù)值,這樣,聲音信號的相對值并沒有發(fā)生改變,因而播放時可達(dá)到良好的效果。這一方法也是用數(shù)字電路工具(如DSP,F(xiàn)PGA等)處理模擬信號時的常用方法。
4 實際效果
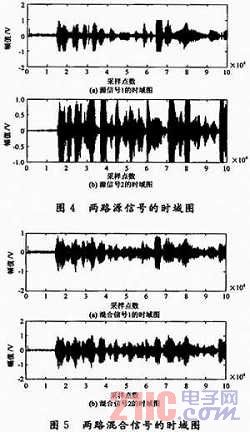
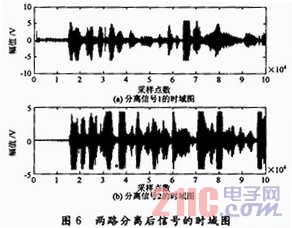
圖4所示是兩段錄音的音頻信號時域圖,圖5則是經(jīng)過瞬時線性混合后的信號時域圖,圖6是經(jīng)過在BF533平臺上利用FastICA算法得到的分離后的信號時域圖。實驗發(fā)現(xiàn),圖6所示的結(jié)果分離效果良好,可以清楚地聽到不同的源信號。
5 結(jié)論
本文首先簡單介紹了盲信號分離的數(shù)學(xué)模型以及常用的理論算法。之后詳細(xì)介紹了用ADSP_BF533實現(xiàn)盲信號分離時的具體流程以及實現(xiàn)過程中常見問題的解決方案。本設(shè)計方案所需時間短,效率高,而且占用內(nèi)存較少。在工程應(yīng)用方面具有一定的參考價值。