
摘 要: 在簡(jiǎn)要介紹IA(Intel Architecture) MMXTM技術(shù)的基礎(chǔ)上,重點(diǎn)討論了應(yīng)用IA MMXTM技術(shù)的DCT快速算法及其優(yōu)越性能。
關(guān)鍵詞: Intel體系結(jié)構(gòu) IA MMXTM技術(shù) 快速算法 離散余弦變換(DCT)和離散余弦反變換(IDCT)
1 IA MMXTM技術(shù)簡(jiǎn)介
個(gè)人計(jì)算機(jī)處理數(shù)據(jù)的復(fù)雜度和數(shù)量的急劇增長(zhǎng),對(duì)微處理器的性能提出了更高的要求。其中以視頻、3D圖形、動(dòng)畫、音頻和虛擬現(xiàn)實(shí)為特征的應(yīng)用更是對(duì)微處理器的性能提出嶄新的要求。IA MMXTM技術(shù)應(yīng)運(yùn)而生。它的設(shè)計(jì)目的就是用來(lái)加強(qiáng)多媒體和通信方面的應(yīng)用。這一技術(shù)包括新的指令和數(shù)據(jù)類型。IA MMXTM技術(shù)介紹了一些新的通用指令,這些指令以并行處理的方式完成對(duì)一個(gè)64位數(shù)據(jù)組中的多個(gè)數(shù)據(jù)元素的操作。IA MMXTM指令集在不增加新的模式并保持對(duì)操作系統(tǒng)的透明性的基礎(chǔ)上,形成了一個(gè)簡(jiǎn)單而靈活的軟件模型。IA MMXTM技術(shù)定義了57條新的指令、8個(gè)64位寬度的IA MMXTM 寄存器和四種新數(shù)據(jù)類型。
IA MMXTM 技術(shù)最重要的特點(diǎn)是單指令多操作數(shù)據(jù)(SIMD),這一技術(shù)允許一條指令并行處理多個(gè)數(shù)據(jù)元素。正是這種并行處理的能力極大地提高了應(yīng)用程序的性能。IA MMXTM指令處理定點(diǎn)數(shù),多個(gè)整數(shù)字節(jié)、字或雙字被組合在一個(gè)單獨(dú)的64位IA MMXTM寄存器中。定點(diǎn)值的小數(shù)點(diǎn)位置由程序員自己決定,這樣保證了處理數(shù)據(jù)精度的靈活性。在IA MMXTM技術(shù)中支持有符號(hào)和無(wú)符號(hào)的定點(diǎn)整數(shù)字節(jié)、字、雙字和四字的各種運(yùn)算。
Intel Pentium處理器是先進(jìn)的超標(biāo)量處理器,它建立在兩個(gè)通用整數(shù)流水線和一個(gè)可流水作業(yè)的浮點(diǎn)處理單元之上。一個(gè)軟件透明的動(dòng)態(tài)分支預(yù)測(cè)機(jī)制使得流水線阻塞降低到最小。帶有IA MMXTM 技術(shù)的Intel Pentium處理器給流水線加入新的處理階段。Intel Pentium處理器能在一個(gè)時(shí)鐘周期內(nèi)執(zhí)行兩條指令,每條流水線執(zhí)行一條指令。第一條邏輯流水線稱為U流水線,第二條稱為V流水線。在任何指令的解碼期間,下兩條指令被檢查,如果可能,它們被分別送入U(xiǎn)、V流水線;否則,下一條指令送入U(xiǎn)流水線,而沒(méi)有指令送入V流水線。IA MMXTM技術(shù)指令通過(guò)指令調(diào)度可以充分利用Intel Pentium處理器的雙流水線機(jī)制以提高程序的運(yùn)行速度。IA MMXTM 寄存器和狀態(tài)是IA浮點(diǎn)寄存器和狀態(tài)的別名,這保證了IA MMXTM技術(shù)與現(xiàn)有的操作系統(tǒng)和應(yīng)用的完全兼容性。但是應(yīng)用浮點(diǎn)操作和IA MMXTM指令混合編程時(shí),浮點(diǎn)操作指令流和IA MMXTM指令流必須分開(kāi)并且在執(zhí)行完離開(kāi)時(shí)要進(jìn)行必要的清理工作,在IA MMXTM技術(shù)指令后要寫一條EMMS指令,在浮點(diǎn)操作完成后要清空浮點(diǎn)寄存器堆棧。IA MMXTM技術(shù)指令集如表1所示。

由于IA 體系的復(fù)雜性和IA MMXTM技術(shù)的本身特點(diǎn),開(kāi)發(fā)一個(gè)應(yīng)用IA MMXTM技術(shù)的應(yīng)用程序?qū)⑹潜容^復(fù)雜的,涉及到許多方面。其中主要有應(yīng)用的特點(diǎn)是否適應(yīng)IA MMXTM技術(shù)的要求,算法是否具有強(qiáng)的并行特點(diǎn)。這是決定應(yīng)用IA MMXTM技術(shù)的前提條件。具體在編程時(shí)要進(jìn)行優(yōu)化,一般的優(yōu)化策略包括地址生成互鎖(AGI)優(yōu)化、代碼及數(shù)據(jù)對(duì)齊、避免部分寄存器阻塞、分支預(yù)測(cè)信息和指令的合理調(diào)度。另外指令選擇優(yōu)化、內(nèi)存優(yōu)化和高速緩存優(yōu)化也極大地制約了應(yīng)用的性能。
2 圖象處理中的DCT和IDCT
在圖象處理中,離散余弦變換(DCT)及其反變換(IDCT)一直是運(yùn)動(dòng)估計(jì)/補(bǔ)償變換編解碼系統(tǒng)的速度瓶頸。盡管出現(xiàn)了大量的快速算法,但是由于圖象處理數(shù)據(jù)量非常大,使得這一系統(tǒng)在實(shí)時(shí)應(yīng)用中性能不佳。注意到圖象處理的DCT中,輸入數(shù)據(jù)和輸出數(shù)據(jù)都是整數(shù),基于這一特點(diǎn)本文介紹了應(yīng)用奔騰處理器IA MMXTM技術(shù),選擇特定的快速算法,將8×8塊的DCT和IDCT的速度提高了3倍以上。限于篇幅,這里只介紹DCT。
2.1采用行列快速算法DCT
在計(jì)算二維N×N點(diǎn)DCT時(shí)、一種常用的算法是采用行列快速算法。該算法首先按行計(jì)算N個(gè)一維DCT,再按列計(jì)算N個(gè)一維DCT,從而把乘法的計(jì)算量減少到直接計(jì)算的一半,其算法規(guī)律性強(qiáng),便于程序?qū)崿F(xiàn)。
c(u)=α(u)∑f(n)cos[πu(2n+1)/2N] (1)
(1)式給出了計(jì)算公式、這里、α(0)=1/![]() 、 α(u)=
、 α(u)=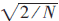 ,u≠0。直接計(jì)算一個(gè)1D N點(diǎn)DCT的乘法次數(shù)為N2次。通過(guò)研究DCT的特點(diǎn),Chun-Yen Lu和Kuei-Ann Wen提出了系數(shù)選擇8點(diǎn)一維DCT模式,現(xiàn)在簡(jiǎn)單介紹其方法。實(shí)數(shù)序列{f(n):n=0、1、...、N-1}的1D DCT-II可以表述如下:
,u≠0。直接計(jì)算一個(gè)1D N點(diǎn)DCT的乘法次數(shù)為N2次。通過(guò)研究DCT的特點(diǎn),Chun-Yen Lu和Kuei-Ann Wen提出了系數(shù)選擇8點(diǎn)一維DCT模式,現(xiàn)在簡(jiǎn)單介紹其方法。實(shí)數(shù)序列{f(n):n=0、1、...、N-1}的1D DCT-II可以表述如下:
在這里我們?cè)O(shè)定N=8、對(duì)于(1)式我們定義如下的系數(shù)矩陣F(n)和數(shù)據(jù)矩陣D(n):


從(2)式可以看出,1D8點(diǎn)DCT的計(jì)算可以分解為以下幾步:
·計(jì)算數(shù)據(jù)向量D;
·通過(guò)排列矩陣P重新排列D0,D1,D2和D3,即:D’=PD;
·計(jì)算SFD’,相應(yīng)的余弦系數(shù)集通過(guò)選擇矩陣Si從F中選擇。
通過(guò)這一過(guò)程,我們不難看出,系數(shù)選擇模式1D 8點(diǎn)DCT具有簡(jiǎn)明的規(guī)律性,便于程序?qū)崿F(xiàn)。
2.2 算法的IA MMXTM技術(shù)實(shí)現(xiàn)
2.2.1 對(duì)上述算法的改進(jìn)
簡(jiǎn)單地利用(2)式來(lái)計(jì)算DCT,并不能充分發(fā)揮IA MMXTM技術(shù)的優(yōu)越性能,我們對(duì)(2)式做如下變形:

u=0、1...7。[D′(u)]T是8點(diǎn)數(shù)據(jù)的規(guī)律性組合(見(jiàn)D(u)、區(qū)別是分別去掉了系數(shù)1、p(n)、q(n)、r(n)),是DCT的固定部分,對(duì)于不同數(shù)據(jù)的DCT保持不變。 從而將DCT分為固定部分[[SuF] [PuDc(u)]]T,和數(shù)據(jù)部分D′(u)。這樣計(jì)算時(shí)可以首先計(jì)算[[SuF][PuDc(u)]]T并制成表存儲(chǔ)起來(lái),程序中通過(guò)查表獲取乘法因子。從而使得1D8點(diǎn)DCT的計(jì)算變得適合IA MMXTM技術(shù)的實(shí)現(xiàn)。
2.2.2 將浮點(diǎn)運(yùn)算轉(zhuǎn)換為整數(shù)運(yùn)算
雖然通過(guò)算法的改進(jìn)使之適合程序?qū)崿F(xiàn)、但是在算法中仍然存在浮點(diǎn)乘法、對(duì)于數(shù)字視頻,其象素的各個(gè)分量一般為8位整數(shù),為了消除浮點(diǎn)運(yùn)算,將余弦系數(shù)擴(kuò)大65536倍,相當(dāng)于左移16位,因?yàn)檫@里的余弦系數(shù)都小于1/2,因此擴(kuò)大后的數(shù)據(jù)不會(huì)超出16位有符號(hào)短整型數(shù)據(jù)的范圍。這樣就把浮點(diǎn)運(yùn)算轉(zhuǎn)化為整型運(yùn)算。制定如下數(shù)組:
short A[8][4]={{iA1、iA1、iA1、iA1}、{iC1、iC2、iC3、iC4}、{iB1、iB2、-iB2、-iB1}、{iC2、-iC4、-iC1、-iC3}、{iA1、-iA1、-iA1、iA1}、{iC3、-iC1、iC4、iC2}、{iB2、-iB1、iB1、-iB2}、{iC4、-iC3、iC2、-iC1}};
其中iA1=A1×65536,iBu=Bu×65536,iCj=Cj×65536,u=1,2;j=1,2,3,4。注意到該數(shù)組共占用8×4×2=64個(gè)字節(jié),正好是奔騰處理器高速緩存線的整數(shù)倍,并且要把數(shù)組的起始位置放在32字節(jié)邊界上,這樣就可以優(yōu)化高速緩存的線讀入。
2.2.3 輸入數(shù)據(jù)格式
假設(shè)輸入是按自然順序的8點(diǎn)數(shù)據(jù),由D(n)的定義、在處理前要對(duì)后四點(diǎn)進(jìn)行反序調(diào)整、既將前四點(diǎn)按順序放入MMXTM寄存器中、并將其擴(kuò)展成16位數(shù)據(jù)、將后四位反序后以同樣的格式放入另一個(gè)MMXTM寄存器中。這樣可以用以下三條指令得出f(i)±f(7-i)、i=0、1、2、3。(設(shè)前四個(gè)放在MM0中、后四個(gè)放在MM2中)。
MOVQ MM1、MM0
PADDSW MM0、MM2 //MM0存放四個(gè)和值
PSUBSW MM1、MM2 //MM1存放四個(gè)差值
這樣、MM0和MM1為分別對(duì)應(yīng)n為偶數(shù)和奇數(shù)的情況。調(diào)整好輸入數(shù)據(jù)的格式將為IA MMXTM技術(shù)指令的應(yīng)用提供極大方便。
2.2.4 乘法運(yùn)算與精度問(wèn)題
通過(guò)以上的準(zhǔn)備工作,接下來(lái)就是依次計(jì)算8個(gè)DCT系數(shù)C(u)(u=0、1...7)了。這涉及到指令選擇的優(yōu)化問(wèn)題,從公式(3)我們知道,對(duì)于每個(gè)DCT系數(shù)C(u)是四個(gè)并行16位×16位的整數(shù)乘積的和,為了保證精度要求結(jié)果保留32位。在IA MMXTM技術(shù)指令集中,PMADDWD 正好完成這一并行乘法運(yùn)算和兩個(gè)乘積的和值計(jì)算,只要再做一次和就可以得出結(jié)果。另外,要根據(jù)n是偶數(shù)或奇數(shù)選擇f(i)±f(7-i)。下面是PMADDWD的操作示例:

在做完乘法和加法以后,要對(duì)數(shù)據(jù)進(jìn)行右移16位,相當(dāng)于除以65536,這樣就將數(shù)據(jù)還原為其真實(shí)值了。如果要進(jìn)一步提高精度可以對(duì)數(shù)據(jù)進(jìn)行四舍五入處理,關(guān)于這一點(diǎn)在此不做詳細(xì)說(shuō)明。鑒于程序流程簡(jiǎn)單明了,其流程圖和程序清單就不在此占用篇幅了。
在實(shí)際編程中,必須注意指令的調(diào)度問(wèn)題,這也是程序優(yōu)化的很關(guān)鍵的一個(gè)方面。下面就IA MMXTM技術(shù)指令與整型指令的配對(duì)規(guī)則做簡(jiǎn)要介紹。
· 整型指令的配對(duì)規(guī)則如表2
· MMXTM技術(shù)指令的配對(duì)

(1)由于僅有一個(gè)MMXTM移位單元,所以兩條MMXTM移位單元的MMXTM指令不能配對(duì)。移位操作可以在U流水線或V流水線中進(jìn)行,但不能在同一個(gè)時(shí)鐘周期內(nèi)的兩個(gè)流水線中處理。
(2) 同樣,兩條MMXTM乘法指令不能配對(duì)。
(3) 無(wú)論是對(duì)內(nèi)存還是對(duì)整數(shù)寄存器的文件訪問(wèn)的MMXTM指令僅被U流水線處理。
(4) U流水線指令的MMXTM目的寄存器不與V流水線指令的源或目的寄存器配對(duì)。
(5) EMMS指令不可配對(duì)。
· U流水線中的整數(shù)指令和V流水線中的MMXTM技術(shù)指令配對(duì)規(guī)則
(1)在浮點(diǎn)指令之后的第一條指令不能是MMXTM技術(shù)指令。
(2)V流水線的MMXTM指令不能訪問(wèn)內(nèi)存或整數(shù)寄存器文件。
(3)U流水線整數(shù)指令是可配對(duì)的U流水線整數(shù)指令。
· U流水線中的MMXTM技術(shù)指令和V流水線中的整數(shù)指令配對(duì)規(guī)則
(1)V流水線整數(shù)指令是可配對(duì)的V流水線整數(shù)指令。
(2)U流水線MMXTM指令不能對(duì)內(nèi)存或整數(shù)寄存器存取。
根據(jù)以上配對(duì)原則,相信讀者可以自己安排程序中的指令配對(duì)。
該程序雖然占用了不多的存儲(chǔ)單元,但是(接上頁(yè))
卻極大地提高了運(yùn)算速度,由于大存儲(chǔ)量的存儲(chǔ)體價(jià)格較低,因此這一點(diǎn)并不重要。
除此之外,筆者還在運(yùn)動(dòng)估計(jì)搜索算法中應(yīng)用IA MMXTM技術(shù),同樣性能顯著地提高了。
總之,IA MMXTM技術(shù)在數(shù)據(jù)處理的許多算法中都能發(fā)揮優(yōu)越的性能,能夠成倍地提高運(yùn)行速度。目前在多媒體應(yīng)用中,離散余弦變換(DCT)是經(jīng)常用到的變換編碼技術(shù),因此提高DCT的速度一直是這一應(yīng)用領(lǐng)域中的關(guān)鍵。利用IA MMXTM技術(shù)在不增加其他硬件的情況下,充分發(fā)揮Intel Pentium處理器的性能可以輕松地完成這一任務(wù)。在多媒體應(yīng)用中,IA MMXTM技術(shù)大大降低了程序?qū)μ幚砥鞯恼加寐剩固幚砥髂軌蛲瑫r(shí)更有效地執(zhí)行其他任務(wù)。
參考文獻(xiàn)
1 Intel Architecture MMXTM Technology Programmer's Reference Manual.1996
2 Intel Architecture MMXTM Technology Manual.1996.
3 [美]Intel公司著,李暉譯.Intel體系結(jié)構(gòu)MMXTM技術(shù)開(kāi)發(fā)指南.北京:電子工業(yè)出版社,1997
4 Chung-Yen Lu,Kuei-Ann Wen.On the Design of Selective Coefficient DCT Module.IEEE TRANSACTIONS ON CIRCUITS AND SYSTEMS FOR VIDEO TECHNOLOGY、1998;8(2)(收稿日期:1999-12-29)