
摘 要: 介紹循環(huán)冗余校驗title="CRC">CRC在TMS320C64x+系列DSP上的軟件實現(xiàn)。 給出了該實現(xiàn)方法的理論推導(dǎo)過程并提供了相應(yīng)的軟件實現(xiàn)代碼。
關(guān)鍵詞: CRC;DSP
1 CRC常規(guī)實現(xiàn)方法
CRC(Cyclic Redundancy Check)是一種廣泛應(yīng)用于各種通信系統(tǒng)的錯誤校驗機(jī)制。例如,3GPP標(biāo)準(zhǔn)定義以下16位CRC校驗多項式:
GCRC16(X)=X16+X12+X5+1
CRC通常由硬件實現(xiàn),圖1說明由硬件移位寄存器實現(xiàn)的3GPP CRC16。

圖1中,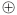 表示異或(XOR)運算, 異或運算在移位寄存器中的位置與生成多項式相對應(yīng)。CRC運算前,移位寄存器清零,隨后數(shù)據(jù)位被移入寄存器,當(dāng)所有位都被移入寄存器后,寄存器的值即為CRC碼。
表示異或(XOR)運算, 異或運算在移位寄存器中的位置與生成多項式相對應(yīng)。CRC運算前,移位寄存器清零,隨后數(shù)據(jù)位被移入寄存器,當(dāng)所有位都被移入寄存器后,寄存器的值即為CRC碼。
發(fā)送端將CRC碼附在原始數(shù)據(jù)后發(fā)送;接收端用同樣的方法為接收到的原始數(shù)據(jù)生成CRC碼,并且與接收到的CRC碼比較。如果不一致,則說明接收到的數(shù)據(jù)出錯。
CRC校驗也可由軟件實現(xiàn),它比硬件實現(xiàn)靈活,但不如硬件實現(xiàn)效率高。假設(shè)變量crc代表移位寄存器的值,CRC16 軟件實現(xiàn)的偽代碼為:
while(data_len--)
{
crc=(crc<<1)
if (((input bit)(bit shifted out))==1)
crc=crc0x1021 //0x1021 represents X12+X5+1
else if (((input bit)(bit shifted out))==0)
crc=crc0//this can be removed since it is meaningless
}
以上軟件實現(xiàn)效率不高,主要是因為數(shù)據(jù)被逐個位處理,每次循環(huán)只能處理一位。一種常見的改進(jìn)的軟件實現(xiàn)方法可以每次循環(huán)處理一個字節(jié),但它需要一個查找表。在查找表中保存所有的8位(一個字節(jié))數(shù)據(jù)的CRC運算結(jié)果,因為8位數(shù)據(jù)有256個,所以查找表的長度為256。下面是生成查找表的偽代碼:
for(i=0;i<256;i++)
crc_lut[i]=crc_value_for_one_byte(i);//generate CRC for one byte
用查找表方法實現(xiàn)的CRC16的代碼如下:
Uint16 crc16_lut(Uint8*data_prt,Int32 data_len,Uint16*crc_lut)
{
Uint8 crc_shift_out;
Uint16 crc=0;
while(data_len--)
{
crc_shift_out=(Uint8) (crc>>8);//higher 8 bit of previous crc are shifted out
crc=(crc<<8)^crc_lut[crc_shift_out^(*data_prt++)];
}
return(crc);
}
這個處理過程可被理解為:
(1)計算移位寄存器在8個時鐘周期中的輸入:(crc_shift_out^*data_prt++);
(2)查找這個輸入字節(jié)對應(yīng)的CRC碼:crc_lut[crc_shift_out^*data_prt++];
(3)把新輸入數(shù)據(jù)的CRC碼加到原有的CRC值上:(crc<<8)^crc_lut[crc_shift_out^*data_prt++]。
在TMS320C64x DSP上,如果用這種方法實現(xiàn)CRC校驗,每次循環(huán)大概需9個DSP時鐘周期。而在TMS320C64x+DSP上新增了與CRC運算相關(guān)的Galois域乘法運算指令,使得每次循環(huán)僅需約1個DSP時鐘周期。
2 C64x+DSP的Galois域乘法指令
C64x+DSP系列是TI最新的高性能DSP系列,它有8個并行的運算單元,速度高達(dá)到1GHz。C64x+ DSP 提供了新的與CRC運算相關(guān)的Galois域乘法指令和寄存器,可在兩個乘法單元M1、M2中并行執(zhí)行。
(1)GMPY:Galois域(32bit)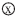 (9bit),寄存器GPLYA存放用于M1運算單元的多項式,寄存器GPLYB存放用于M2運算單元的多項式;
(9bit),寄存器GPLYA存放用于M1運算單元的多項式,寄存器GPLYB存放用于M2運算單元的多項式;
(2)XORMPY:多項式為0的Galois域(32bit)(9bit);
(3)GMPY4:同時執(zhí)行4個Galois域(8bit)(8bit),M1和M2運算單元共用存放多項式的GFPGFR寄存器。
注:表示Galois域乘法。
M1和M2可以并行執(zhí)行,所以,C64x+每個時鐘周期可執(zhí)行2個(32bit)(9bit)的GMPY或XORGMPY指令,或執(zhí)行8個(8bit)(8bit)的GMPY指令。
下面是C64x+GMPY指令的等效C代碼:
//32bits src1 multiply 9bit src2 with 32bit polynomial
uint GMPY(uint src1,uint src2,uint polynomial)
{
uint pp;
uint mask,tpp;
uint i;
pp=0;
mask=0x00000100;//multiply by computing partial products.
for (i=0;i<8;i++){
if (src2 & mask) pp^=src1;
mask>>=1;
tpp=pp<<1;
if(pp & 0x80000000) pp=polynomial^tpp;
else pp=tpp;
}
if (src2 & 0x1) pp^=src1;
return(pp);//leave it asserted left.
}
請注意,這里的GMPY指令所用的多項式是GF(232)原多項式的低32位。例如:
G(X)CRC32=X32+X26+X23+X22+X16+X12+X11+X10+X8+X7+X5+X4+X2+X1+1
用二進(jìn)制數(shù)表示為:1 0000 0100 1100 0001 0001 1101 1011 0111=0x1 04c1 1db7,則GMPY多項式寄存器的值應(yīng)該是0x04c11db7,沒有必要包含最高位,因為它始終為1。GMPY所用的多項式必須是GF(232)域多項式,對于非GF(232)域的多項式,必須被左移得到32階的多項式,并左移操作數(shù)src1,使它也是32階,然后用GMPY指令運算,結(jié)果需右移同樣的位數(shù),從而得到最終結(jié)果。
例如:Galois域G(X)=X8+X6+X5+X3+1(01101001)上的二進(jìn)制數(shù)(01000001)(100)可以用以下方法計算:
GMPY((01000001)<<24,(100),(01101001)<<24)>>24
3 CRC在C64x+DSP上的高效實現(xiàn)
比較CRC的軟件實現(xiàn)代碼和GMPY指令的等效C語言代碼可以看出,一個字節(jié)的CRC碼可以用GMPY指令計算為GMPY(polynomial, data_byte, polynomial)。
用GMPY實現(xiàn)的CRC代碼為:
Uint32 crc_gmpy(Uint8*data_ptr,Int32 data_len_of_byte,Uint32 polynomial)
//data_ptr is data pointer,data_len_of_byte is the data length in bytes
{
Int32 i;
Uint32 crc32=0;
GPLYA=polynomial;
GPLYB=polynomial;
for(i=0;i
crc32=_gmpy(crc32,0x100)^_gmpy(polynomial,(*data_ptr++));
}
return(crc32);
}
以上代碼中的“_gmpy”代表GMPY指令,用戶按C語言函數(shù)調(diào)用的方式使用它,但DSP編譯器會把它編譯成一條GMPY指令,而不是一個函數(shù)調(diào)用。所有的C6000系列DSP指令都可以在C語音中按這種方式使用。
以上代碼在C64x+上執(zhí)行,每次循環(huán)需要大約6個時鐘周期,它比查找表方法效率高,而且不需要查找表,這對于存儲器受限的應(yīng)用來說非常合適。上述代碼每個循環(huán)需要6個時鐘周期的瓶頸因素是“循環(huán)依賴”,即下一次循環(huán)運算要基于前一次運算的結(jié)果,這使得C64x+指令流水線不能充分的流水式執(zhí)行。一種改進(jìn)的查找表方法可以解決這一問題,從而大大提高CRC計算的效率。該方法使用的查找表可以由以下代碼生成:
crc_lut[0]=polynomial;
for(k=1;kx8
這種CRC的計算方法可用以下偽代碼表示:
Index=length_of_byte-1;
for(k=0;k
為了更充分地利用C64x+ DSP并行流水式處理的能力,并減少查找表的長度,可以進(jìn)一步對以上計算進(jìn)行優(yōu)化,每次循環(huán)處理32bit。相應(yīng)的查找表長度減少為原來的1/4。查找表的生成代碼如下:
crc_lut[0]=polynomial;
for(k=1;kx32
該方法的CRC計算可用以下偽代碼表示:
Index=length_of_word-1;
for(j=0;j
LutXn=crc_lut[Index--];
crc0=crc0^_gmpy(LutXn,data_byte[4*j]);
crc1=crc1^_gmpy(LutXn,data_byte[4*j+1]);
crc2=crc2^_gmpy(LutXn,data_byte[4*j+2]);
crc3=crc3^_gmpy(LutXn,data_byte[4*j+3]);
}
//crc0x24
crc0=_gmpy(crc0,0x100);
crc0=_gmpy(crc0,0x100);
crc0=_gmpy(crc0,0x100);
//crc1x16
crc1= _gmpy(crc1, 0x100);
crc1= _gmpy(crc1, 0x100);
//crc2x8
crc2=_gmpy(crc2,0x100);
crc=crc0^crc1^crc2^crc3;
上述基于GMPY和查找表的CRC優(yōu)化實現(xiàn),每次循環(huán)約需4個時鐘周期,而一次循環(huán)處理4字節(jié),所以每個字節(jié)的處理僅需約一個時鐘周期。
CRC是常用的檢錯機(jī)制,表1總結(jié)了幾種CRC的軟件實現(xiàn)方法在C64x+DSP上執(zhí)行的效率。

通過表1可以看出,在C64x+DSP上利用Galois域乘法指令極大地提高了CRC運算的效率。