
摘 要: 針對目前主題爬蟲采用“啟發(fā)式”搜索策略出現(xiàn)的“近視”缺點,提出了一種基于蟻群算法的主題爬蟲搜索策略。該方法將蟻群算法引入到主題爬蟲的搜索策略中,并對蟻群算法中信息素的更新計算進行了改進,使其具有一定的自適應(yīng)性。通過與其他搜索策略的比較實驗,結(jié)果表明該算法能夠更好地提高爬蟲的全局搜索能力。
關(guān)鍵詞: 主題爬蟲;蟻群算法;搜索策略;信息素
主題網(wǎng)絡(luò)爬蟲是根據(jù)一定的網(wǎng)頁分析算法,過濾與主題無關(guān)的鏈接,保留主題相關(guān)的鏈接并將其放入待抓取的超鏈接隊列中,然后根據(jù)一定的搜索策略從隊列中選擇下一步要抓取的網(wǎng)頁鏈接,并重復(fù)上述過程,直到達到系統(tǒng)的某一條件時停止。所有網(wǎng)絡(luò)爬蟲抓取的網(wǎng)頁將會被系統(tǒng)存儲,進行一定的分析、過濾,并建立索引[1]。相對于通用爬蟲,主題爬蟲搜索的內(nèi)容只限于特定主題或?qū)iT領(lǐng)域,因而被通用網(wǎng)絡(luò)爬蟲廣泛采用的基于廣度或深度優(yōu)先算法已不再適用。目前,主題網(wǎng)絡(luò)爬蟲通常采用啟發(fā)式搜索策略,每次選擇“最有價值”鏈接進行優(yōu)先訪問,但是這類策略容易過早陷入Web搜索空間中局部最優(yōu)子空間的陷阱,缺乏全局性,從而導(dǎo)致整體回報率不高[2]。
蟻群算法不僅能夠智能搜索和全局優(yōu)化,而且還具有魯棒性、正反饋、分布式計算、易于與其他算法結(jié)合等特點。利用正反饋原理,可以加快進化過程。分布式計算使該算法易于并行實現(xiàn),個體之間不斷進行信息交流和傳遞,有利于找到較好的解,不容易陷入局部最優(yōu)。易與多種啟發(fā)式算法結(jié)合,可改善算法的性能。穩(wěn)健性強,故在基本蟻群算法模型的基礎(chǔ)上進行修改,便可用于其他問題。
結(jié)合蟻群算法,本文針對主題爬蟲搜索策略上的不足,提出了一種基于蟻群算法的主題爬蟲搜索策略。由于對蟻群算法進行了改進,所以提出的算法還具有一定的自適應(yīng)性。
1 蟻群算法模型
蟻群算法是群集智能體現(xiàn)的一個典型例子,該算法是意大利學(xué)者Marco Dorigo[3]等人在1991年受螞蟻覓食行為的啟發(fā)而提出的。
蟻群算法借鑒和吸收了現(xiàn)實世界中蟻群的行為特征:螞蟻屬于群居昆蟲,個體行為極其簡單,而群體行為卻很復(fù)雜。相互協(xié)作的一群螞蟻很容易找到從蟻巢到食物源的最短路徑。此外,螞蟻還能夠適應(yīng)環(huán)境的變化,例如在蟻群的運動路線突然出現(xiàn)障礙物時,它們能夠很快地重新找到最優(yōu)路徑。螞蟻個體之間在覓食過程中通過信息素來進行信息傳遞,信息素隨著時間的推移會逐漸揮發(fā)。螞蟻在覓食過程中能夠感知信息素的存在及其強度,并以此來指導(dǎo)自己的運動方向,傾向于朝著信息素強度高的方向移動,即選擇該路徑的概率與當(dāng)時這條路徑上信息素強度成正比。信息素強度越高的路徑,選擇它的螞蟻就越多,則在該路徑上留下的信息素的強度就更大,而強度大的信息素又吸引更多的螞蟻,從而形成一種正反饋。通過這種反饋,使得大部分螞蟻都會走這個最佳路徑。
正反饋的副作用就是當(dāng)許多螞蟻都選中同一條路徑時,該路徑中的信息素量會迅速增大,從而使得多只螞蟻集中到某一條路徑上,造成一種堵塞和停滯現(xiàn)象,表現(xiàn)在使用蟻群算法解決問題時就容易導(dǎo)致早熟和局部收斂。
2 基于蟻群算法的搜索策略
2.1 算法思想
本文提出了一種基于蟻群算法的主題爬蟲搜索策略,其基本思想是:在Web頁面中存在超文本頁面wi和wj,如果wi中有一個鏈接指向wj,那么處于wi的螞蟻自身將根據(jù)一定的條件決定是否從wi移動到wj。每個鏈接序列代表了一個可能的螞蟻移動路線。螞蟻個體之間在移動過程中通過信息素來進行信息傳遞。信息素在螞蟻爬行過程中會隨著時間的推移逐漸揮發(fā)。螞蟻在頁面之間的爬行被分為多個循環(huán)周期,在每個周期中,一個螞蟻在Web頁面間進行一系列的移動,直到探尋到目標(biāo)資源并返回到源點為止。每完成一次爬行周期,蟻群對各路線上的信息素量進行更新。為解決蟻群算法的“早熟”和“局部收斂”問題,本文借鑒了參考文獻[4]中動態(tài)自適應(yīng)的調(diào)整信息素的思想。
假設(shè)V代表全體頁面集合,E代表由鏈接構(gòu)成的路徑集合,則Web頁面(鏈接)構(gòu)成有向圖G={V,E}。因為螞蟻在選擇下一個Web頁面時必須考慮其主題相關(guān)度,所以有向圖G中頁面Pk的主題相關(guān)度值可以參考PageRank算法公式。
為方便表述,作如下定義[5]:


其中c為常數(shù)。這樣,根據(jù)解的分布情況自適應(yīng)地進行信息素量的更新,從而動態(tài)地調(diào)整各路徑上的信息素量強度,使螞蟻既不過分集中也不過分分散,從而避免了早熟和局部收斂,提高全局搜索能力[5]。
2.3 算法流程
提出的基于蟻群算法的爬蟲搜索策略執(zhí)行過程如下:

2.4 算法參數(shù)分析
在蟻群算法的實現(xiàn)過程中,多個參數(shù)需要初始化設(shè)定。由蟻群算法的原理可知,不同參數(shù)的選擇能夠?qū)ο伻核惴ǖ男阅墚a(chǎn)生至關(guān)重要的影響[5]。目前對蟻群算法中參數(shù)的確定還沒有嚴(yán)格的理論基礎(chǔ),所以以上諸式中出現(xiàn)的參數(shù)ηij、α、β和ρ通常用試驗方法來確定其最優(yōu)組合。ηij表示由城市i轉(zhuǎn)移到城市j的期望程度,可根據(jù)某種啟發(fā)算法而定,例如可以取ηij=1/dij。α表示螞蟻在行進過程中所積累的信息素對它選擇路徑所起的作用程度。β是一個表示信息素重要程度的參數(shù)。信息激素的保留系數(shù)為ρ(0<ρ<1),它體現(xiàn)了信息素強度的持久性,而1-ρ則表示信息素的消逝程度。
參考文獻[6]通過大量的實驗數(shù)值分析表明,當(dāng)滿足0.01≤α≤0.3、3≤β≤6、0.1≤ρ≤0.3時,算法總體上有較好性能,達到的最優(yōu)解與全局最優(yōu)較接近,同時,所需的迭代次數(shù)也較少,不易陷入局部最優(yōu)而導(dǎo)致算法停滯。
3 實驗
3.1 實驗說明
為了驗證基于蟻群算法的主題爬蟲搜索策略比傳統(tǒng)的廣度優(yōu)先算法和基于最佳優(yōu)先搜索策略具有更好的全局搜索能力和自適應(yīng)性,本文在Nutch爬蟲的基礎(chǔ)上構(gòu)建了一個主題爬蟲。Nutch爬蟲具有可擴展和定制性。通過定義一個ACOCrawler插件來抓取特定主題的網(wǎng)頁[8]。實現(xiàn)以“物理教學(xué)資源”為主題,選取了國內(nèi)三個教育網(wǎng)站為種子集(如表1所示),算法參變量設(shè)定如表2所示。

3.2 結(jié)果分析
系統(tǒng)運行12個小時,共抓取3 360 000個網(wǎng)頁及資源。為了便于比較,分別對基于廣度優(yōu)先算法和最佳優(yōu)先搜索算法的搜索結(jié)果進行測試,統(tǒng)計三種搜索算法實現(xiàn)的爬蟲所搜索的關(guān)于物理教學(xué)資源的網(wǎng)頁及資源數(shù),采用“相對回報率”來評價爬蟲的性能。相對回報率R的計算公式為:

通過計算,可以得到三種算法性能比較圖,如圖1所示。
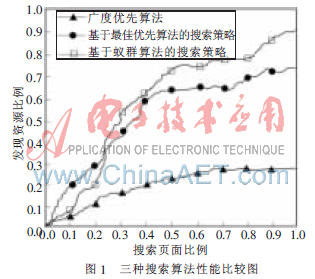
由圖1可以看出,在三種搜索策略中,廣度優(yōu)先算法的性能低于其他兩種“啟發(fā)式”算法。這兩種搜索策略在訪問了50%的頁面后,已經(jīng)找到了70%以上的相關(guān)物理資源,這表明基于“啟發(fā)式”搜索策略具有優(yōu)越性。
基于蟻群算法的搜索策略性能比較顯著,除了在搜索初期其發(fā)現(xiàn)能力略低于基于最佳優(yōu)先策略的搜索算法外,在其后的搜索中,新算法的性能明顯高于基于最佳優(yōu)先策略的搜索算法。其原因在于,基于蟻群算法的搜索策略采用了一種最優(yōu)選擇機制,一旦蟻群發(fā)現(xiàn)有好的全局最優(yōu)個體,動態(tài)地更新路徑上的信息素,作為最優(yōu)選擇路徑,從而避免了局部最優(yōu),因而整體回報率較高。
本文針對現(xiàn)有主題爬蟲所采用搜索策略出現(xiàn)的一些問題,將蟻群搜索模型引入主題爬蟲搜索策略。實驗結(jié)果表明,基于蟻群算法的搜索策略與基于廣度優(yōu)先搜索策略和基于最佳優(yōu)先搜索策略相比,其在主題相關(guān)性上有比較明顯的優(yōu)勢。通過對蟻群算法進行改進,能夠動態(tài)地調(diào)整信息素,從而也能夠較好地解決局部最優(yōu)問題,提高了全局搜索的能力。但由于蟻群算法本身的一些缺陷,使得主題爬蟲在搜索效率上還有待提高,這是下一步要做的工作。
參考文獻
[1] 劉金紅,陸余良.主題網(wǎng)絡(luò)爬蟲研究綜述[J].計算機應(yīng)用研究,2007(10):26-29.
[2] 李學(xué)勇,田立軍,譚義紅,等.一種基于非貪婪策略的網(wǎng)絡(luò)蜘蛛搜索算法[J].計算機與自動化,2004,23(2).
[3] DORIGO M, MANIEZZO V, COLORNI A. The ant system: optimization by a colony of cooperating agents[J]. IEEE Transactions on Systems, Man and Cybernetics—Part B, 1996, 26(1): 29-41.
[4] 李開榮,陳宏建,陳崚.一種動態(tài)自適應(yīng)蟻群算法[J].計算機與自動化,2004,40(29):149-152.
[5] 陶劍文.基于蟻群計算的自適應(yīng)Web檢索算法設(shè)計[J]. 計算機工程與應(yīng)用,2007(15):163-165.
[6] 蔣玲艷,張軍,鐘樹鴻.蟻群算法的參數(shù)分析[J].計算機工程與應(yīng)用,2006(13):31-35.
[7] MENCZER F, PANT G, SRINIVASAN N P. Topical Web crawler: evaluating adaptive algorithms[J]. ACM Transactions on Internet Technology, 2004(4): 378-419.
[8] 榮光,張化祥.一種DeepWeb爬蟲的設(shè)計與實現(xiàn)[J].計算機與現(xiàn)代化,2009(3):32-34.