
摘 要: 分析了Lucene的系統(tǒng)結(jié)構(gòu)及檢索原理,設(shè)計了一個基于Lucene的全文檢索系統(tǒng)模型,并將該系統(tǒng)模型應(yīng)用到自動答疑系統(tǒng)中進行實驗。實驗結(jié)果表明,以Lucene作為核心的檢索系統(tǒng)不僅建立索引的效率高,而且檢索速度也較快。
關(guān)鍵詞: Lucene;全文檢索;索引;搜索速度
隨著信息技術(shù)的快速發(fā)展,互聯(lián)網(wǎng)上的信息呈爆炸式增長,這種趨勢使得用戶在得到更多信息的同時,也不可避免地加劇用戶篩選信息的難度,為了使用戶在海量數(shù)據(jù)中能快速地找到有效數(shù)據(jù),高性能的信息檢索系統(tǒng)顯得越來越重要。
對海量數(shù)據(jù)檢索而言,全文檢索是唯一高效的解決方案。以前借助商業(yè)數(shù)據(jù)庫(如SQL Server)提供的全文檢索,由于其運行環(huán)境、效率或商業(yè)成本方面的原因無法滿足需求。現(xiàn)在一般通過Lucene將數(shù)據(jù)庫中的數(shù)據(jù)全部索引,然后提供查詢,進而實現(xiàn)對數(shù)據(jù)的全文檢索[1]。本文通過剖析開放源碼的全文檢索技術(shù)——Apache Lucene,構(gòu)建了一個基于Lucene的全文檢索系統(tǒng)模型,并結(jié)合Struts、Ajax等相關(guān)技術(shù),設(shè)計并實現(xiàn)了一個以Lucene作為核心的自動答疑系統(tǒng)。
1 Lucene全文檢索
Lucene是一個用Java語言實現(xiàn)、成熟、開源的軟件項目,是一個高性能、可擴展的信息檢索工具集,可以方便快捷地融入到應(yīng)用程序中,以增加索引和搜索功能。
1.1 Lucene的系統(tǒng)結(jié)構(gòu)
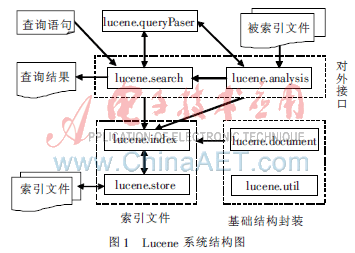
Lucene的系統(tǒng)結(jié)構(gòu)采用分層的方式構(gòu)建,各模塊間基于協(xié)議進行交互,形成了具有松耦合特征的體系結(jié)構(gòu),這大大增強了系統(tǒng)的彈性。Lucene系統(tǒng)主要由基礎(chǔ)結(jié)構(gòu)封裝、索引核心和對外接口三大部分組成,其結(jié)構(gòu)如圖1所示[2]。
從圖1可以看出,Lucene的源碼主要分為7個模塊,其核心類有3個,分別是:analysis、index和search。analysis主要用于切分詞,切分詞的具體工作由analyzer的擴展類來實現(xiàn);index主要提供庫的讀寫接口,通過它可以創(chuàng)建庫、添加刪除記錄以及讀取記錄等;search主要提供檢索接口,通過該包可以輸入條件并得到查詢結(jié)果集,與queryPaser包配合還可以自定義查詢規(guī)則。
1.2 Lucene檢索原理
Lucene的檢索算法屬于索引檢索,即用空間來換取時間,對需要檢索的文件或字符流進行全文索引,在檢索的時候?qū)λ饕M行快速搜索,得到檢索位置,該位置記錄了檢索詞出現(xiàn)的文件路徑或者某個關(guān)鍵詞。實際上,Lucene的檢索過程是將模糊查詢變成多個利用索引進行精確查詢的邏輯組合過程。并且,Lucene的API接口設(shè)計比較通用,很多傳統(tǒng)應(yīng)用的文件、數(shù)據(jù)庫等都可以方便地映射到Lucene的存儲結(jié)構(gòu)/接口中。因此,在一定程度上可以把Lucene看著一個支持全文索引的數(shù)據(jù)庫系統(tǒng),其檢索原理如圖2所示[3]。

2 系統(tǒng)模型
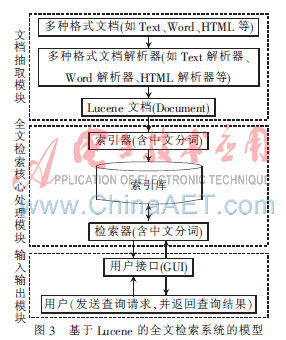
根據(jù)開源Lucene的相關(guān)理論知識(如檢索原理),構(gòu)建了一個通用、易于擴展、基于Lucene的全文檢索系統(tǒng)模型,具體模型如圖3所示。該模型主要包括的功能模塊有文檔抽取模塊、全文檢索核心處理模塊和輸入輸出模塊。其中,全文檢索核心處理模塊是模型中最重要的模塊[4]。
由圖3可知,基于Lucene的全文檢索系統(tǒng)處理的數(shù)據(jù)源可以是一些常見的文檔格式,如Text、Word以及HTML等,系統(tǒng)首先通過文檔解析器提取出這些文檔的原始數(shù)據(jù)信息并保存為Lucene能夠處理的文檔類型(Document),然后Lucene的索引器將接收這些文檔,并對其內(nèi)容進行分析,最后提取索引項并生成索引庫。然后以索引庫為基礎(chǔ),可以設(shè)計滿足各種查詢需求的檢索器和符合用戶使用特點的可視化個性操作界面,并將查詢結(jié)果展現(xiàn)給用戶。
3 模型應(yīng)用
在遠程網(wǎng)絡(luò)教育中,若能對以前所提的問題和已經(jīng)回答過的答案進行全文檢索,用戶便可以在系統(tǒng)中找到自己需要的答案,實現(xiàn)自動答疑的目的。
3.1 系統(tǒng)設(shè)計
根據(jù)前面設(shè)計的Lucene全文檢索系統(tǒng)模型,采用Struts框架作為系統(tǒng)的整體基礎(chǔ)架構(gòu),并運用Ajax對Struts在表示層上的補充[5],設(shè)計并開發(fā)一個自動答疑系統(tǒng),該自動答疑系統(tǒng)的總體設(shè)計如圖4所示。
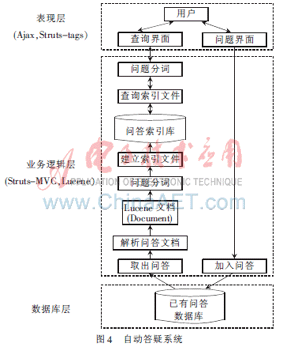
從圖4可以看出,該自動答疑系統(tǒng)采用表現(xiàn)層、業(yè)務(wù)邏輯層和數(shù)據(jù)庫層的三層結(jié)構(gòu)設(shè)計模式。其中,表現(xiàn)層為用戶界面,它為用戶提供交互接口,主要包括查詢界面和問答添加界面,并采用Struts-tags和Ajax技術(shù)來實現(xiàn),通過Ajax技術(shù)可以實現(xiàn)按需取數(shù)據(jù)、局部更新頁面的功能,從而增強了用戶體驗[6]。業(yè)務(wù)邏輯層主要完成問答的全文檢索功能,具體包括在查詢問題時檢索索引庫和從關(guān)系數(shù)據(jù)庫取出問答并向索引庫中添加索引文件,主要采用Struts和Lucene技術(shù)來完成。其中,Struts是一個優(yōu)秀的基于MVC(Model View Controller)模式的開源框架,它通過控制器將表示邏輯和業(yè)務(wù)邏輯解耦。數(shù)據(jù)庫層完成問題收集功能,對提出的問題和相應(yīng)的答案添加到數(shù)據(jù)庫中,使用MySQL來保存所有問答,或直接存放在硬盤目錄上。
3.2 關(guān)鍵技術(shù)
實現(xiàn)該自動答疑系統(tǒng)的關(guān)鍵技術(shù)主要集中在中文分詞、索引管理和結(jié)果排序三方面。
(1)中文分詞
在Lucene中執(zhí)行分詞任務(wù)的是Analyzer對象,該對象中最關(guān)鍵的方法是TokenStream方法,通過執(zhí)行該方法可以返回一個包含token的集合,也即TokenStream對象。TokenStream本身是一個有著類似迭代器接口的抽象類,其具體類有兩種:一種是以Reader對象作為輸入的Tokenizer對象,另一種是以另一個TokenStream對象作為輸入的TokenFilter。因此在該自動答疑系統(tǒng)中,問題分詞采用Lucene Analyzer分詞器來實現(xiàn),即首先創(chuàng)建自己的Analyzer對象,以及與其相關(guān)的Tokenizer和TokenFilter,然后通過這幾個類的有機配合進而實現(xiàn)問題的中文分詞。
(2)索引管理
從根本上說,索引管理主要包括兩方面內(nèi)容:建立索引和基于索引進行的檢索。
建立索引是對文本內(nèi)容切分詞后索引入庫。切分后的token通過Lucene.index索引器的處理最終添加到索引庫中,Lucene.store存儲器負責數(shù)據(jù)存儲管理,主要包括一些底層的I/O操作。核心代碼如下:
Analyzer luceneAnalyzer=new StandardAnalyzer();
IndexWriter indexWriter=new IndexWriter(indexDir,luceneAnalyzer,true);
indexWriter.addDocument(document);
檢索是在建立好的索引上進行的搜索,并根據(jù)查詢條件返回結(jié)果。其核心代碼如下:
QueryParser queryParser=new QueryParser(field,new StandardAnalyzer());
Query luceneQuery=queryParser.parse(QueryString);
IndexSearcher indexSearcher=new IndexSearcher(IndexReader.open(indexDir));
Hits hits=indexSearcher.search(luceneQuery);(hits用來保存檢索結(jié)果集的對象)
(3)結(jié)果排序
排序的基本原則是盡可能地把對用戶更有價值的問題排在前面而不影響性能。Lucene是按照自己的相關(guān)度算法(score)對結(jié)果進行排序的,除了匹配score外,還可以用索引記錄的ID來進行排序,所以較為高效的排序方法是:在索引時,讓進入Lucene全文的順序?qū)?yīng)著一定的規(guī)則(如用戶對問答的評價值越高反映該問題的價值越高),而在檢索時讓檢索結(jié)果按照索引記錄的ID進行倒排文檔(invert document)。
3.3 實驗結(jié)果
本實驗的硬件環(huán)境為處理器:Intel Pentium 4 CPU 3.20 GHz(2 CPUs),內(nèi)存:三星DDR2 1 GB,硬盤:酷睿 120 GB等;軟件環(huán)境為JKD 1.6,Eclipse 3.2,MyEclipse 6.5,Tomcat 6.0,MySQL 5.0等。實驗時使用所設(shè)計的自動答疑系統(tǒng),不僅對存儲在關(guān)系數(shù)據(jù)庫和存放在硬盤目錄上不同大小的問答文本文件建立索引所花費時間進行對比,而且還對關(guān)系數(shù)據(jù)庫和索引庫中的問答文件進行檢索所需的時間進行比較,具體實驗結(jié)果如表1所示。

從表1可以看出,同樣采用Lucene作為檢索系統(tǒng)的核心,數(shù)據(jù)源同為文本文件時,對硬盤文件目錄建立的索引的效率要比對關(guān)系數(shù)據(jù)庫建立索引的效率要高,對索引庫中的文件檢索速度比對關(guān)系數(shù)據(jù)庫中文件檢索速度要快,并且隨著數(shù)據(jù)源的增大,效果越來越明顯,實驗結(jié)果基本符合理論要求。
Lucene是當前比較成熟的檢索技術(shù),利用它可以方便地實現(xiàn)全文檢索。本文在剖析Lucene相關(guān)技術(shù)的基礎(chǔ)上,構(gòu)建了一個基于Lucene的全文檢索系統(tǒng)模型,并將該模型應(yīng)用到一個具體實例——自動答疑系統(tǒng)中進行實驗,實驗結(jié)果表明,以Lucene為核心的檢索系統(tǒng)不僅建立索引的效率高,而且檢索速度也較快。
參考文獻
[1] 郎小偉,王申康.基于Lucene的全文檢索系統(tǒng)的研究與開發(fā)[J].計算機工程,2006,4(2):95-99.
[2] 李晶,文登敏.基于Lucene的全文檢索引擎的研究與應(yīng)用[J].淮陰工學院學報,2008(2):57-59.
[3] 劉建湘,楊文濤.基于Lucene的搜索引擎在Struts中的應(yīng)用[J].軟件導刊,2007(2):53-54.
[4] 吳青,夏紅霞.基于Lucene的全文檢索引擎的應(yīng)用與改進[J].武漢理工大學學報,2008,7(30):145-147.
[5] 孫曉峰.基于輕量級框架的互動問答平臺的設(shè)計與實現(xiàn)[D].北京:中國地質(zhì)大學,2008(5):13-23.
[6] 諶湘倩,狄文輝.基于SSH框架與AJAX技術(shù)的Java Web應(yīng)用開發(fā)[J].計算機工程與設(shè)計,2009,30(10):2590-2592.