
摘 要: 提出一種人體行為識別模型和前景提取方法。針對人體運動過程中產(chǎn)生新的行為問題,該模型用分層Dirichlet過程聚類人體特征數(shù)據(jù)來判斷人體運動過程中是否有未知的人體行為模式;用無限隱Markov模型對含有未知行為模式的特征向量進行行為模式的有監(jiān)督的學習,由管理者將其添加到規(guī)則與知識庫中。當知識庫的行為模式達到一定規(guī)模時,系統(tǒng)便可以無監(jiān)督地對人體行為進行分析,其分析采用Markov模型中高效的Viterbi解碼算法來完成。對于前景的提取,提出了基于背景邊緣模型與背景模型相結合的前景檢測方法,此方法能夠有效避免光照、陰影等外部因素的影響。仿真實驗證明,本文提出的方法在實時視頻監(jiān)控中的人體行為識別方面有獨特的優(yōu)勢。
關鍵詞: 行為模式;嵌套的狄利克雷過程;無限隱Markov模型;行為識別
人的行為理解與描述是近年來被廣泛關注的研究熱點,它是指對人的運動模式進行分析和識別,并用自然語言等加以描述。行為理解可以簡單地被認為是時變數(shù)據(jù)的分類問題,即將測試序列與預先標定的代表典型行為的參考序列進行匹配。對于人的行為識別,參考文獻[1]概括為以下兩種方法:
(1)模板匹配方法。參考文獻[2-5]都采用模板匹配技術的行為識別方法。首先將圖像序列轉換為一組靜態(tài)形狀模式,然后在識別過程中和預先存儲的行為標本來解釋圖像序列中人的運動。
(2)空間方法。基于狀態(tài)空間模型的方法定義每個靜態(tài)姿勢作為一個狀態(tài),這些狀態(tài)之間通過某種概率聯(lián)系起來。目前,狀態(tài)空間模型已經(jīng)被廣泛地應用于時間序列的預測、估計和檢測,最有代表性的是HMMs。每個狀態(tài)中可用于識別的特征包括點、線或二維小區(qū)域。
本文從兩個方面來闡述視頻監(jiān)控系統(tǒng)中的人體行為識別:(1)行為描述,即在視頻幀中提取人體特征,并對人體行為進行描述;(2)行為識別,通過基于數(shù)理統(tǒng)計的Markov模型訓練得到的行為檢測器來實現(xiàn)。針對行為描述,本文采用背景邊緣法來提取視頻前景,通過背景邊緣法來獲取人體的邊界輪廓,背景法可獲取前景人體區(qū)域。由于背景法受光照影響較大,通過這種方法提取的人體區(qū)域不夠完整,但通過人體邊界和人體區(qū)域相加,再進行形態(tài)學的閉運算,就能得到較完整的前景目標。對于行為識別,首先利用HDP-iHMM進行人體行為狀態(tài)的確定,即確定是否有新的人體行為模式產(chǎn)生,如果有新的行為狀態(tài),則進行iHMM的行為模式的學習;如果沒有新的行為狀態(tài),則用已訓練的HMM進行行為檢測。
本文的創(chuàng)新點是在人體前景獲取的過程中利用了兩種背景模型的結合。在行為檢測方面,應用HDP-iHMM確定是否有未知人體行為,利用HMM來進行行為的檢測,這樣能使檢測系統(tǒng)不斷地學習,當知識庫的行為模式達到一定規(guī)模時,系統(tǒng)便可以無監(jiān)督地對人體行為進行檢測。
1 人體行為描述
參考文獻[2]、[6]為了理解人體行為,采用最常用的背景減除法來提取運動的人體,利用當前圖像與背景圖像的差分來檢測出前景運動區(qū)域的一種技術,但這種方法對光照和外來無關事件的干擾等特別敏感。為了解決這個問題,本文采用背景邊界模型和背景模型的結合來檢測前景,通過這兩種模型的結合,再應用形態(tài)學運算,就能獲得一個相對較完整的人體前景。
1.1 人體前景提取
背景邊緣模型通過統(tǒng)計視頻圖像中每個位置在連續(xù)時間內(nèi)出現(xiàn)邊緣的概率計算得到:

(3)通過一些數(shù)學運算結合兩種模型獲取f(x,y),然后對f(x,y)進行形態(tài)學運算,來填充前景孔洞,為特征計算奠定基礎。
1.2 特征計算
在提取了前景后,為了分析人的活動和行為模式,進一步提取和計算一些人體特征數(shù),本文的研究著重于以下圖像特征值:
(1)長寬比(A):A=L/W,A值包含了行為模式識別的重要信息。這一特征可以識別人體是站立或是別的姿勢。
(2)矩形度(R):R=A0/AR,其中A0是人體的面積,AR是最小封閉矩形的面積。矩形擬合因子的值限定在0和1之間。
(3)協(xié)方差矩陣(C):

2 行為的識別模型
對未知行為的學習過程如圖1所示。當HDP聚類過程中發(fā)現(xiàn)有新行為產(chǎn)生時,則用iHMM的Beam抽樣算法學習未知行為模式,將定性的行為模式添加到規(guī)則和知識庫。



該多層模型的對應圖形化表示如圖2所示。在本文中,βk′為轉移到狀態(tài)k′的轉換概率的先驗均值,α為控制針對先驗均值的可變性。如果固定β=(1/k,…,1/k,0,0…),本文K個條目的值為l/k,而其余為0;當且僅當k′∈{1,…,K}時,達到狀態(tài)k′的轉換概率為非零。

3 系統(tǒng)仿真實驗
3.1 未知行為模式的定性
(1)設初始行為狀態(tài)為4個,然后進行抽樣獲取訓練HDP-iHMM模型的樣本,對模型進行訓練,同時對樣本進行聚類,可得到如圖3(a)的聚類圖,模型狀態(tài)轉移矩陣如圖4(a)所示,模型觀察值轉移矩陣如圖4(d)。


(2)獲取一個檢測樣本,通過已經(jīng)訓練好的模型來驗證模型的有效性。將包含5個狀態(tài)的樣本進行檢測,會發(fā)現(xiàn)有一種新的行為,系統(tǒng)提示需要進行知識庫更新。將這種新產(chǎn)生的行為進行定義后添加到知識庫中,并用這個樣本作為訓練樣本來訓練一個與此行為相對應的模型,將訓練結果保存到知識庫中,同時對樣本進行聚類,可得到如圖3(b)所示的聚類圖,模型狀態(tài)裝轉移矩陣如圖4(b),模型觀察值轉移矩陣如圖4(e)。由圖可看出,行為狀態(tài)增加了1個,由4個變成5個。最后,用包含狀態(tài)5和狀態(tài)6的樣本進行檢測,同樣,系統(tǒng)就會有新的行為的提示信息。重復上述過程,可得到如圖3(c)所示的聚類圖,模型狀態(tài)轉移矩陣如圖4(c)所示,模型觀察值轉移矩陣如圖4(f)所示。由圖4可看出,狀態(tài)又增加了1個,由5個變成6個。
通過聚類圖可看出,能將代表新的人體行為特征向量聚為一類,圖3中的虛線橢圓表示一個新的聚類,從最初的4類到新增一類后的5類和新增兩類后的6類。
以上描述了HDP-iHMM在識別未知行為方面的有效性,通過iHMM可以對未知行為進行確定和描述,為行為檢測和預測做好準備。在本仿真統(tǒng)中,本文用HDP-iHMM確定未知行為,在事件數(shù)目確定后,用HMM實現(xiàn)行為的識別。通過iHMM和HMM的結合,增加了行為識別的主動性和智能性。
3.2 行為識別
3.2.1 前景獲取
背景邊緣模型是記錄背景模型的邊緣像素位置信息,通過背景邊緣圖與當前視頻幀的邊緣圖像在相同位置像素的比較來判斷該位置的像素點是否為前景目標像素點。通過與背景檢測的比較,驗證本文方法的優(yōu)點,這種前景幀判斷方法相對于其他常見的前景判斷方法不但簡單而且魯棒性好,圖5給出了兩種方法的比較實例。從圖中可以看出,由于受光照和陰影等因素的影響,背景法因為光照的突變使得檢測結果為整個畫面,不太理想。而本文的方法則受光線的變化影響較小。由此可見,對于前景檢測,本方法能夠很好地避免光照和人體陰影的影響,能夠較好地檢測前景目標。

3.2.2 模型的學習和行為識別
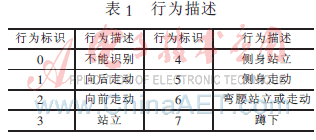
對系統(tǒng)行為識別能力的實驗以視頻監(jiān)控中人體行為的識別為例。首先通過iHMM對未知行為模式進行定性和描述。表1為系統(tǒng)已經(jīng)能識別的行為描述,讓人體特征數(shù)據(jù)通過本文的識別系統(tǒng),識別系統(tǒng)將會返回一個行為標識,通過行為標識索取行為描述。
對于本文仿真實驗,采用的訓練樣本就是獲取的人體特征向量。以“站立”、“側身走動”和“蹲下”所對應的特征向量為訓練樣本,分別用S1、S2、S3表示來說明模型的訓練過程。訓練的收斂誤差用聯(lián)合相關性的穩(wěn)定性來衡量,收斂誤差根據(jù)收斂的精確度而定。訓練過程中隨著迭代次數(shù)的增加,最大似然估計值的對數(shù)值也在不斷地增加,直到達到收斂誤差為止。由于訓練樣本的差異,聯(lián)合相關性穩(wěn)定在不同的迭代次數(shù)之后。但從圖6中可以看出,每個訓練樣本都達到了收斂。

模型對視頻監(jiān)控中人體行為的識別能力,HMM通過搜索最佳狀態(tài)序列,以最大后驗概率為準則來找到識別結果。在本系統(tǒng)中采用25幀/s的視頻輸入,來分析視頻序列中人體的行為,同時驗證本文識別系統(tǒng)的識別準確率。圖7為對人體“站立”行為的識別,圖8為對人體“蹲下”行為的識別。從圖中可以看出,采用的基于統(tǒng)計學的行為識別模型能夠很好地識別不同時刻人的同一行為。

在整個小男孩的行為識別過程中,由于存在許多相關因素的影響,會出現(xiàn)識別錯誤的情況。本文在整個跟蹤過程中統(tǒng)計了跟識別錯誤率,其結果如圖9所示。從圖9可以看出,隨著跟蹤處理幀數(shù)的增加,跟蹤錯誤率總圍繞某一值上下波動,本文統(tǒng)計跟蹤錯誤率大約是18%。
從時間復雜度方面考慮,整個系統(tǒng)包括兩個部分:(1)離線的未知行為確定和行為模式學習系統(tǒng);(2)在線的行為識別系統(tǒng)。對于在線系統(tǒng),其行為識別算法采用應用比較廣泛的Viterbi算法。因為利用全概率公式雖然可以計算系統(tǒng)的輸出概率,但無法找到一條最佳的狀態(tài)轉移路徑。而Viterbi算法,不僅可找到一條足夠好的轉移路徑,而且可得到該路徑對應的輸出概率。同時,Viterbi算法計算輸出概率所需要的計算量要比全概率公式的計算量小很多。這些可以說明本文的行為識別系統(tǒng)實時性較好,識別算法時間復雜度小。對于離線系統(tǒng),仿真試驗已經(jīng)驗證了對未知行為的確定能力和行為模式的學習能力,而且離線系統(tǒng)對實時性要求較低。
本文的重點是對視頻流中人體行為識別的研究,這是計算機視覺中一個重要的研究領域之一。仿真實驗演示了視頻監(jiān)控中人體行為識別的全過程,提出了用背景邊緣模型來提取前景圖像,從仿真實驗可看出此方法有較好的提取效果,而且能夠有效避免光照和陰影等外部因素的影響。此外,在行為識別方面,應用NDP_iHMM來確定行為狀態(tài)數(shù),在狀態(tài)數(shù)確定以后將無限iHMM變成有限HMM,這樣提高了系統(tǒng)的普適性,通過iHMM與HMM結合,解決了在系統(tǒng)行為狀態(tài)可變情況下的人體行為識別問題。
參考文獻
[1] 王亮,胡衛(wèi)明,譚鐵牛.人運動的視覺分析綜述[J].計算機學報,2005,25(3).
[2] CUI Y, WENG J. Hand segmentation using learning-based prediction and verification for hand sign recognition[C]. Proceedinys of IEEE Conference on Computer Vision and Pattern Recognition, Puerto Rico, 1997: 88-93.
[3] POLANA R, NELSON R. Low level recognition of human motion[C]. Proceedinys of IEEE Workshop on Motion of Non-Rigid and Articulated Objects, Austin, TX, 1994: 77-82.
[4] BOBICK A, DAVIS J. Real-time recognition of activity using temporal templates[C]. Proceedinys of IEEE Workshop on Applications of Computer Vision, Sarasota, Florida, 1996: 39-42.
[5] DAVIS J, BOBICK A. The representation and recognition of action using temporal templates[R]. MIT Media Lab, Perceptual Computing Group, Technical report: 1997: 402.
[6] XIANG Tao, GONG Shao Gang . Video behavior profiling for anomaly detection[J]. IEEE Transactions On Pattern Analysis and Machine Intelligence, 2008, 30(5):893-908.